32. Travaux pratiques : configuration d’un système de messagerie
32.1. Installation de postfix
32.2. DNS – préparation préalable
32.3. Configuration du serveur postifx.
32.3.1. Installation du serveur SMTP
32.3.2. Test de la configuration du serveur SMTP
32.3.3. Installation du serveur PostOFFICE Pop3
32.3.4. Test du serveur Pop3
32.3.5. Utilisation des alias
32.3.6. Utilisation des listes
32.3.7. La gestion des erreurs
32.3.8. Mise en place du service IMAP sur le serveur
32.3.9. Plus loin dans le décryptage
32.3.10. Mise en place du client IMAP
32.3.11. Le relayage
32.3.12. Autres techniques de filtrage et autres services de postfix
33. Installation d’un serveur DDNS avec bind et DHCP
33.1. Résumé
33.2. Éléments sur le service DDNS
33.3. Les aspects sur la sécurité
34. Travaux pratiques : DDNS
34.1. Réalisation
34.2. Les fichiers de configuration
34.2.1. Le fichier named.conf
34.2.2. Le fichier de zone directe
34.2.3. Le fichier de zone in-addr.arpa
34.2.4. Le fichier rndc.conf
34.2.5. Le fichier de clé partagée
34.2.6. Le fichier dhcpd.conf
34.3. Procédure de tests des services
34.4. Intégration des services
34.5. Générer un nom dynamiquement pour les clients DHCP
35. Installation d’un service Web-mail
35.1. Présentation
35.2. Architecture générale du service
35.3. Installation et configuration OpenWebmail
35.3.1. Préparation de la machine
35.3.2. Installation d’OpenWebmail
35.3.3. Configuration de l’application OpenWebmail
35.3.4. Test de l’environnement
35.3.5. Configuration de l’environnement utilisateur
35.3.6. Test et environnement OpenWebmail
35.4. Application
36. Installation d’un service mandataire (Proxy SQUID)
36.1. Installer Squid
36.2. Configuration de squid
36.3. Initialisation de Squid
36.4. Les options de démarrage de Squid
36.5. Contrôler les accès
36.6. Contrôler les accès par authentification
36.7. Interface web de Squid et produits complémentaires
36.8. La journalisation
36.9. Configurer les clients
36.10. Forcer le passage par Squid (Proxy transparent)
36.11. Le redirecteur SquidGuard
36.12. Les applications non prises en charge par un service proxy
37. Travaux pratiques : installation de SQUID
37.1. Application
37.1.1. Préparation de la maquette
37.1.2. Installation et configuration du service proxy
37.1.3. Configuration du client
37.1.4. Mise en place d’une ACL simple
37.1.5. Utilisation de fichiers pour stocker les règles des ACL
37.1.6. Configuration des messages d’erreurs
37.1.7. Automatisation de la configuration des clients.
37.1.8. Installation et configuration du service proxy Squid transparent.
37.1.9. Mise en place de l’authentification
37.2. Liens
37.3. Annexes
37.3.1. Fichier squid.conf – testé avec Squid 2.5
37.3.2. Exemples d’ACLs Squid 2.2
37.3.3. ACL par authentification Squid 2.2
37.3.4. ACL sur des plages horaires Squid 2.2
38. Installation d’un serveur PostgreSQL avec Apache
38.1. Avant de démarrer
38.2. Les ressources sur PostgreSQL
38.3. Accès aux archives
38.4. Présentation
38.5. Présentation de PostgreSQL
38.5.1. Mode de fonctionnement de PostgreSQL
38.5.2. Langage de commande pour PostgreSQL
38.6. Présentation de PHP
38.6.1. Mode de fonctionnement de PHP
38.6.2. Le langage PHP
38.7. Dialogue client et serveurs PHP, Apache et PostgreSQL
38.8. Exemple de code
39. Travaux pratiques : PostgreSQL
39.1. Présentation
39.2. PostgreSQL
39.3. Test de la base
39.4. Serveur Apache et PHP
39.5. Serveur PostgreSQL/Apache et PHP
39.6. TP de synthèse
40. Surveillance, continuité de service
40.1. Principe de fonctionnement
40.2. Le matériel
40.2.1. Assurer la surveillance entre machines du cluster
40.3. Le logiciel
40.3.1. les pré-requis
40.3.2. L’installation
40.3.3. les fichiers de configuration
40.3.4. Mise en route
40.4. Exercices
41. Lilo : Linux Loader
41.1. Objectifs
41.2. Présentation de Lilo
41.2.1. Lilo
41.3. Documentation
41.4. Avant de commencer
41.4.1. Linux SGF
41.4.2. Les partitions
41.4.3. Disque IDE ou EIDE
41.4.4. Disques E(i)DE et CDROM
41.4.5. Disques E(i)DE et SCSI
41.4.6. Disques SCSI
41.4.7. Restriction du BIOS
41.5. Installation
41.5.1. MBR et PBR
41.5.2. Installer Lilo
41.5.3. Dos ou Windows 9.x
41.5.4. Windows NT
41.5.5. Exemple avec 3 systèmes
41.5.6. Avec d’autres systèmes
41.6. Lilo
41.6.1. Exécution de Lilo
41.6.2. Options de configuration
41.6.3. Outils de configuration
41.6.4. Exemple de fichier de configuration /etc/lilo.conf
41.6.5. Désinstaller Lilo
41.7. Choix du système
41.8. Autres solutions sans Lilo
41.8.1. Loadlin
41.9. rdev
41.10. initrd
41.10.1. Modules
41.10.2. initrd (suite)
41.11. Conclusion
42. Travaux pratiques : Kernel et Noyau
42.1. Objectifs
42.2. Quelques remarques
42.3. Compilation
42.4. Installation et activation de module
42.4.1. make-kpkg pour les modules
42.5. Utilisation de Grub
42.6. Librairies
43. Init : Initialisation du système sous Linux
43.1. Documentation
43.2. 5 phases:
43.3. Premières explications:
43.4. Le processus de BOOT
43.5. Lilo
43.6. Init
43.6.1. Le répertoire /etc/rc.d
43.6.2. Séquences du programme init
43.6.3. Le niveaux d’exécution (runlevels)
43.6.4. Le niveau d’exécution par défaut
43.7. Le fichier /etc/inittab
43.8. Contenu d’un répertoire rcx.d
43.9. Comment choisir un mode d’exécution
43.10. Utilitaires de configuration
43.11. Arrêter ou démarrer un service
43.12. Ajout ou suppression d’un service
43.13. Placer une commande au démarrage du système
43.14. Arrêt du système
43.15. La commande shutdown
43.16. La disquette de BOOT
43.16.1. Création des disquettes
43.17. Dépannage
43.17.1. Mot de passe de root oublié
43.17.2. Démarrer en « single user »
43.18. Conclusion
44. TP : Sytème de gestion de fichiers
44.1. Swap
44.2. ext
44.3. loop
44.3.1. Alternative permettant de choisir le device loop
44.3.2. loop encrypté
44.3.3. loop iso9660
44.3.4. Fin du TP
45. CVS : Concurrent Version System
45.2. Horloge
45.3. Le dépôt (repository)
45.3.1. Initialisation du dépôt
45.3.2. Configuration
45.3.3. Accès au dépôt
45.3.4. Modules
45.4. Les commandes principales de CVS
46. Travaux pratiques : Concurrent Version System
46.1. Objectifs
46.2. Installer et configurer CVS
46.3. Gestion d’un projet en mode non connecté
46.4. Gestion d’un projet en mode connecté
47. L’annuaire LDAP
47.1. Introduction
47.2. Présentation de LDAP
47.2.1. Le protocole
47.2.2. Le modèle de données
47.2.3. Les méthodes d’accès
47.2.4. Le langage de commande
47.3. Concevoir un annuaire
47.3.1. Déterminer les besoins, les données, le schéma
47.4. Créer une base de données
47.5. Installer, configurer et Administrer LDAP
47.5.1. Installer les packages sur le serveur
47.5.2. Les fichiers de configuration du serveur
47.6. Ressources
48. TP 1- Installer, configurer et Administrer LDAP
48.1. Installer les packages sur le serveur
48.2. Les fichiers de configuration du serveur
49. Installation d’un annuaire LDAP et utilisation du langage de commande
49.1. Environnement
49.1.1. Configuration du fichier slapd.conf
49.1.2. Création de l’annuaire
49.1.3. Création de l’annuaire
49.1.4. Enrichissement de l’annuaire
49.1.5. Le langage de commande
50. L’annuaire LDAP
50.1. Authentification système LDAP sur un système GNU/Linux
50.1.1. Configuration de l’environnement pour l’authentification système
50.1.2. Premiers tests de l’annuaire
50.1.3. Vérification du fonctionnement de l’annuaire.
50.1.4. Mise en place de l’authentification
51. L’annuaire LDAP avec PHP
51.1. Utilisation de PHP avec LDAP
51.1.1. Les principales fonctions
51.1.2. Accès anonyme pour une recherche
51.1.3. Accès authentifié pour une recherche
52. Annexes à la séquence sur LDAP
52.1. Exemple de fichier LDIF
52.2. L’annuaire ldap vu de konqueror
52.3. L’annuaire ldap vu de gq
52.4. Le schéma vu de gq
52.5. Authentification avec php sur LDAP
53. Planification prévisionnelle des séquences LDAP
53.1. Prévision des séquences
54. Synchroniser ses machines avec NTP
54.1. Introduction à ntpdate et ntpd
54.2. ntpdate
54.2.1. Installation de ntpdate
54.2.2. Configuration de ntpdate
54.3. ntpd
54.3.1. Installation de ntpd
54.3.2. Configuration de ntpd
54.4. Conclusion
54.5. Liens utiles
55. Eléments de cours sur le routage et le filtrage de paquets IP
55.1. Routage, Filtrage sur les paquets IP
55.2. Technique de masquage et de traduction d’adresse
55.3. Masquerading et Forwarding
56. ICMP
56.1. ICMP et le filtrage de paquets
57. Ipchains
57.1. Langage d’Ipchains
58. Iptables
58.1. Langage d’Iptables
58.2. Exemples d’utilisation d’iptables
58.3. La traduction d’adresse – NAT
58.3.1. Le DNAT ou NAT Destination
58.3.2. Le SNAT ou NAT Source
58.3.3. L’IP Masquerade
58.3.4. Exemple sur un réseau privé
59. Application sur le routage et le filtrage de paquets IP
59.1. Introduction
59.2. Fonctions de filtrage
59.3. TD
59.4. Schéma de la maquette pour le TP
59.4.1. Première partie : installation et configuration du routage
59.4.2. Règles de filtrage simples
59.4.3. Règles de filtrage par adresse, port et protocoles
60. Outils et ressources complémentaires pour les TP
60.1. Iptraf
60.2. Documentations complémentaires
61. Initiation au routage
61.1. Initiation au routage
61.1.1. Les principes du routage
61.1.2. Place à la pratique
61.1.3. Conclusion
62. Le routage dynamique avec RIP
62.1. Introduction
62.1.1. Pourquoi le routage dynamique ?
62.1.2. Le protocole RIP
62.1.3. Place à la pratique
62.1.4. Conclusion
63. Le routage dynamique avec OSPF
63.1. Introduction
63.1.1. Rappels sur les éléments vus
63.1.2. Les grands principes
63.1.3. Le fonctionnement d’OSPF un peu plus en détail
63.1.4. Place à la pratique
63.1.5. Conclusion
64. Le routage dynamique avec BGP
64.1. Introduction
64.1.1. Les grands principes
64.1.2. Place à la pratique
64.1.3. Cohabitation entre BGP et les IGP
64.1.4. Conclusion
65. TP sur le routage statique avec Zebra
65.1. Introduction
65.1.1. Présentation des concepts importants
65.1.2. Architecture de Zebra
65.1.3. Topologie de travail
65.1.4. Mise en place
65.1.5. Démarrage du démon zebra
65.1.6. Connexion au démon zebra
65.1.7. Prise en main de Zebra (principe)
65.1.8. Prise en main de Zebra (mise en pratique)
65.1.9. Problèmes rencontrés
66. Multi-router looking glass
66.1. Présentation
67. Annexe sur le langage de commande de Zebra
67.1. Annexe sur le langage de commande de Zebra
68. Concepts généraux sur le routage
68.1. Présentation
68.2. Jargon réseau sur le routage
68.2.1. Notion de système autonome (SA)
68.2.2. Choix d’une route et métrique
68.3. Les protocoles de routages IGP’s
68.3.1. Les algorithmes Vector-Distance
68.3.2. Algorithme Link State (État de Liens)
68.3.3. Les techniques hybrides
68.4. Les protocoles de routages extérieurs EGP
69. Remerciements et licence
69.1. Copyright
Chapter 32. Travaux pratiques : configuration d’un système de messagerie
Les protocoles SMTP, POP et IMAP – TP
Les protocoles SMTP, POP et IMAP – TP
Comment installer un serveur SMTP, un client IMAP et un client POP3
Vous allez installer successivement :
- le serveur de messagerie postifx puis tester son fonctionnement,
- un serveur de remise de courrier pop3 et imap
- un client pop3 et imap puis tester son fonctionnement,
Pour imap on utilisera uw-imapd/uw-imapd-ssl, pour pop3, on utilisera ipopd. Pour les préconfigurer vous utiliserez les commandes :
dpkg-reconfigure uw-imapd
dpkg-reconfigure ipopd
Vous sélectionnerez pop3 et pop3/ssl, imap4 et imap/ssl. Attention pour imap4, c’est imap2 qu’il faut sélectionner. C’est bizarre mais c’est comme ça 😉 imap3 est devenu obsolète.
La procédure de configuration, génère des certificats dans /etc/ssl/certs/
32.2. DNS – préparation préalable
Vous allez déjà préparer votre serveur de nom. Le serveur de nom primaire sera également serveur SMTP (enregistrement MX – Mail eXchanger). Si votre serveur de nom s’appelle ns1, rajouter les enregistrements suivants dans le fichier de configuration de votre zone :
# On définit la machine qui achemine le courrier pour
# user@ns1.VotreDomaine.Dom
@ IN MX 10 ns1.VotreDomaine.Dom
#On définit un alias pour le courrier envoyé à
mail IN CNAME ns1
#On définit un alias pour le courrier envoyé à partir de
smtp IN CNAME ns1
#On définit un alias pour le serveur pop et pour imap
pop IN CNAME ns1
imap IN CNAME ns1
Relancer le service dns. Les commandes suivantes doivent fonctionner à partir d’un client du domaine :
ping ns1.VotreDomaine.Dom
ping smtp.VotreDomaine.Dom
ping mail.VotreDomaine.Dom
ping pop.VotreDomaine.Dom
ping imap.VotreDomaine.Dom
32.3. Configuration du serveur postifx.
Vous allez successivement configurer un serveur SMTP Postifx, tester la configuration, installer les serveur pop et imap, tester le fonctionnemnt de l’ensemble.
32.3.1. Installation du serveur SMTP
Configurer votre machine pour un service minimum (pas de liste, pas de réécriture d’adresse…).
Utilisez l’exemple de configuration de main.cf et la liste des variables à configurer donnés dans la fiche de cours, afin de mettre en place un service minimum.
Activez le service avec la commande /etc/init.d/postfix start. Vérifiez le bon démarrage du serveur dans le fichier de log et dans la table des processus (ps axf). Vous devriez obtenir quelque chose comme :
2745 ? S 0:00 /usr/lib/postfix/master
2748 ? S 0:00 \_ pickup -l -t fifo -c
2749 ? S 0:00 \_ qmgr -l -t fifo -u -c
2750 ? S 0:00 \_ tlsmgr -l -t fifo -u -c
Vérifiez également les traces dans le fichier de journalisation.
32.3.2. Test de la configuration du serveur SMTP
Créez sur la machine locale deux comptes systèmes pour les tests. cpt1 et cpt2 par exemple.
Ouvrez une session sous le compte cpt1 afin de réaliser un envoi de mail pour cpt2.
Lancez une transaction telnet VotreServeur 25, et réalisez un dialogue similaire à celui décrit en TD. Le message doit être délivré dans la boîte de cpt2. Utilisez la commande ps axf pour voir le chargement des différents démons.
Rélisez l’opération à l’aide du programme mail. Vérifiez que le message est bien délivré.
Avant de terminer la transaction, identifiez la session avec la commande netstat :
netstat -atup | grep ESTABLISHED
32.3.3. Installation du serveur PostOFFICE Pop3
La configuration du service pop est des plus simple. Il est même possible qu’il soit déjà actif. Décommentez la ligne dans le fichier /etc/inetd.conf ou utilisez dpkg-reconfigure.
Vérifier le fichier /etc/inetd.conf, relancez au besoin le service inetd.
# Pop and imap mail services
Avec xinet, la configuration est dans /etc/xinetd.d. Éditez les fichiers correspondant aux différents services. Par exemple le fichier /etc/xinetd.d/pop3s.
# default: off
# The POP3S service allows remote users to access their mail \
# using an POP3 client with SSL support such as fetchmail.
service pop3s
{
socket_type = stream
wait = no
user = root
server = /usr/sbin/ipop3d
log_on_success += USERID
log_on_failure += USERID
disable = no
}
Dans inetd.conf, décommentez la ligne. Dans xinetd, mettez la variable disable à no.
Relancer le service inetd ou xinetd, vérifiez l’ouverture des ports avec la commande netstat.
Identifiez les numéros de ports des services dans le fichier /etc/services.
Vous allez réaliser l’opération à partir de la machine locale et d’une machine distante. La résolution de nom doit fonctionner, sinon utilisez les adresses IP. Vous utiliserez kmail ou le client de messagerie de Mozilla.
- Sur la machine locale qui est votre serveur SMTP et serveur POP3, configurez le client de messagerie avec les paramètres suivants :
- Serveur smtp : Nom de votre serveur
- Serveur POP : Nom de votre serveur POP
- Votre compte d’utilisateur
- Votre mot de passe
Testez l’envoi et la réception de message.
Renseignez bien le numéro de port. Dans kmail, l’onglet extras vous donne accès à un bouton tester ce que le serveur peut gérer, et va vous renseigner sur le support de ssl ou tls du serveur.
Avec un client pop, les messages sont, par défaut, téléchargés depuis le serveur sur le client. La procédure supprime les fichiers téléchargés sur le serveur. Cette option est configurable sur la majorité des clients.
Vérifiez que les fichiers sont bien supprimés sur le serveur.
Réitérez l’envoi de message en mettant un fichier attaché (par exemple un fichier xls). Vérifier et relevez la description MIME du message.
- Sur un client configurez Nestcape Messenger avec les paramètres suivants :
- Serveur smtp : Nom de votre serveur (Machine distante)
- Serveur POP : Nom de votre serveur POP3 (Machine distante)
- Votre compte d’utilisateur
- Votre mot de passe
Testez l’envoi et la réception de message.
Identifiez les transactions dans le fichier de log.
Créez un compte utilisateur pn,
Créez un alias prenom.nom pour ce compte système dans le fichier /etc/aliases.
Mettez à jour le fichier /etc/aliases/db.
Vérifiez que les messages envoyés à :
pn@votredomaine ou prenom.nom@votredomaine doivent tous être correctement délivrés.
32.3.6. Utilisation des listes
Ouvrez à l’aide d’un éditeur le fichier /etc/aliases
Créez une liste de la façon suivante :
maliste: cpt1, cpt2
Enregistrez et régénérez le fichier aliases.db
Envoyez un message à maliste@foo.org, vérifiez que tous les membres de la liste ont bien reçu le message.
32.3.7. La gestion des erreurs
Certaines erreurs » systèmes » sont gérés par un compte particulier » MAILER_DAEMON « . Ce compte est en général un alias vers postmaster, qui, lui même redirige sur le compte de l’administrateur en fonction. Il agit commem un » robot » notamment quand un message ne peut être délivré.
Procédure de test
Envoyez un message à QuiNexistePas@foo.org
Relevez vos nouveau messages. Normalement, vous êtes averti que votre message n’a pas pu être délivré.
32.3.8. Mise en place du service IMAP sur le serveur
La mise en oeuvre est identique à celle du service Pop3. Configurer le fichier inetd.conf ou le fichier /etc/xinetd.d/imap. Relancer le service serveur (inetd ou xinetd).
Vous allez tester le bon fonctionnement de votre serveur : la commande ps aux | grep imap ne donne rien car le serveur imap est lancé » à la demande » par le serveur inetd ou xinetd.
Par contre la commande netstat -a | grep LISTEN | grep imap montre bien qu’un port est bien ouvert en » écoute « .
tcp 0 0 *:imap *:* LISTEN
Saisissez la commande telnet DeVotreServeurImap 143 pour activer le service imap. Le serveur doit répondre :
Trying 127.0.0.1…
Connected to localhost.
Escape character is ‘^]’.
* OK [CAPABILITY IMAP4 IMAP4REV1 STARTTLS LOGIN-REFERRALS AUTH=LOGIN]\
uranus.foo.org IMAP4rev1 2000.287rh at Sat, 17 Nov 2001 14:14:42 +0100 (CET)
Dans une autre session xterm, la commande ps aux | grep imap montre mainetant que le service est maintenant bien dans la liste des processus :
root 11551 0.0 1.1 3664 1448 ? S 14:14 0:00 imapd
et la commande ps axf
231 ? S 0:00 /usr/sbin/inetd
315 ? S 0:00 \_ imapd
montre bien que le processus imapd dépend (est fils de) inetd.
32.3.9. Plus loin dans le décryptage
La commande netstat a | grep imap donne l’état d’une connexion établie entre un client et le serveur.Socket client TCP sur le port 1024
tcp 0 0 *:imaps *:* LISTEN
tcp 0 0 *:imap2 *:* LISTEN
tcp 0 0 knoppix:imap2 knoppix:1025 ESTABLISHED
tcp 0 0 knoppix:1025 knoppix:imap2 ESTABLISHED
La commande fuser 1025/tcp utilise le pseudo-système de fichiers d’informations sur les processus /proc pour identifier » QUI » utilise la connexion tcp sur le port 1025.
root@knoppix:/home/knoppix# fuser 1025/tcp
1025/tcp: 364
La commande ls -l /proc/364 donne les indications sur le programme qui utilise cette connexion et montre que c’est une commande telnet qui a déclenché le processus.
root@knoppix:/home/knoppix# ls -al /proc/364
total 0
dr-xr-xr-x 3 knoppix knoppix 0 2003-04-16 15:06 .
dr-xr-xr-x 49 root root 0 2003-04-16 16:52 ..
-r–r–r– 1 knoppix knoppix 0 2003-04-16 15:06 cmdline
-r–r–r– 1 knoppix knoppix 0 2003-04-16 15:06 cpu
lrwxrwxrwx 1 knoppix knoppix 0 2003-04-16 15:06 cwd -> /home/knoppix
-r——– 1 knoppix knoppix 0 2003-04-16 15:06 environ
lrwxrwxrwx 1 knoppix knoppix 0 2003-04-16 15:06 \
exe -> /usr/bin/telnet-ssl
dr-x—— 2 knoppix knoppix 0 2003-04-16 15:06 fd
-r–r–r– 1 knoppix knoppix 0 2003-04-16 15:06 maps
-rw——- 1 knoppix knoppix 0 2003-04-16 15:06 mem
-r–r–r– 1 knoppix knoppix 0 2003-04-16 15:06 mounts
lrwxrwxrwx 1 knoppix knoppix 0 2003-04-16 15:06 root -> /
-r–r–r– 1 knoppix knoppix 0 2003-04-16 15:06 stat
-r–r–r– 1 knoppix knoppix 0 2003-04-16 15:06 statm
-r–r–r– 1 knoppix knoppix 0 2003-04-16 15:06 status
et voir la commande qui a activé cette connexion more /proc/364/cmdline qui retourne telnet localhost 143.
32.3.10. Mise en place du client IMAP
Utilisez Mail & NewsGroup de Mozilla ou kmail par exemple. Dans Mail & News Group, allez dans le menu de configuration (Edit) et ajoutez un compte. Prenez un compte imap.
Complétez la configuration de votre client de messagerie
Ouvrez l’application Messenger, testez l’utilisation du client IMAP.
Utiliser le » relayage » consiste pour un client A à utiliser le service serveur SMTP d’un domaine B pour inonder de messages (spammer) des boîtes aux lettres. Les serveurs sont généralement configurés pour empêcher le relayage. Dans Postifx, cette option est configurée par défaut.
Le relayage pose plusieurs problèmes. Remplissage des boîtes aux lettres sans l’accord des destinataires, utilisation des ressources disques et CPU à l’insu des sociétés qui relaient les courriers…
Afin de combattre un peu le phénomène, une société qui relai les messages peut se voir » black listée « , c’est-à-dire inscrite dans une liste noire référencée. Il existe plusieurs sites référençant ces listes noires. Certains de ces messages ne seront plus distribués. Voir pour cela, http://mail-abuse.org/rbl/, page principale de MAPS (Mail Abuse Prevention System LLC) RBLSM (Realtime Blackhole List).
Il est possible d’utiliser ces bases de données pour empêcher le relayage, ou refuser de délivrer les messages d’un site » black listé « .
maps_rbl_domains = rbl.maps.vix.com
maps_rbl_reject_code = 554
reject_maps_rbl
Vous allez activer la fonction de relayage sur votre serveur et tester son comportement. Modifiez la ligne :
relay_domains = $mydestination
par
relay_domains = $mydestination, domaine1.dom, domaine2.dom…
où domaine1.dom, domaine2.dom… représentent les différents domaines de votre salle de TP. Relancer les services serveurs.
Vous pouvez maintenant à partir d’un client, utiliser le serveur smtp d’un autre domaine pour vous en servir comme » agent de relai » et envoyer des messages aux utilisateurs des autres domaines.
32.3.12. Autres techniques de filtrage et autres services de postfix
Le fichier de configuration main.cf, permet de filtrer sur les entêtes de messages (grep) sous sur le contenu (body). Ces outils permettent dans certains cas de limiter le spam.
Le serveur postfix.org tient à jour des produits complémentaires qui permettent de mettre en place des antivirus, des outils de filtrage de spam ou des outils de type web-mail.
Chapter 33. Installation d’un serveur DDNS avec bind et DHCP
Le DNS dynamique
Le DNS dynamique
DHCP offre la possibilité de mettre à jour dynamiquement le système de résolution de nom.
Il s’agit, dans cette application, de faire cohabiter et faire fonctionner ensemble le service de résolution de nom bind et le service dhcp.
L’environnement a été testé sur une distribution debian, avec bind9 et dhcp3.
Vous devez savoir configurer un serveur DHCP, un serveur de nom, avoir compris le fonctionnement de rndc et des clés partagées, de dig.
Pour les amateurs d’ASCII-art, voici un schéma qui décrit les processus mis en oeuvre.
_______
| |_____________
| DHCP |_________ |
| | |3 |4
——- \|/ \|/
/|\| /|\| _______
| | | | | |
| | | | | DNS |
1|2| 5|6| | |
| | | | ——-
|\|/ |\|/
_______
| |
|Client |
| |
——-
(1) DHCPDISCOVER from 00:08:c7:25:bf:5a (saturne) via eth0
(2) DHCPOFFER on 192.168.0.195 to 00:08:c7:25:bf:5a (saturne) via eth0
(3) Added new forward map from saturne.freeduc-sup.org to 192.168.0.195
Ajout de l’enregistrement de type A
(4) added reverse map from 195.0.168.192.in-addr.arpa to saturne.freeduc-sup.org
Ajout de l’enregistrement de type PTR
(5) DHCPREQUEST for 192.168.0.195 (192.168.0.1) from 00:08:c7:25:bf:5a (saturne) via eth0
(6) DHCPACK on 192.168.0.195 to 00:08:c7:25:bf:5a (saturne) via eth0
Les opérations 1, 2, 5, 6 ont déjà été vues lors de l’étude du service DHCP. On voit en étudiant le » log » ci-dessus, que l’inscription dans le DNS d’un client se fait avant l’acceptation du bail et l’inscription finale de ce client (DHCPACK).
Dans cette application, vous installerez successivement le serveur de nom, le serveur dhcp, puis vous ferez les manipulations qui permettent l’intégration.
33.2. Éléments sur le service DDNS
Tout est décrit dans las pages de man de dhcpd.conf.
Deux façons de faire sont décrites (ad-hoc et interim) et une troisième est en cours d’élaboration. La méthode ad-hoc n’est semble t-il plus supportée par les paquets, du moins elle ne l’est pas avec le paquet dhcp3 de debian que j’utilise car considérée comme obsolète.
Le processus utilisé est défini par la variable ddns-updates-style. Si la mise à jour n’est pas dynamique, la variable prend la valeur none, nous, nous utiliserons interim.
La méthode » ad-hoc » ne prend pas en charge le protocole failover des DHCP. C’est à dire qu’avec cette méthode vous ne pourrez pas avoir 2 serveurs DHCP assurant un système redondant et mettant à jour un même ensemble d’enregistrements DNS.
Le serveur détermine le nom du client en regardant d’abord dans les options de configuration des noms (ddns-hostname). Il est possible de générer dynamiquement un nom pour le client en concaténant des chaînes » dyn+N°+NomDeDomaine « . S’il ne trouve rien, il regarde si le client lui a fait parvenir un nom d’hôte. Si aucun nom n’est obtenu, la mise à jour du DNS n’a pas lieu.
Pour déterminer le nom FQDN, le serveur concatène le nom de domaine au nom d’hôte du client.
Le nom du domaine lui, est défini uniquement sur le serveur DHCP.
Actuellement le processus ne prend pas en charge les clients ayant plusieurs interfaces réseau mais cela est prévu. Le serveur met à jour le DNS avec un enregistrement de type A et un enregistrement de type PTR pour la zone reverse. Nous verrons qu’un enregistrement de type TXT est également généré.
Quand un nouveau bail est alloué, le serveur crée un enregistrement de type TXT qui est une clé MD5 pour le client DHCP (DHCID).
La méthode interim est le standard. Le client peut demander au serveur DHCP de mettre à jour le serveur DNS en lui passant ses propres paramètres (nom FQDN). Dans ce cas le serveur est configuré pour honorer ou pas la demande du client. Ceci se fait avec le paramètre ignore client-updates ou allow client-updates.
Par exemple, si un client jschmoe.radish.org demande à être inscrit dans le domaine exemple.org et que le serveur DHCP est configuré pour, le serveur ajoutera un enregistrement PTR pour l’adresse IP mais pas d’enregistrement A. Si l’option ignore client-updates est configurée, il y aura un enregistrement de type A pour jschmoe.exemple.org.
33.3. Les aspects sur la sécurité
Le serveur DNS doit être configuré pour pouvoir être mis à jour par le serveur DHCP. La méthode la plus sûre utilise les signatures TSIG, basées sur une clé partagée comme pour le programme d’administration des serveurs de nom rndc.
Vous devrez en créer une. Pour cela utiliser les éléments fournis dans la partie traitant de bind. Ces aspects y ont déjà été abordés.
Par exemple dans le fichier named.conf, le serveur DHCP disposant de la clé DHCP_UPDATER, pourra mettre à jour la zone directe et la zone reverse pour lesquelles la déclaration allow-update existe.
Description du fichiers named.conf :
key DHCP_UPDATER {
algorithm HMAC-MD5.SIG-ALG.REG.INT;
secret pRP5FapFoJ95JEL06sv4PQ==;
};
zone « example.org » {
type master;
file « example.org.db »;
allow-update { key DHCP_UPDATER; };
};
zone « 17.10.10.in-addr.arpa » {
type master;
file « 10.10.17.db »;
allow-update { key DHCP_UPDATER; };
};
Dans le fichier de configuration du serveur DHCP vous pourrez mettre :
key DHCP_UPDATER {
algorithm HMAC-MD5.SIG-ALG.REG.INT;
secret pRP5FapFoJ95JEL06sv4PQ==;
};
zone EXAMPLE.ORG. {
primary 127.0.0.1; # Adresse du serveur de noms primaire
key DHCP_UPDATER;
}
zone 17.127.10.in-addr.arpa. {
primary 127.0.0.1; # Adresse du serveur de noms primaire
key DHCP_UPDATER;
}
La clé DHCP_UPDATER déclarée pour une zone dans le fichier dhcpd.conf est utilisée pour modifier la zone si la clé correspond dans le fichier named.conf.
Les déclarations de zone doivent correspondre aux enregistrement SOA des fichiers de ressources des zones.
Normalement il n’est pas obligatoire d’indiquer l’adresse du serveur de nom primaire, mais cela peut ralentir le processus d’inscription des enregistrements, voire même ne pas fonctionner, si le serveur de nom n’a pas répondu assez vite.
Chapter 34. Travaux pratiques : DDNS
Vous allez réaliser l’opération avec un client windows 2000 serveur et un client Linux. Le serveur Linux sera également serveur de nom.
Vous pouvez utiliser les exemples de fichiers fournis. Vosu aurez bien sûr à les adapter à votre configuration. Voici comment vont se dérouler les étapes :
- Installation du serveur de nom et test
- Installation du serveur DHCP et test
- Intégration des deux services
Nous verrons à la fin comment générer des noms dynamiquement pour les clients.
34.2. Les fichiers de configuration
Dans les fichiers il y a des lignes qui sont en commentaires avec ###, elles seront décommentées pour la phase d’intégration des services
// Pour journaliser, les fichiers doivent créés
logging {
channel update_debug {
file « /var/log/log-update-debug.log »;
severity debug 3;
print-category yes;
print-severity yes;
print-time yes;
};
channel security_info {
file « /var/log/log-named-auth.info »;
severity info;
print-category yes;
print-severity yes;
print-time yes;
};
category update { update_debug; };
category security { security_info; };
};
// clé partagée entre bind, rndc et dhcp
include « /etc/bind/mykey »;
options {
directory « /var/cache/bind »;
query-source address * port 53;
auth-nxdomain yes; # conform to RFC1035
forwarders { 127.0.0.1; 192.168.0.1;};
};
// Autorisations rndc sur la machine.
controls {
inet 127.0.0.1 allow {any;} keys {mykey;};
inet 192.168.0.0 allow {any;} keys {mykey;};
};
zone « . » {
type hint;
file « /etc/bind/db.root »;
};
zone « localhost » {
type master;
file « /etc/bind/db.local »;
};
zone « 127.in-addr.arpa » {
type master;
file « /etc/bind/db.127 »;
};
zone « 0.in-addr.arpa » {
type master;
file « /etc/bind/db.0 »;
};
zone « 255.in-addr.arpa » {
type master;
file « /etc/bind/db.255 »;
};
zone « freeduc-sup.org » {
type master;
file « /etc/bind/freeduc-sup.org.hosts »;
// Sert à la mise à jour par DHCP
// Sera décommenté lors de l’intégration des services
### allow-update { key mykey; };
};
zone « 0.168.192.in-addr.arpa » {
type master;
file « /etc/bind/freeduc-sup.org.hosts.rev »;
// Sert à la mise à jour par DHCP
// Sera décommenté lors de l’intégration des services
### allow-update { key mykey; };
};
34.2.2. Le fichier de zone directe
$ORIGIN .
$TTL 86400 ; 1 day
freeduc-sup.org IN SOA master.freeduc-sup.org. root.freeduc-sup.org. (
2004050103 ; serial
10800 ; refresh (3 hours)
3600 ; retry (1 hour)
604800 ; expire (1 week)
38400 ; minimum (10 hours 40 minutes)
)
NS master.freeduc-sup.org.
MX 10 master.freeduc-sup.org.
$ORIGIN freeduc-sup.org.
master A 192.168.0.1
www CNAME master
34.2.3. Le fichier de zone in-addr.arpa
$ORIGIN .
$TTL 86400 ; 1 day
0.168.192.in-addr.arpa IN SOA master.freeduc-sup.org. root.freeduc-sup.org. (
2004050103 ; serial
10800 ; refresh (3 hours)
3600 ; retry (1 hour)
604800 ; expire (1 week)
38400 ; minimum (10 hours 40 minutes)
)
NS master.freeduc-sup.org.
$ORIGIN 0.168.192.in-addr.arpa.
1 PTR master.freeduc-sup.org.
include « /etc/bind/mykey »;
options {
default-server localhost;
default-key « mykey »;
};
server localhost {
key « mykey »;
};
34.2.5. Le fichier de clé partagée
Ici il est nommé mykey.
key « mykey » {
algorithm hmac-md5;
secret « X/ErbPNOiXuC8MIgTX6iRcaq/1OFCEDIlxrmnfPgdqYIOY3U6lsgDMq15jnxXEXmdGvv1g/ayYtAA73bUQvWBw== »;
};
ddns-update-style none;
### ddns-update-style interim;
### deny client-updates;
### ddns-updates on;
### ddns-domainname « freeduc-sup.org »;
### ddns-rev-domainname « in-addr.arpa »;
authoritative;
subnet 192.168.0.0 netmask 255.255.255.0 {
option broadcast-address 192.168.0.255;
option routers 192.168.0.2;
option domain-name « freeduc-sup.org »;
option domain-name-servers 192.168.0.1;
option broadcast-address 192.168.0.255;
option routers 192.168.0.2;
range 192.168.0.100 192.168.0.195;
default-lease-time 600;
max-lease-time 7200;
# Instructions pour la mise à jour des zones
### include « /etc/bind/mykey »;
### zone freeduc-sup.org. {
### primary 192.168.0.1;
### key mykey;
### }
### zone 0.168.192.in-addr.arpa. {
### primary 192.168.0.1;
### key mykey;
### }
}
34.3. Procédure de tests des services
Vous allez pouvoir tester. À partir de maintenant vous devrez consulter les fichiers de logs si vous rencontrez des problèmes de fonctionnement, les tables de processus… bref tout ce qui pourra vous permettre de déterminer la ou les sources possibles des dysfonctionnements si vous en constatez.
Lancez le service bind et tester son fonctionnement avec rndc.
root@master:/home/knoppix# rndc status
number of zones: 8
debug level: 0
xfers running: 0
xfers deferred: 0
soa queries in progress: 0
query logging is OFF
server is up and running
root@master:/home/knoppix#
Ça permet de vérifier que la clé est bien reconnue.
Vérifiez le fonctionnement du serveur à l’aide de la commande dig.
root@master:/home/knoppix/tmp# dig @127.0.0.1 freeduc-sup.org axfr
; <<>> DiG 9.2.2 <<>> @127.0.0.1 freeduc-sup.org axfr
;; global options: printcmd
freeduc-sup.org. 86400 IN SOA master.freeduc-sup.org. root.freeduc-sup.org. 2004050107 10800 3600 604800 38400
freeduc-sup.org. 86400 IN NS master.freeduc-sup.org.
freeduc-sup.org. 86400 IN MX 10 master.freeduc-sup.org.
argo.freeduc-sup.org. 86400 IN A 192.168.0.253
master.freeduc-sup.org. 86400 IN A 192.168.0.1
www.freeduc-sup.org. 86400 IN CNAME master.freeduc-sup.org.
freeduc-sup.org. 86400 IN SOA master.freeduc-sup.org. root.freeduc-sup.org. 2004050107 10800 3600 604800 38400
;; Query time: 36 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Tue May 6 19:15:38 2003
;; XFR size: 8 records
Vérifier de la même façon le fonctionnement de la zone reverse.
Vérifiez la strucure du fichier dhcp.
root@master:/home/knoppix# dhcpd3 -t
Internet Software Consortium DHCP Server V3.0.1rc9
Copyright 1995-2001 Internet Software Consortium.
All rights reserved.
For info, please visit http://www.isc.org/products/DHCP
Ça permet de vérifier qu’il n’y a pas d’erreur de syntaxe dans le fichier.
Testez le fonctionnement traditionnel de votre serveur DHCP à partir d’un client Linux et windows. Faites des renouvellement de baux.
34.4. Intégration des services
Par défaut les client Linux ne transmettent pas leur nom d’hôte comme c’est le cas pour les clients windows. Modifiez sur le client Linux le fichier /etc/dhclient.conf de la façon suivante, nous verrons plus loin comment générer un nom dynamiquement :
[root@bestof mlx]# more /etc/dhclient.conf
send host-name « bestof »;
Décommentez dans les fichiers named.conf et dhcpd.conf les lignes commentées par ###.
Supprimez dans le dhcpd.conf la ligne :
ddns-update-style none;
Relancez le service DNS et testez sont bon fonctionnement
Vérifiez le fichier dhcpd.conf avec la commande dhcpd3 -t.
Lancez dhcp en mode foreground dhcpd3 -d, voici ce que vous devriez obtenir :
root@master:/etc/dhcp3# dhcpd3 -d
Internet Software Consortium DHCP Server V3.0.1rc9
Copyright 1995-2001 Internet Software Consortium.
All rights reserved.
For info, please visit http://www.isc.org/products/DHCP
Wrote 1 leases to leases file.
Listening on LPF/eth0/00:d0:59:82:2b:86/192.168.0.0/24
Sending on LPF/eth0/00:d0:59:82:2b:86/192.168.0.0/24
Sending on Socket/fallback/fallback-net
Demandez un bail à partir du client windows (ici windows 2000 Server), voici ce qui devrait se passer :
DHCPDISCOVER from 00:08:c7:25:bf:5a (saturne) via eth0
DHCPOFFER on 192.168.0.195 to 00:08:c7:25:bf:5a (saturne) via eth0
Added new forward map from saturne.freeduc-sup.org to 192.168.0.195
added reverse map from 195.0.168.192.in-addr.arpa to saturne.freeduc-sup.org
DHCPREQUEST for 192.168.0.195 (192.168.0.1) from 00:08:c7:25:bf:5a (saturne) via eth0
DHCPACK on 192.168.0.195 to 00:08:c7:25:bf:5a (saturne) via eth0
Demandez un bail à partir du client Linux, voici ce qui devrait se passer :
DHCPDISCOVER from 00:08:c7:25:ca:7c via eth0
DHCPOFFER on 192.168.0.194 to 00:08:c7:25:ca:7c (bestof) via eth0
Added new forward map from bestof.freeduc-sup.org to 192.168.0.194
added reverse map from 194.0.168.192.in-addr.arpa to bestof.freeduc-sup.org
DHCPREQUEST for 192.168.0.194 (192.168.0.1) from 00:08:c7:25:ca:7c (bestof) via eth0
DHCPACK on 192.168.0.194 to 00:08:c7:25:ca:7c (bestof) via eth0
Voici le contenu du fichier de journalisation de bind :
Log de Bind log-update-debug.log
root@master:/var/log# more log-update-debug.log
May 06 07:49:50.457 update: info: client 192.168.0.1#32846: updating zone ‘freeduc-sup.org/IN’: adding an RR
May 06 07:49:50.458 update: info: client 192.168.0.1#32846: updating zone ‘freeduc-sup.org/IN’: adding an RR
May 06 07:49:50.512 update: info: client 192.168.0.1#32846: updating zone ‘0.168.192.in-addr.arpa/IN’: deleting an rrse
t
May 06 07:49:50.512 update: info: client 192.168.0.1#32846: updating zone ‘0.168.192.in-addr.arpa/IN’: adding an RR
May 06 07:50:47.011 update: info: client 192.168.0.1#32846: updating zone ‘freeduc-sup.org/IN’: adding an RR
May 06 07:50:47.011 update: info: client 192.168.0.1#32846: updating zone ‘freeduc-sup.org/IN’: adding an RR
May 06 07:50:47.017 update: info: client 192.168.0.1#32846: updating zone ‘0.168.192.in-addr.arpa/IN’: deleting an rrse
t
May 06 07:50:47.017 update: info: client 192.168.0.1#32846: updating zone ‘0.168.192.in-addr.arpa/IN’: adding an RR
root@master:/var/log#
Voici le contenu du fichier de déclaration de zone avec les nouveaux enregistrements
root@master:/var/log# dig @127.0.0.1 freeduc-sup.org axfr
; <<>> DiG 9.2.2 <<>> @127.0.0.1 freeduc-sup.org axfr
;; global options: printcmd
freeduc-sup.org. 86400 IN SOA master.freeduc-sup.org. root.freeduc-sup.org. 2004050103 10800 3600 604800 38400
freeduc-sup.org. 86400 IN NS master.freeduc-sup.org.
freeduc-sup.org. 86400 IN MX 10 master.freeduc-sup.org.
argo.freeduc-sup.org. 86400 IN A 192.168.0.253
bestof.freeduc-sup.org. 300 IN TXT « 00e31b2921cd30bfad552ca434b61bda02 »
bestof.freeduc-sup.org. 300 IN A 192.168.0.194
master.freeduc-sup.org. 86400 IN A 192.168.0.1
saturne.freeduc-sup.org. 300 IN TXT « 310e43cfc20efbe1c96798d48672bc76aa »
saturne.freeduc-sup.org. 300 IN A 192.168.0.195
www.freeduc-sup.org. 86400 IN CNAME master.freeduc-sup.org.
freeduc-sup.org. 86400 IN SOA master.freeduc-sup.org. root.freeduc-sup.org. 2004050103 10800 3600 604800 38400
;; Query time: 381 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Tue May 6 07:56:43 2003
;; XFR size: 12 records
34.5. Générer un nom dynamiquement pour les clients DHCP
Cela est possible en modifiant le fichier de configuration de DHCP. Vous pourrez retrouver tous les éléments dans la page de manuel.
Par exemple rajoutez dans le fichier la ligne ci-dessous pour adapter le nom à partir de l’adresse MAC du client :
#ddns-hostname = binary-to-ascii (16, 8, « -« ,substring (hardware, 1, 12));
Ou celle-ci pour localiser le client :
ddns-hostname = concat (« dhcp-a-limoges », »-« ,binary-to-ascii(10,8, »-« ,leased-address));
Avec cette dernière, voici les enregistrements ajoutés :
Added new forward map from dhcp-a-limoges-192-168-0-194.freeduc-sup.org to 192.168.0.194
added reverse map from 194.0.168.192.in-addr.arpa to dhcp-a-limoges-192-168-0-194.freeduc-sup.org
DHCPREQUEST for 192.168.0.194 from 00:08:c7:25:ca:7c via eth0
DHCPACK on 192.168.0.194 to 00:08:c7:25:ca:7c (bestof) via eth0
Le fichier des incriptions :
root@master:/home/knoppix# more /var/lib/dhcp3/dhcpd.leases
lease 192.168.0.194 {
starts 2 2003/05/06 17:38:38;
ends 2 2003/05/06 17:48:38;
binding state active;
next binding state free;
hardware ethernet 00:08:c7:25:ca:7c;
set ddns-rev-name = « 194.0.168.192.in-addr.arpa »;
set ddns-txt = « 00e31b2921cd30bfad552ca434b61bda02 »;
set ddns-fwd-name = « dhcp-192-168-0-194.freeduc-sup.org »;
client-hostname « bestof »;
}
Les transferts de zones directes et inverses :
root@master:/home/knoppix/tmp# dig @127.0.0.1 freeduc-sup.org axfr
; <<>> DiG 9.2.2 <<>> @127.0.0.1 freeduc-sup.org axfr
;; global options: printcmd
freeduc-sup.org. 86400 IN SOA master.freeduc-sup.org. root.freeduc-sup.org. 2004050116 10800 3600 604800 38400
freeduc-sup.org. 86400 IN NS master.freeduc-sup.org.
freeduc-sup.org. 86400 IN MX 10 master.freeduc-sup.org.
0-8-c7-25-ca-7c.freeduc-sup.org. 300 IN TXT « 00e31b2921cd30bfad552ca434b61bda02 »
0-8-c7-25-ca-7c.freeduc-sup.org. 300 IN A 192.168.0.194
argo.freeduc-sup.org. 86400 IN A 192.168.0.253
dhcp-192-168-0-194.freeduc-sup.org. 300 IN TXT « 00e31b2921cd30bfad552ca434b61bda02 »
dhcp-192-168-0-194.freeduc-sup.org. 300 IN A 192.168.0.194
dhcp-a-limoges-192-168-0-194.freeduc-sup.org. 300 IN TXT « 00e31b2921cd30bfad552ca434b61bda02 »
dhcp-a-limoges-192-168-0-194.freeduc-sup.org. 300 IN A 192.168.0.194
master.freeduc-sup.org. 86400 IN A 192.168.0.1
www.freeduc-sup.org. 86400 IN CNAME master.freeduc-sup.org.
freeduc-sup.org. 86400 IN SOA master.freeduc-sup.org. root.freeduc-sup.org. 2004050116 10800 3600 604800 38400
;; Query time: 3 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Tue May 6 19:39:08 2003
;; XFR size: 14 records
La zone reverse :
root@master:/home/knoppix/tmp# dig @127.0.0.1 0.168.92.in-addr.arpa axfr
; <<>> DiG 9.2.2 <<>> @127.0.0.1 0.168.92.in-addr.arpa axfr
;; global options: printcmd
; Transfer failed.
root@master:/home/knoppix/tmp# dig @127.0.0.1 0.168.192.in-addr.arpa axfr
; <<>> DiG 9.2.2 <<>> @127.0.0.1 0.168.192.in-addr.arpa axfr
;; global options: printcmd
0.168.192.in-addr.arpa. 86400 IN SOA master.freeduc-sup.org. root.freeduc-sup.org. 2004050113 10800 3600 604800 38400
0.168.192.in-addr.arpa. 86400 IN NS master.freeduc-sup.org.
1.0.168.192.in-addr.arpa. 86400 IN PTR master.freeduc-sup.org.
194.0.168.192.in-addr.arpa. 300 IN PTR dhcp-192-168-0-194.freeduc-sup.org.
3.0.168.192.in-addr.arpa. 86400 IN PTR argo.freeduc-sup.org.
0.168.192.in-addr.arpa. 86400 IN SOA master.freeduc-sup.org. root.freeduc-sup.org. 2004050113 10800 3600 604800 38400
;; Query time: 3 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Tue May 6 19:40:08 2003
;; XFR size: 7 records
Chapter 35. Installation d’un service Web-mail
Agent Utilisateurs de Messagerie basés sur HTTP
Agent Utilisateurs de Messagerie basés sur HTTP
Il est préférable d’avoir réalisé les ateliers sur les serveurs HTTP, SMTP et DNS avant de commencer celui-ci.
Le service Web-mail permet l’utilisation d’un service de messagerie à partir d’un client Web comme mozilla. Cette interface est intéressante, car contrairement à un client pop3 standard qui serait configuré pour rapatrier les courriers sur la machine locale, ceux-ci, vont rester sur le serveur. Vous pouvez les consulter à partir de n’importe quel poste pourvu qu’il dispose d’un navigateur. Vous aurez ensuite tout le loisir de les récupérer avec votre client de messagerie préféré si vous en utilisez un.
Il existe un très grand nombre de serveur Web-mail, et écris dans des langages très différents. Une étude a été réalisée par le CRU http://www.cru.fr/http-mail/, mais parmi les principaux on peut citer IMP écris en PHP et qui s’appuie sur la librairie horde. Il existe aussi OpenWebmail qui lui est écris en Perl. Ces deux produits existent en paquets Debian, on utilisera pour le TP OpenWebmail, mais ces deux outils comportent chacun de nombreuses qualités, le choix devra se faire en fonction du degré d’intégration que vous souhaiterez obtenir avec vos autres applications.
35.2. Architecture générale du service
Figure 35-1. Architecture globale d’un service Web-mail
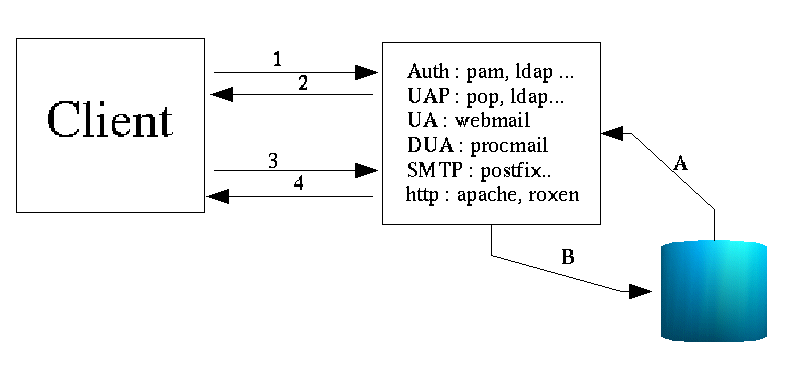
- En 1 et 2, le client passe par une phase préalable d’authentification, il faut donc un service correspondant sur le serveur. Cela peut être pris directement en charge par le service Web-mail ou par un service extérieur (pam, ldap par exemple). (Nous utiliserons l’authentification pam).
- En 3 et 4, le dialogue s’effectue en un navigateur et un serveur HTTP. Le dialogue peut s’effectuer dans un canal SSL ou TLS. Le suivi de session peut être réalisé à l’aide de cookie par exemple. (Nous utiliserons Apache comme serveur HTTP).
- En A et B, le service Web-mail utilise une base de données pour les boîtes aux lettres des utilisateurs, pour les dossiers (inbox, outbox, trash…) et la conservation des courriers. Certains Web-mail s’appuient sur des bases de type MySQL, PostgreSQL… ou simplement sur une arborescence de répertoires dans le HOME_DIRECTORY de l’utilisateur. (Nous n’utiliserons pas de SGBD/R).
- Sur le serveur, il faut activer un protocole de traitement du courrier (pop3, pop3s, imap, imaps…). Nous utiliserons imap et pop3.
- Vous aurez également besoin d’un service SMTP pour le traitement des courriers sortants (nous utiliserons postfix) et d’un service de livraison (DUA) (nous utiliserons procmail) pour délivrer les courriers entrants.
35.3. Installation et configuration OpenWebmail
Vous allez installer OpenWebmail mais auparavant il est nécessaire de s’assurer du bon fonctionnement de certains services. (smtp, mail, procmail, apache…)
35.3.1. Préparation de la machine
Suivez la procédure ci-dessous pour préparer la machine.
35.3.1.1. Configuration générale
On considère la configuration suivante, vous adapterez les noms, adresses IP et autres paramètres à votre configuration. Il n’y a pas de DNS.
Nom d’hôte : freeduc-sup ($NAME)
Nom FQDN de la machine : freeduc-sup.foo.org ($FQDN)
Adresse de réseau : 192.168.0.0
Adresse de la machine : 192.168.0.2
Adresse de la passerelle par défaut : 192.168.0.254
35.3.1.2. Test de la résolution de nom
Vérifier que la résolution de nom fonctionne parfaitement. Les commandes : ping $NAME et ping $FQDN doivent répondre correctement.
# Exemple de fichier /etc/hosts
127.0.0.1 freeduc-sup freeduc-sup.foo.org localhost localhost.localdomain
192.168.0.2 freeduc-sup freeduc-sup.foo.or
Activez le service apache. Il ne doit pas y avoir de message d’erreur au lancement, notamment sur la résolution de nom. Vérifiez également le bon fonctionnement avec une requête sur : http://localhost
35.3.1.4. Le service SMTP (Postfix)
Pour configurer postfix, utilisez la commande dpkg-reconfigure postfix, vous prendrez site internet. Les valeurs par défaut doivent normalement fonctionner.
Ouvrez le fichier /etc/postfix/main.cf, vérifiez qu’il correspond à celui-ci, au besoin modifiez le :
# Fichier de configuration de Postfix
# Adaptez vos noms d’hôtes et vos noms de machines
# see /usr/share/postfix/main.cf.dist for a commented, fuller
# version of this file.
# Do not change these directory settings – they are critical to Postfix
# operation.
command_directory = /usr/sbin
daemon_directory = /usr/lib/postfix
program_directory = /usr/lib/postfix
smtpd_banner = $myhostname ESMTP $mail_name (Debian/GNU)
setgid_group = postdrop
biff = no
myhostname = freeduc-sup.foo.org
mydomain = foo.org
myorigin = $myhostname
inet_interfaces = all
alias_maps = hash:/etc/aliases
alias_database = hash:/etc/aliases
mydestination = $myhostname, localhost.$mydomain
relayhost =
mailbox_command = procmail -a « $EXTENSION »
mailbox_size_limit = 0
recipient_delimiter = +
Une fois cela réalisé, activez ou relancez le service.
/etc/init.d/postfix start
/etc/init.d/postfix reload
35.3.1.5. Activation des services imap
Cela s’effectue dans le fichier inet.conf. Il faudra adapter si vous utilisez xinetd. Cela dépend de la distribution de GNU/Linux que vous utilisez. Vous pouvez également utiliser la commande dpkg-reconfigure uw-imapd. Dans ce cas, prenez imap2 (qui correspond à imap4 (? ;-))) et imaps.
Extrait d’un exemple de configuration de inetd.conf :
#:MAIL: Mail, news and uucp services.
imap2 stream tcp nowait root /usr/sbin/tcpd /usr/sbin/imapd
Adaptez votre fichier de configuration, puis relancer inetd avec la commande :
/etc/init.d/inetd restart
Vérifiez que les ports sont bien ouverts avec la commande netstat. Vous devez avoir les ports 25 (pop3)si vous l’avez activé et 143 (imap) ouverts.
netstat -atup | grep LISTEN
tcp 0 0 *:netbios-ssn *:* LISTEN 269/smbd
tcp 0 0 *:imap2 *:* LISTEN 263/inetd
tcp 0 0 *:sunrpc *:* LISTEN 151/portmap
tcp 0 0 *:ssh *:* LISTEN 278/sshd
tcp 0 0 *:ipp *:* LISTEN 290/cupsd
tcp 0 0 *:smtp *:* LISTEN 899/master
Nous voyons imap2, ligne 2, pris en charge par inetd.
root@freeduc-sup:/home/mlx# netstat -natup | grep LISTEN
tcp 0 0 0.0.0.0:139 0.0.0.0:* LISTEN 269/smbd
tcp 0 0 0.0.0.0:143 0.0.0.0:* LISTEN 263/inetd
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 151/portmap
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 278/sshd
tcp 0 0 0.0.0.0:631 0.0.0.0:* LISTEN 290/cupsd
tcp 0 0 0.0.0.0:25 0.0.0.0:* LISTEN 899/master
Ici l’option -n de netstat nous indique les numéros de ports utilisés.
Remarque : si vous souhaitez utiliser un client pop, vous devrez activer également le protocole pop.
À ce stade, il nous est possible de tester complètement le service de messagerie. Vous pouvez indifféremment utiliser un client comme kmail ou Mozilla. Le plus simple est d’utiliser le client mail.
Suivez la procédure ci-dessous :
- Créez deux comptes utilisateurs alpha et beta qui serviront pour les tests avec la commande adduser.
- Testez avec la commande mail que l’envoie de courrier se déroule correctement. Les commandes :
- mail alpha
- mail alpha@freeeduc-sup
- mail alpha@freeduc-sup.foo.org
doivent fonctionner correctement.
35.3.2. Installation d’OpenWebmail
Si vous utilisez la freeduc-sup, OpenWebmail n’est pas installé. Utilisez la commande :
apt-get install openwebmail
La commande installera également 3 paquets supplémentaires qui correspondent aux dépendances puis lancera la procédure de configuration.
35.3.3. Configuration de l’application OpenWebmail
Vous pouvez à tout moment reconfigurer l’application avec dpkg-reconfigure openwebmail. Prenez comme option :
authentification -> auth_pam.pl
langage -> fr
35.3.4. Test de l’environnement
Pour tester l’environnement vous avez deux liens :
http://localhost/openwebmail
qui vous place sur un espace documentaire
http://localhost/cgi-bin/openwebmail/openwebmail.pl
qui lance l’application proprement dite et vous amène sur la première fenêtre de login
Figure 35-2. Ouverture de session sur un Web-mail
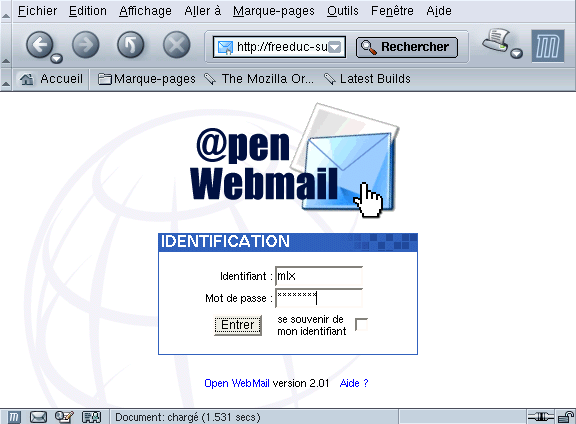
Il vous sera possible de créer un serveur Web virtuel pour avoir par exemple : » openwebmail.freeduc-sup.org « .
35.3.5. Configuration de l’environnement utilisateur
À la première session, la personne reçoit une invite lui permettant de configurer son environnement et ses paramètres particuliers, comme son adresse de réponse, modifier son mot de passe… Ces paramètres sont modifiables à tout moment.
Figure 35-3. Configuration de l’environnement utilisateur
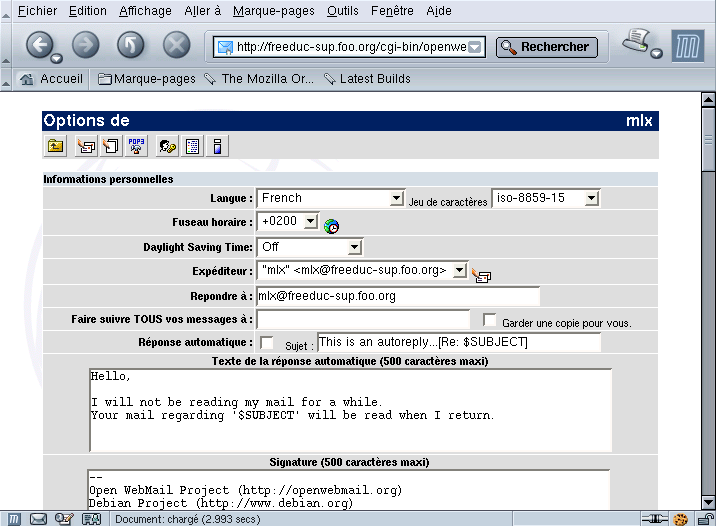
35.3.6. Test et environnement OpenWebmail
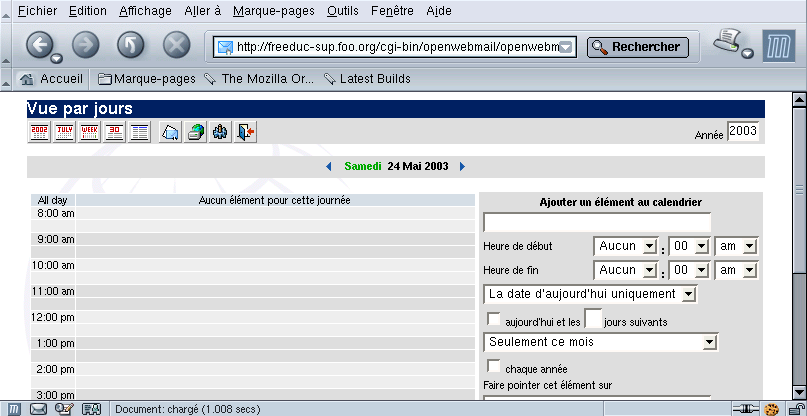
À partir de ce moment, l’environnement complet est disponible. L’utilisateur dispose également d’un calendrier et d’une documentation en ligne.
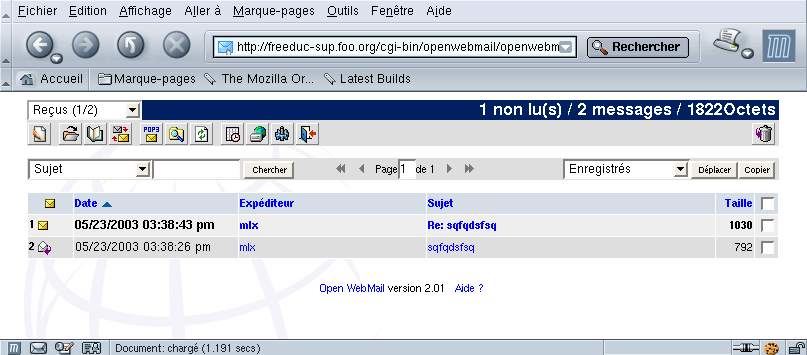
Figure 35-4. Voir ses messages
- Configurez et vérifiez le bon fonctionnement des services de résolution de nom, apache, postfix.
- Installez et configurez OpenWebmail.
- Testez le fonctionnement OpenWebmail.
Chapter 36. Installation d’un service mandataire (Proxy SQUID)
Serveur mandataire et serveur de cache – Fiche de cours
Serveur mandataire et serveur de cache – Fiche de cours
Squid est un service serveur proxy-cache sous linux. Les objets consultés par les clients sur internet, sont stockés en cache disque par le serveur. À partir du deuxième accès, la lecture se fera en cache, au lieu d’être réalisée sur le serveur d’origine. De ce fait il permet » d’accélérer » vos connexions à l’internet en plaçant en cache les documents les plus consultés. On peut aussi utiliser la technique du service serveur mandataire pour effectuer des contrôles d’accès aux sites.
Les services proxy peuvent être organisés de façon hiérarchique :
________
|serveur |
|national|
|________|
|
________|________
| |
___|____ ___|____
|serveur | |serveur |
|régional| |régional|
|________| |________|
|
______|______
| |
____|___ ____|___
|serveur | |serveur |
| local | | local |
|________| |________|
Ls serveurs peuvent être paramétrés pour les autorisations d’accès et les synchronisations.
Les postes clients sont souvent configurés pour utiliser un serveur proxy. Le client s’adresse au serveur proxy, et c’est ce dernier qui traite la requête sur internet. Un fois la réponse reçue, le serveur met en cache la réponse et la retourne au client interne. Le service proxy est fréquemment configuré sur un routeur qui remplit aussi le service de translation d’adresse ou translation de port, mais toutes ces fonctions sont bien différentes.
Dans certains cas, on peut ne pas souhaiter que la configuration soit réalisée au niveau du client. On souhaite que celle-ci soit faite au niveau du serveur. Cela peut arriver par exemple si vous avez plusieurs centaines de postes à configurer ou bien si vous ne souhaitez pas que les utilisateurs puissent modifier ou avoir accès à cette partie de la configuration. On parlera de » service proxy transparent « >. Le service serveur proxy peut être sur le routeur d’accès à l’internet ou sur une autre machine.
Service proxy tranparent :
La configuration des navigateurs, sur les postes clients, n’est pas concernée.
Vers internet
/|\ /|\
| |
___|____ ____|____ ________
|routeur | | | (3) | |
| proxy | | routeur | <—– | proxy |
|________| |_________| ——> |________|
| /|\ (2)
______|______ |
| | | (1)
____|___ ____|___ ____|____
| | | | | |
| client | | client | | client |
|________| |________| |_________|
<———————-> <—————————–>
Figure 1 Figure 2
Sur la Figure 1, le service proxy est installé sur le routeur.
Sur la figure 2, les requêtes du client (1), sont redirigées vers le proxy par le routeur (2), qui retourne au client la réponse ou redirige vers le routeur (3) pour un envoi sur l’extérieur.
Sur debian apt-get install squid.
Squid comporte de très nombreux paramètres. L’optimisation n’en est pas toujours simple. Nous allons voir uniquement quelques options permettant un fonctionnement du service. Il sera nécessaire, pour un site en production, de se référer à la documentation officielle.
Pour démarrer une configuration simple, il est possible d’utiliser le fichier de configuration /etc/squid.conf, dont chaque paramètre est documenté.
Toute la configuration de Squid se trouve dans le fichier squid.conf. La plupart des options par défaut du fichier ne sont pas à changer (vous pouvez alors laisser le # pour conserver les options en commentaire.)
http_port : le port que vous souhaitez utiliser. Le plus fréquent est 8080. Il faut donc changer cette valeur car par défaut Squid utilise 3128.
icp_port : conserver le port 3130. Ceci vous permet de communiquer avec des proxy-cache parents ou voisins.
cache_mem : correspond au cache mémoire, la valeur dépend de votre système. Par défaut squid utilise 8 Mo. Cette taille doit être la plus grande possible afin d’améliorer les performances (Considérez 1/3 de la mémoire que vous réservez à Squid). Il faut avec cache_mem régler cache_mem_low et cache_mem_high qui sont les valeurs limites de remplissage du cache mémoire. Par défaut les valeurs sont 75 % et 90 %. Lorsque la valeur de 90 % est atteinte le cache mémoire se vide jusqu’à 75 %. Les valeurs par défaut sont correctes dans la plupart des cas.
cache_swap : correspond à la taille de votre cache disque. Si la taille du disque le permet, et en fonction de la taille de votre établissement (nombre de clients qui utilisent le cache), mais aussi de la durée de rafraîchissement de votre cache et du débit de votre ligne, vous devez mettre la valeur qui vous semble correspondre à votre situation.
acl QUERY urlpath_regex cgi-bin \? \.cgi \.pl \.php3 \.asp : Type de page à ne pas garder dans le cache afin de pas avoir les données d’un formulaire par exemple.
maximum_object_size : taille maximale de l’objet qui sera sauvegardé sur le disque. On peut garder la valeur par défaut.
cache_dir : Vous indiquez ici le volume de votre cache. Si vous avez plusieurs disques, utilisez plusieurs fois cette ligne. Si squid ne fonctionne pas bien ou s’arrête parfois sans raison apparente, vérifiez que vous avez un cache assez important ou bien configuré.
cache_dir ufs /cache1 100 16 256 (cache de 100 Mb)
cache_dir ufs /cache2 200 16 256 (cache de 200 Mb)
Les valeurs 16 et 256, indiquent le nombre de sous-répertoires créés respectivement dans le premier niveau et suivants pour le stockage des données du cache.
cache_access_log ; cache_log ; cache_store_log : Indique l’endroit où se trouve les logs (fichiers de journalisation). Si vous ne souhaitez pas avoir de log (par exemple des objets cache_store_log) indiquer cache_store_log none.
debug_options ALL,1 : niveau de debug. Indiquer 9 pour avoir toutes les traces à la place de 1. Attention cela donne de gros fichiers.
dns_children : par défaut le nombre de processus simultanés dns est de 5. Il peut être nécessaire d’augmenter ce nombre afin que Squid ne se trouve pas bloqué. Attention de ne pas trop l’augmenter cela peut poser des problèmes de performance à votre machine (indiquer 10 ou 15).
request_size : taille maximale des requêtes. Conserver la valeur par défaut, concerne les requêtes de type GET, POST…
refresh_pattern : permet de configurer la durée de mise à jour du cache. Utiliser -i pour ne pas tenir compte des minuscules ou des majuscules. (voir le fichier squid.conf). Les valeurs Min et Max sont indiquées en minutes. Exemple :
# refresh_pattern ^ftp: 1440 20% 10080
visible_hostname : indiquer ici le nom de votre serveur proxy.
logfile_rotate : pour faire tourner vos logs et garder un nombre de copies. par défaut 10. attention si votre cache est très utilisé , il peut générer un grand volume de logs, pensez donc à réduire ce nombre.
error_directory : Pour avoir les messages d’erreurs en français (indiquer le répertoire où ils se trouvent). Exemple :
#error_directory /etc/squid/errors
#Créer un lien vers le répertoire où sont logés les messages en Français.
Cela n’est réalisé que la première fois afin de générer le cache.
squid -z
36.4. Les options de démarrage de Squid
On peut démarrer Squid en lui passant des commandes sur la ligne de commande. Différents paramètres peuvent être passés sur la ligne de commande. Les options passées de cette façon remplacent les paramètres du fichier de configuration de Squid squid.conf.
-h : Pour obtenir les options possibles
-a : Pour indiquer un port particulier
-f : pour utiliser un autre fichier de conf au lieu de squid.conf
-u : spécifie un port pour les requêtes ICP. (3110 par défaut)
-v : pour indiquer la version de Squid
-z : Pour initialiser le disque cache.
-k : Pour envoyer des instructions à Squid pendant son fonctionnement.
Il faut faire suivre -k d’une instruction
(rotate|reconfigure|shutdown|interrupt|kill|debug|check).
-D : pour démarrer squid lorsque vous n’êtes pas connecté en
permanence à internet (évite de vérifier si le serveur DNS répond).
Pour contrôler tout ce qui passe par votre serveur proxy, vous pouvez utiliser ce que l’on appelle les ACL (Access Control List). Les ACL sont des règles que le serveur applique. Cela permet par exemple d’autoriser ou d’interdire certaines transactions.
On peut autoriser ou interdire en fonction du domaine, du protocole, de l’adresse IP, du numéro de port, d’un mot, on peut aussi limiter sur des plages horaires.
La syntaxe d’une ACL est la suivante :
acl aclname acltype string[string2]
http_access allow|deny [!]aclname
acltype peut prendre comme valeur :
src (pour la source) : indication de l’adresse IP du client sous la
forme adresse/masque. On peut aussi donner une plage d’adresses
sous la forme adresse_IP_debut-adresse_IP_fin
dst (pour la destination) : idem que pour src, mais on vise
l’adresse IP de l’ordinateur cible.
srcdomain : Le domaine du client
dstdomain : Le domaine de destination.
url_regex : Une chaîne contenu dans l’URL
(on peut utiliser les jokers ou un fichier).
urlpath_regex : Une chaîne comparée avec le chemin de l’URL
(on peut utiliser les jokers).
proto : Pour le protocole.
Exemple 1 : Interdire l’accès à un domaine : supposons que nous souhaitions interdire l’accès à un domaine (par exemple le domaine pas_beau.fr). On a donc
acl veuxpas dstdomain pas_beau.fr
http_access deny veuxpas
http_access allow all # On accepte tout
La dernière ligne ne doit exister qu’une fois dans le fichier squid.conf.
Exemple 2 : interdire l’accès aux pages contenant le mot jeu.
acl jeu url_regex jeu
http_access deny jeu
http_access allow all
Attention url_regex est sensible aux majuscules/minuscules. Pour interdire JEU, il faut aussi ajouter JEU dans votre ACL. Il n’est pas besoin de réécrire toute l’ACL. On peut ajouter JEU derrière jeu en laissant un blanc comme séparation (cela correspond à l’opérateur logique OU).
On peut placer un nom de fichier à la place d’une série de mots ou d’adresses, pour cela donner le nom de fichier entre guillemets. Chaque ligne de ce fichier doit contenir une entrée.
Exemple 3 : utilisation d’un fichier
# URL interdites
acl url_interdites url_regex « /etc/squid/denied_url »
http_access deny url_interdites
Des produits associés à Squid (redirecteurs) permettent un contrôle plus simple. SquidGuard, par exemple, permet d’interdire des milliers de sites. Le site d’information est référencé plus loin dans la rubrique » liens « . Pensez, si vous utilisez SquidGuard, à configurer la ligne suivante dans le fichier squid.conf :
redirect_program /usr/local/squid/bin/SquidGuard
Exemple 4 : pour contrôler qui a le droit d’utiliser votre cache, créez une ACL du type :
acl si_OK src 192.168.0.0/255.255.0.0
http_access allow localhost
http_access allow site_OK
http_access deny all
36.6. Contrôler les accès par authentification
Parmi les demandes qui reviennent le plus souvent, la question de l’utilisation de Squid pour contrôler qui a le droit d’aller sur internet, est l’une des plus fréquentes.
On peut imaginer deux solutions :
La première consiste à contrôler les accès par salle et par horaires, en fonction d’un plan d’adressage de votre établissement. Le travail de l’académie de Grenoble avec ls projet SLIS permet de faire cela. On l’administre avec une interface Web. Ce n’est alors pas Squid qui est utilisé pour cela mais les fonctions de filtrage du routeur (netfilter par exemple). Construire des ACL directement dans Squid est faisable, mais cela n’est pas toujours simple à mettre en oeuvre.
La deuxième solution est de contrôler en fonction des individus. Squid permet de faire cela, à partir de plusieurs façons (APM, LDAP, NCSA auth, SMB…). Les différentes techniques sont décrites dans la FAQ de Squid sur le site officiel. Squid
Si vous utilisez un annuaire LDAP, vous devez avoir dans le fichier squid.conf les lignes suivantes :
acl identification proxy_auth REQUIRED
http_access allow identification
authentificate_program /usr/lib/squid/squid_ldap_auth \
-b $LDAP_USER -u uid SERVEUR_LDAP
LDAP_USER est l’ou (organizational unit) dans laquelle se trouve les clients
(par exemple ou=people, ou= ac-limoges, ou=education, ou=gouv, c=fr).
Si vous n’avez pas de serveur LDAP, une méthode simple à mettre en oeuvre, consiste à utiliser une méthode similaire au fichier .htaccess d’Apache.
Exemple de configuration avec NCSA_auth
authenticate_program /usr/lib/ncsa_auth /etc/squid/passwd
acl foo proxy_auth REQUIRED
acl all src 0/0
http_access allow foo
http_access deny all
36.7. Interface web de Squid et produits complémentaires
Squid dispose en standard de quelques outils, mais sinon vous pouvez utiliser webmin. Vous trouverez également, sur le site officiel de squid, une liste de produits supplémentaires pouvant être interfacés avec Squid.
Squid journalise les transactions dans un fichier access.log. Ce fichier donne les informations sur les requêtes qui ont transité par Squid. Le fichier cache.log informe sur l’état du serveur lors de son démarrage. Le fichier store.log informe sur les objets stockés dans le cache.
Les dates indiquées dans le fichier access.log indique le temps en secondes depuis le 1 janvier 1970 (format epoch), ce qui n’est pas très facile à lire. Un petit script en perl, permet de recoder les dates :
#! /usr/bin/perl -p
s/^\d+\.\d+/localtime $&/e;
Pour configurer les clients, on peut utiliser la configuration manuelle ou la configuration automatique avec des fichiers .pac ou des fichiers .reg que l’on place dans le script de connexion des clients.
Configuration manuelle des clients
36.10. Forcer le passage par Squid (Proxy transparent)
Il existe plusieurs solutions :
Configurer votre navigateur avec le bon proxy ou en utilisant le fichier de configuration automatique et le rendre impossible à changer. Mais cela nécessite que vous contrôliez les clients ce qui n’est pas toujours le cas.
Intercepter les requêtes sur le port 80 du routeur pour les rediriger sur Squid.
Vous devez alors avoir dans votre fichier squid.conf :
# Configuration de traitement des requêtes du client
httpd_accel_host virtual
httpd_accel_port 80
httpd_accel_with_proxy on
httpd_accel_uses_host_header on
httpd_accel_single_host off
Puis ajouter la règle pour netfilter de redirection des requêtes sur le port 80
iptables -t nat -F PREROUTING
iptables -t nat -A PREROUTING -i eth0 -p tcp –dport 80 \
-j REDIRECT –to-port 8080
# Les clients peuvent envoyer leurs requêtes sur le port 80 du proxy
# Le service NAT du routeur les redirige sur le port 8080
36.11. Le redirecteur SquidGuard
Squid dispose d’une fonctionnalité qui permet de passer une URL (requête entrante) à une application externe. Cela présente l’avantage de pouvoir bénéficier des services d’applications spécialisées. C’est par exemple le cas pour le redirecteur SquidGuard, largement utilisé pour protéger les accès sur des sites déclarés comme » impropres « . Une base de données de ces sites est tenue à jour. C’est cette dernière qui est utilisée pour filtrer les accès.
36.12. Les applications non prises en charge par un service proxy
Certaines applications ne sont pas prises en charge par Squid (https, smtp, pop, ftp…). Les raisons peuvent être diverses. Soit le service n’est pas pris en charge (pop, smtp…), soit il n’est pas conseillé de stocker en cache certaines informations d’authentification par exemple (https).
Pour les applications ou services non pris en charge par un service proxy, vous devrez utiliser l’ipmasquerade, un service de translation d’adresse ou utiliser une autre technologie.
Chapter 37. Travaux pratiques : installation de SQUID
Vous devez maîtriser les techniques de routage avec netfilter.
Vous allez installer un service proxy minimal, configurer les clients puis tester le fonctionnement de l’accès à internet à partir des clients.
Vous configurerez des ACLs permettant un contrôle d’accès aux données externes, vous ferez ensuite évoluer cette configuration vers un service mandataire transparent.
Le service proxy sera installé sur le routeur.
Utilisez les éléments de ce document, ainsi que les exemples de fichiers de configuration donnés en annexe. Vous pourrez également vous référer au document sur netfilter.
37.1.1. Préparation de la maquette
Vous avez un routeur qui vous relie au réseau de l’établissement et un client qui représente un segment de réseau privé. L’ensemble doit fonctionner (accès à internet, résolution de nom, masquage d’adresse.
iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -j MASQUERADE
# si 192.168.0.0 est le réseau privé
Vérifier que le routeur fonctionne. Faites un test à partir du client. Supprimez au besoin toutes les règles iptables et activez l’ipmasquerade.
Mettez une règle qui interdise toute requête à destination d’une application HTTP (port 80). Vérifier que les clients ne peuvent plus sortir.
# Ici on bloque tout, c’est brutal, mais on va faire avec.
iptables -P FORWARD DROP
37.1.2. Installation et configuration du service proxy
Faites une sauvegarde de votre fichier de configuration original (/etc/squid.conf). Modifiez le fichier de configuration de squid en vous appuyant sur celui donné ci-dessous.
http_port 3128
#We recommend you to use the following two lines.
acl QUERY urlpath_regex cgi-bin \?
no_cache deny QUERY
cache_mem 8 MBM
maximum_object_size_in_memory 8 KB
cache_dir ufs /var/spool/squid 100 16 256
cache_access_log /var/log/squid/access.log
cache_log /var/log/squid/cache.log
cache_store_log /var/log/squid/store.log
# Put your FQDN here
visible_hostname freeduc-sup.foo.org
pid_filename /var/run/squid.pid
#Recommended minimum configuration:
acl all src 0.0.0.0/0.0.0.0
acl manager proto cache_object
acl localhost src 127.0.0.1/255.255.255.255
#Recommended minimum configuration:
http_access allow manager localhost
http_access allow all
Initialisez l’espace disque pour le cache.
# Vérifiez que le FQDN de votre serveur est renseigné
# et que la résolution de nom locale fonctionne (fichier hosts ou DNS).
# initialisation de la zone de cache
squid -z
# Lancement de squid
/etc/init.d/squid start | restart
Démarrer et vérifier le bon fonctionnement de Squid. Consultez également les journaux.
$>ps aux | grep squid
root 2984 0.0 0.4 4048 1124 ? S 15:22 0:00 \
/usr/sbin/squid -D -sYC
proxy 2987 2.1 1.6 6148 4068 ? S 15:22 0:00 (squid) -D -sYC
Vérifier que le port d’écoute est correct.
mlx@uranus:~$ netstat -atup | grep LISTEN
(Tous les processus ne peuvent être identifiés, les infos sur
les processus non possédés ne seront pas affichées, vous devez
être root pour les voir toutes.)
tcp 0 0 *:3128 *:* LISTEN –
Identifiez l’endroit de stockage du cache sur le disque.
37.1.3. Configuration du client
Configurer le client pour qu’il utilise le service proxy sur les requêtes HTTP, vérifier le bon fonctionnement.
Figure 37-1. Configuration du client
Identifiez les traces dans les journaux.
root@uranus:/home/mlx# more /var/log/squid/access.log
1053864320.437 1741 192.168.0.2 TCP_MISS/200 5552 \
GET http://www.cru.fr/documents/ – DIRECT/195.220.94.166 text/html
1053864320.837 1096 192.168.0.2 TCP_MISS/304 331 \
GET http://www.cru.fr/styles/default.css – DIRECT/195.220.94.166 –
1053864321.257 420 192.168.0.2 TCP_MISS/304 331 \
GET http://www.cru.fr/logos/logo-cru-150×53.gif – DIRECT/195.220.94
1053864321.587 696 192.168.0.2 TCP_MISS/304 331 \
GET http://www.cru.fr/icons-cru/mailto.gif – DIRECT/195.220.94.166
1053864550.537 1461 192.168.0.2 TCP_MISS/200 5552 \
GET http://www.cru.fr/documents/ – DIRECT/195.220.94.166 text/htm
Interdisez tous les accès avec la règle :
http_access deny all
Vérifiez le fonctionnement.
37.1.4. Mise en place d’une ACL simple
Interdisez l’accès à un serveur (google.fr) par exemple. Vérifiez le fonctionnement.
acl google dstdomain .google.fr
http_access deny google
37.1.5. Utilisation de fichiers pour stocker les règles des ACL
Construisez deux fichiers, l’un qui permettra de stocker des adresses IP, l’autre des mots clés. Construisez une ACL qui interdit l’accès en sortie aux machines qui ont les adresses IP déterminées dans le premier fichier, et une ACL qui empêche l’accès aux URL qui contiennent les mots clés stockés dans le second fichier.
# Exemple de ce que le fichier « adresse_ip » contient :
# Mettez dans la liste des adresses celle de votre client pour tester
192.168.0.2
192.168.0.10
# Exemple de ce que le fichier « mot_cle » contient :
jeu
game
# Exemple d’ACL
acl porn url_regex « /etc/squid/mot_cle »
acl salleTP_PAS_OK src « /etc/squid/adresse_ip »
http_access deny porn
http_access deny salleTP_PAS_OK
Tester le fonctionnement de ces deux ACL. (Utiliser comme url de destination par exemple http://games.yahoo.com/)
37.1.6. Configuration des messages d’erreurs
Configurez Squid pour qu’il affiche des pages (messages d’erreur) en Français. Vérifiez le fonctionnement.
error_directory /usr/share/squid/errors/French
Identifiez la page qui est retournée lors d’un refus d’accès. Modifiez la page et le message retourné, puis vérifiez le fonctionnement.
37.1.7. Automatisation de la configuration des clients.
Créez un fichier .pac pour la configuration des clients Mozilla. Vous en avez un complet dans la FAQ de squid. Celui-ci fait le minimum.
function FindProxyForURL(url, host)
{
return « PROXY 192.168.0.1:3128; DIRECT »;
}
Mettez le fichier sur votre routeur dans /var/www/mozilla.pac et vérifiez que le serveur apache est bien démarré. Si la résolution de nom fonctionne, vous pouvez mettre le nom du serveur de configuration plutôt que l’adresse IP.
Configurez le client :
Figure 37-2. Configuration du client
Testez le bon fonctionnement du client.
Remettez la configuration du client dans sa situation initiale.
37.1.8. Installation et configuration du service proxy Squid transparent.
Modifier la configuration du client et du serveur, afin que la configuration globale devienne celle d’un proxy tranparent.
Vous allez modifier le fichier de configuration de squid et configurer votre routeur avec les règles suivantes si le service proxy est sur le routeur :
# A mettre dans le fichier de configuration de suid
# Relancer le service après
httpd_accel_host virtual
httpd_accel_port 80
httpd_accel_with_proxy on
httpd_accel_uses_host_header on
# Les règles iptables
# On nettoie la table nat
# On utilise le port 3128, par utilisé par défaut sous Squid.
iptables -t nat -F PREROUTING
# ou toutes les tables nat si besoin
iptables -t nat -F
# On laisse passer (masque) les requêtes autres que sur le port 80
iptables -t nat -A POSTROUTING -j MASQUERADE
# On redirige les requêtes sur le port 80
iptables -t nat -A PREROUTING -j DNAT -i eth1 -p TCP –dport 80 \
–to-destination 192.168.0.1:3128
Supprimer toute configuration de proxy sur le client. Vérifier le bon fonctionnement du client.
Arrêtez les service proxy, vérifiez que les requêtes HTTP des clients ne sortent plus.
Il est possible de séparer les services du routage et proxy sur 2 machines différentes. Le principe est identique, seules les règles sur le routeur changent un peu. Vous trouverez la description d’une telle configuration dans :
# Transparent proxy with Linux and Squid mini HOWTO
http://www.tldp.org/HOWTO/mini/TransparentProxy.html
# Lire aussi sur netfilter
http://www.netfilter.org/documentation/HOWTO/fr/NAT-HOWTO.txt
http://www.cgsecurity.org/Articles/netfilter.html
37.1.9. Mise en place de l’authentification
Mettez en place une ACL pour déclarer l’authentification des personnes.
# Ici on utilise le module ncsa_auth
auth_param basic program /usr/lib/squid/ncsa_auth /etc/squid/users
auth_param basic realm Squid proxy-caching web serve
auth_param basic children 5
acl foo proxy_auth REQUIRED
http_access allow foo
Créez les fichiers de compte et de mots de passe avec un compte utilisateur.
htpasswd -c /etc/squid/users unUTILISATEUR
# mettez ensuite son mot de passe.
# Testez le fonctionnement du fichier et du module
# Vous passez en paramètre le nom du fichier de comptes
# Vous mettez le compte et le mot de passe, le module retourne OK
# En cas d’erreur il retourne ERR
root@uranus:/etc# /usr/lib/squid/ncsa_auth /etc/squid/users
mlx password
OK
mlx mauvais
ERR
Figure 37-3. Authentification SQUID
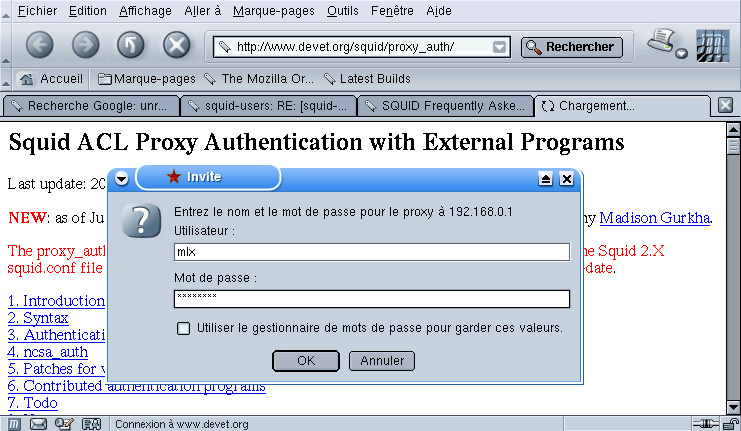
Il y a pas mal de différences entre les paramètres des versions de Squid 1, squid 2 et Squid 2.5. Il est important de consulter les fichiers de documentation fournis avec le produit.
L’authentification ne fonctionne pas avec la configuration d’un proxy transparent.
37.3.1. Fichier squid.conf – testé avec Squid 2.5
Fichier minimal pour Squid
http_port 3128
#Ne pas « cacher » les données des formulaires
acl QUERY urlpath_regex cgi-bin \?
no_cache deny QUERY
cache_mem 8 MBM
maximum_object_size_in_memory 8 KB
cache_dir ufs /var/spool/squid 100 16 256
cache_access_log /var/log/squid/access.log
cache_log /var/log/squid/cache.log
cache_store_log /var/log/squid/store.log
# Ici mettez le nom de votre machine
visible_hostname uranus.freeduc-sup.org
pid_filename /var/run/squid.pid
#Recommended minimum configuration:
acl all src 0.0.0.0/0.0.0.0
acl manager proto cache_object
acl localhost src 127.0.0.1/255.255.255.255
# Test des fichiers @ip et mots clés
acl porn url_regex « /etc/squid/mot_cle »
acl salleTP_PAS_OK src « /etc/squid/adresse_ip »
http_access deny porn
http_access deny salleTP_PAS_OK
# Authentification
auth_param basic program /usr/lib/squid/ncsa_auth /etc/squid/users
auth_param basic realm Squid proxy-caching web serve
auth_param basic children 5
acl foo proxy_auth REQUIRED
http_access allow foo
#Default:
#http_access deny all
#Messages d’erreurs en FR
error_directory /usr/share/squid/errors/French
# Pour le proxy cache transparent
httpd_accel_host virtual
httpd_accel_port 80
httpd_accel_with_proxy on
httpd_accel_uses_host_header on
37.3.2. Exemples d’ACLs Squid 2.2
Utiliser des fichiers externes pour la déclaration d’adresses ou de mots clés.
acl salleTP_OK src « /etc/squid/salleTP_OK.txt »
acl porn url_regex « /etc/squid/porn.txt »
acl salleTP_PAS_OK src « /etc/squid/salleTP_PAS_OK.txt »
http access salleTP_OK
http access porn
http deny salleTP_PAS_OK
37.3.3. ACL par authentification Squid 2.2
Utilisation d’une authentification simple similaire à celle mise en oeuvre dans les .htaccess. Créer le fichier par script ou manuellement avec htpasswd.
authenticate_program /usr/bin/ncsa_auth /etc/squid/users
authenticate_children 5
acl_authenticate_users REQUIRED
http_access authenticate_users
37.3.4. ACL sur des plages horaires Squid 2.2
Combinaison par » ET » logique des plages horaire et des salles. Mettre la machine à l’heure avec ntpdate par exemple.
# Interdire les accès en dehors des plages horaires 8h-12h et 14h-18h
S Sunday M Monday T Tuesday W Wednesday H Thrusday F Friday A Saturday
acl am time MTWHF 08:00-12:00
acl PM time MTWHF 14:00-18:00
http_access allow am salleTP_PAS_OK
http_access allow pm salleTP_PAS_OK
Chapter 38. Installation d’un serveur PostgreSQL avec Apache
>Serveur WEB dynamique avec PostgreSQL et PHP
>Serveur WEB dynamique avec PostgreSQL et PHP
Création d’un site web dynamique avec PostgreSQL et Apache. Pour PostgreSQL vous pouvez aussi utiliser la ressource Linux-France.org qui détaille de façon assez complète un mode d’utilisation de ce serveur de bases de données.
Si vous utilisez la Freeduc-Sup rc3, un bogue empêche PostgreSQL de se lancer. Vous devez avoir un message d’erreur dans « /var/log/postgres » qui vous indique qu’il n’arrive pas à trouver un fichier « pg_control ».
Voici comment corriger cela : sous le compte root taper
mv /var/lib/postgres/data /var/lig/postgres/data.old
dpkg-reconfigure postgresql
OK
OK
Yes
OK
fr_FR@euro
OK
LATIN1
OK
ISO
European
OK
NO
#C’est terminé, vous pourrez lancer PostgreSQL normalement.
Cela sera corrigé sur la prochaine version.
38.2. Les ressources sur PostgreSQL
Vous avez un support de cours, TD et TP assez complet sur Linux-Francequi décrit bien le mode d’utilisation de PostgreSQL.
Vous pourrez récupérer les documents nécessaires sous forme d’archive sur le serveur de linux-france. Pour cela voir la page d’introduction du document.
Accès à une base de données PostgreSQL à partir d’un client WEB (Mozilla ou autres)
On veut à partir d’un client « Web » comme Mozilla (ou autres) interroger une base de données PostgreSQL. Le client HTTP passe (via des formulaires) des requêtes SQL à un serveur Web sous Linux (Apache). Celui-ci dispose d’une interface « PHP » qui lui permet d’interroger la base de données. En fait Apache va « lancer » l’exécution de « scripts PHP » et éventuellement récupérer et retourner les résultats d’exécution au client.
Les processus mis en jeu côté serveur sont les suivants :
HTTPD qui va permettre les accès via le Web (Gestion des formulaires)
Postmaster qui est le daemon gérant tous les accès à la base.
Le serveur disposera également des documents HTML et des scripts PHP
- Le travail à réaliser en TP consistera donc à :
- – Créer une base de données Postgres
- – Démarrer le daemon postmaster permettant sa gestion
- – Démarrer le daemon HTTPD
- – Accéder à la base de données (via httpd) à l’aide de scripts PHP.
38.5. Présentation de PostgreSQL
PostgreSQL est un système de gestion de base de données, développé à l’origine par l’université de Berkeley. Il s’appuie sur les modèles relationnels mais apporte des extensions objet comme :
- les classes,
- l’héritage,
- les types de données utilisateurs (tableaux, structures, listes..),
- les fonctions,
- supporte complètement SQL,
- portable sur plus de 20 environnements depuis la version 6.4.
Cela permet de qualifier PostgreSQL de système de gestion de base de données « relationnel-objet » (ORDBMS), à ne pas confondre avec les bases de données orientées objets qui ne supportent pas SQL, mais OQL (Object Query Language).
PostgreSQL est diffusé avec ses sources (licence libre).
38.5.1. Mode de fonctionnement de PostgreSQL
Les trois composantes majeures sont :
- un processus de supervision (daemon) qui prend en charge les connexions des clients : postmaster,
- les applications clientes comme psql, qui permettent de passer des requêtes SQL,
- le ou les serveurs de bases de données (agents). Processus d’ouverture de session : (voir le schéma d’ouverture de session.)
38.5.1.1. Description du processus d’ouverture de session
- Le client passe une requête au daemon postmaster via un socket. Par défaut sur le port 5432. La requête contient le nom de l’utilisateur, le nom de la base de données. Le daemon, peut à ce moment utiliser une procédure d’authentification de l’utilisateur. Pour cela il utilise le catalogue de la base de données, dans lequel sont définis les utilisateurs.
- Le daemon crée un alors un agent pour le client. Le processus serveur répond favorablement ou non en cas d’échec du démarrage du processus. (exemple : nom de base de données invalide).
- Le processus client se connecte sur le processus agent. Quand le client veut clore la session, il transmet un paquet approprié au processus agent et ferme la connexion sans attendre la réponse.
- Plusieurs processus agents peuvent être initialisés pour un même client.
Comme pour la plupart des systèmes de gestion de données, toutes les informations système sont stockées dans des tables qui forment le dictionnaire (catalogue ou repository en Anglais). Utiliser le cataloque est essentiel pour les administrateurs et les développeurs. Vous pouvez voir la structure et le contenu de ces tables système.
38.5.1.3. PostgreSQL fournit :
un langage d’administration (création de base, d’utilisateurs)
un langage d’interrogation de données basé conforme à SQL
des extensions C, C++, perl, php, python…
38.5.1.4. Les comptes utilisateurs :
Le compte administrateur de la base est par défaut » postgres »
il faut créer les comptes utilisateurs
Voir le TP sur HTTP pour obtenir le compte système qui est utilisé par Apache pour les requêtes http. Sur la freeduc-sup c’est « www-data ». Dans la suite du document on utilisera $COMPTE_HTTP pour parler de ce compte système.
38.5.2. Langage de commande pour PostgreSQL
Voici quelques commandes d’administration de base :
Création d’une base de données : createdb
createdb [ dbname ]
createdb [ -h host ] [ -p port ] [ -D datadir ] [ -u ] [ dbname ]
Exemple : createdb -h uranus -p 5432 -D PGDATA -u demo
ou encore createdb demo
Suppression d’une base de données
dropdb [ dbname ]
Exemple dropdb demo
Créer un utilisateur :
createuser [ username ]
createuser [ -h host ] [ -p port ] [ -i userid ] [ -d | -D ] [ -u | -U ] [ username ]
-d | -D permet ou interdit la création de base à l’utilisateur
-u | -U permet ou interdit la création d’autres comptes à l’utilisateur.
Crée un compte dans pg_user ou pg_shadow. (tables système)
Si la base est accessible par Internet (exemple avec PHP), l’accès est réalisé par le compte » $COMPTE_HTTP « .
Utiliser la commande « select * from pg_user; » pour avoir la liste des utilisateurs.
Supprimer un utilisateur
drop user [ username ]
Accéder à une base:
psql [ dbname ]
psql -A [ -c query ] [ -d dbname ] -e [ -f filename ] [ -F separator ] [ -h hostname ] [ -o filename ] [ -p port ] -qsSt ]
[ -T table_options ] -ux [ dbname ]
mlx@mr:~$ psql template1
Welcome to psql, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help on internal slash commands
\g or terminate with semicolon to execute query
\q to quit
template1=#
PHP, (Personal Home Page) est un langage de programmation complet, assez proche du C. Il fournit :
- des structures de données,
- des structures de contrôle,
- des instructions de gestion des entrées/sorties.
Il est diffusé également sous licence libre. Il permet la création de pages web dynamiques.
Il est considéré comme une alternative à CGI, Perl, ASP (Active Server Page de Microsoft);
Développé à l’origine pour Linux, il est maintenant portable sur plusieurs environnements ( Windows 9.x, NT).
Il fournit des API pour les bases de données Oracle, PostgreSQL, MySQL, DB2 ;, et est conforme aux standards ODBC et ISAPI
Il fonctionne avec de nombreux serveurs HTTP comme Apache ou IIS (Internet Information Server) de MS.
PHP peut être utilisé seul ou combiné avec des bases de données et un serveur HTTP (Objet du TP).
Simple à mettre en oeuvre, documenté, sécurisé et fiable, de nombreux sites (FAI) comme libertysurf, free mettent cet outil à la disposition des clients.
38.6.1. Mode de fonctionnement de PHP
Sur Linux, PHP est compilé comme un module dynamique ou directement intégré à Apache, ce qui accroît les performances.
Le code PHP peut être intégré directement dans une page HTML comme vb-script ou à l’extérieur sous forme de fonctions (comme CGI).
Le code est logé entre deux balises < ? Ici le code ?>. Il est possible que pour assurer la compatibilité avec XML, les balises deviennent : <php et ?>
L’extension généralement utilisée pour les documents PHP est .php. Voir ci-dessous l’exemple » test.php » qui permet de vérifier le support de PHP par votre environnement.
Listing : test.php
<?
echo ( » Test du module PHP « );
phpinfo();
?>
Le guide utilisateur et ses extensions comprennent plus de 300 pages (voir les sources de documentations plus bas). La description ci-dessous donne les principales instructions pour les accès à une base de données PostgreSQL.
pg_Connect : Connexion à une base de données :
int pg_connect(string host, string port, string options, string tty, string dbname);
Retourne faux si la connexion échoue, un index dans l’autre cas. Il peut y avoir plusieurs connexions.
Exemple : $conn = $conn = pg_Connect(« localhost », « 5432 », » », » », « template1 »);
Ou : $conn = pg_connect(« dbname=marliese port=5432 »);
pg_Close : Fermer une connexion
bool pg_close(int connection);
pg_cmdTuples : Donne le nombre de tuples affectés par une commande insert,
update ou delete. Renvoie 0 sinon.
int pg_cmdtuples(int result_id);
Exemple :
<?php
$result = pg_exec($conn, « INSERT INTO verlag VALUES (‘Autor’) »);
$cmdtuples = pg_cmdtuples($result);
echo $cmdtuples . » affectés. »;
?>
string pg_dbname(int connection);
Donne le nom de la base de données.
Exemple $NomBase = pg_Dbaname ($conn);
pg_ErrorMessage :
string pg_errormessage(int connection);
Message d’erreur renvoyé par le serveur
pg_Exec : int pg_exec(int connection, string query);
Exécute une requête.
$UneChaineSQL = « Select * from UneTable »);
Exemple : $result = pg_exec($conn, $UneChaineSQL);
pg_FieldName : string pg_fieldname(int result_id, int field_number);
Renvoie le nom du champ d’indice field_number ;
Exemple :
indice = 0
While (indice [lt ] NombreDeChamp)
{
$NomChamp = pg_fieldname($result, indice)
echo $NomChamp
indice ++;
}
pg_FieldNum : int pg_fieldnum(int result_id, string field_name);
Donne l’indice pour un nom de champ.
pg_Host : string pg_host(int connection_id);
Donne le nom du Host
pg_NumFields : int pg_numfields(int result_id);
Renvoie le nombre de champs de la requête.
Exemple : $numF = pg_Numfields($result);
pg_NumRows : int pg_numrows(int result_id);
Renvoie le nombre de tuples (enregistrements) de la requête.
Exemple : $numR = pg_NumRows ($result);
if ($numR == 0)
{
echo « Aucun enregistrement retourné. « ;
exit;
}
pg_Result : mixed pg_result(int result_id, int row_number, mixed fieldname);
Renvoie la valeur d’un champ, pour un n° d’enregistrement donné et un résultat de requête. Les numéros d’enregistrement et de champ commencent à 0.
Exemple avec $i – indice d’enregistrement et $j – indice de champ :
$Valeur = pg_result ($conn, $i, $j)
pg_Options : pg_Options (int connection_id);
Renvoie une chaîne contenant les options de connexion à la base.
pg_FreeResult : int pg_freeresult(int result_id);
Libérer la mémoire.
Autres fonctions de base :
pg_Fetch_Array, pg_Fetch_Object, pg_Fetch_Row, pg_FieldsNull, pg_PrtLen,
pg_FieldSize, pg_FieldType, pg_GetLastOid, pg_port, pg_tty.
Vous trouverez la documentation de ces commandes dans celle de PHP.
38.7. Dialogue client et serveurs PHP, Apache et PostgreSQL
- Une requête SQL est passée par un formulaire HTML ou autre et via le protocole HTTP
- Le serveur Apache reçoit la requête HTTP
- Le module PHP exécute la requête sur la base PostgreSQL en utilisant les API
- Le code PHP met en forme le résultat de la requête
- La page est remise au serveur Apache
- Le serveur Apache retourne le résultat au client.
Vous avez deux méthodes pour passer les paramètres au serveur : la méthode « GET » et al méthode « POST ».
Voici un exemple de formulaire html et le script PHP associé.
Le formulaire : formsql.html
<!doctype html public « -//w3c//dtd html 4.0 transitional//en »>
<html>
<head>
</head>
<body>
Lancement d’un formulaire de requête SQL via un serveur HTTP
Utilise une base Demo
<br>
Entrez une chaîne sql valide – Exemple :
<form action= »resultsql.php » METHOD=post> // Ici le script qui sera exécuté
<textarea cols= »50″ rows= »5″
name= »c_SQL »>Select * from phonebook ;</textarea></p>
<br>
<INPUT TYPE= »submit » VALUE= »Search! »>
</form>
</body>
</html>
Figure 38-1. Formulaire de saisie
Le script associé : Page resultsql.php
‘Solution qui permet de s’affranchir du nombre de champs.
<?
/* Test de la connexion à la base */
if($c_SQL != « »)
{
echo $c_SQL ;
$conn = pg_Connect(« localhost », »5432″, » », » », »demo »);
if (! $conn)
{
echo « Erreur de connection à la base. \n »;
exit;
}
/* teste le résultat de la requête */
$result = pg_Exec($conn, $c_SQL);
if (! $result)
{
echo « Erreur d’accès aux tables. \n »;
exit;
}
/* teste le nombre de tuples retournées */
$numR = pg_NumRows ($result);
if ($numR == 0)
{
echo « Aucun enregistrement retourné. \n »;
exit;
}
/* Compte le nombre de champs */
$numF = pg_Numfields($result);
/* mise en forme du résultat sous forme tabulaire */
/* lignes (tuples), colonnes (champ) */
echo « <table border = 1> »;
$i = 0;
while ($i < $numR) {
echo « <tr> »;
$j = 0;
while ($j < $numF) {
$nc=pg_result($result,$i,$j);
echo « <td> »; echo $nc; echo « </td> »; $j++;
}
echo « </tr> \n »;
$i++;
}
echo « </table> \n »;
/* Libère la mémoire */
pg_FreeResult;
/* Ferme la connection */
pg_Close($conn);
}
?>
Figure 38-2. Résultat de la requête
Chapter 39. Travaux pratiques : PostgreSQL
Accès à une base de données PostgreSQL à partir d’un serveur Apache. Utilisation du langage PHP.
La maquette terminée devrait permettre, à partir d’un client HTTP comme Netscape de passer des requêtes SQL à un serveur Apache. Le serveur Apache dispose d’une interface PHP, qui lui permet d’échanger avec une base de données PostgreSQL .
Vous devrez récupérer pour le TP les documents suivants :
- Le script de création de la base de démo « formdemo.sql »
- le document HTML « formsql.html »
- le document php « resultsql.php »
Connectez-vous en tant que root.
1 Préparation de la configuration
Installez les packages correspondant à PostgreSQL et à PHP s’ils ne sont pas déjà installés.
2 Configuration de Postgres
2.1 Postgres est installé. Le script de lancement est dans « /etc/init.d »
Editez ce script et relevez l’emplacement où sont stockées les bases de données.
Recherchez le port et les protocoles de transports utilisés par PostgreSQL avec la commande « grep postgres /etc/services »
Vérifiez que le fichier « /etc/postgresql/postmaster.conf » comporte bien la ligne « POSTMASTER_OPTIONS= »-i -p 5432″. Cela permet de définir le numéro de port, et d’inquer à PostgreSQL de supporter les sessions sockets (-i).
Vous allez configurer les options de sécurité permettant au serveur de recevoir des requêtes. Ouvrez le fichier « /var/lib/postgres/data/pg_hba.conf ». Recherchez les lignes ci-dessous :
# Put your actual configuration here
# ———————————-
host all 127.0.0.1 255.0.0.0 ident sameuser
host all 0.0.0.0 0.0.0.0 reject
Modifiez ces lignes après avoir fait une copie de sauvegarde de ce fichier, de la façon suivante :
host all 127.0.0.1 255.0.0.0 trust
host all x.y.z.t x’.y’.z’.t’ trust
Vous adapterez « x.y.z.t » à l’adresse de votre réseau et « x’.y’.z’.t' » au masque de votre réseau.
2.2 Il s’agit maintenant d’activer le service. Utilisez les commandes :
/etc/init.d/postgresql stop
/etc/init.d/postgresql start
Vérifiez le chargement de postgres dans la table des processus : « ps aux | grep post »
Vérifiez dans les journaux les messages d’erreurs si le serveur ne démarre pas.
Vérifiez également :
– qu’ un service n’est pas déjà actif,
– que les variables sont bien déclarées. En général les messages de Postgres sont assez clairs et donnent la marche à suivre pour corriger. N’allez pas plus loin tant que tout cela ne fonctionne pas parfaitement.
3 Tester la configuration
La procédure précédente à créé un modèle de base de données « template1 », qui sert de modèle pour la création d’autres bases, et a créé un compte d’administrateur de base de données « Postgres« . Toujours en mode commande et en tant qu’utilisateur postgres (su postgres), vous allez utiliser la commande suivante :
psql template1
Attention, il n’y a qu’un seul compte de base de données, celui de l’administrateur « postgres ». Vous allez ouvrir une session sous le compte « root » puis passer sous le compte « postgres » avec la commande « su postgres ».
Vous devriez obtenir ceci :
# su postgres
sh-2.05b$ psql template1
Welcome to psql, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help on internal slash commands
\g or terminate with semicolon to execute query
\q to quit
template1=#
Le caractère « => » est le prompt du mode commande. Vous pouvez désormais taper des commandes.
Retenez « \q » pour quitter.
Pour avoir de l’aide sur l’interpréteur de postgres : template1=> \?
Pour avoir de l’aide sur les commandes SQL : template1=> \h
Si l’aide s’affiche, c’est que tout fonctionne. Par contre vous ne pouvez pas faire grand chose, la base et vide. Vous pouvez le vérifier avec la commande « \dt ».
template1=>\dt
Couldn’t find any tables!
template1=\q
Tout autre message, signifie qu’il y a un problème de configuration. Si c’est le cas vérifiez soigneusement tous les paramètres.
4 Conclusion
Votre environnement fonctionne et est bien configuré. La prochaine étape consiste à se familiariser avec les premières commandes d’administration et d’utilisation.
1 Créer une base de données
1 – Création de la base :
Vous devez avoir récupéré le script de création de la base « formdemo.sql »
su postgres (Vous devez être administrateur de la base)
createdb demo (création d’une base de données s’appelant demo)
2 – Création des tables de la base demo :
psql demo < formdemo.sql
2 Test de la base de données
Vous allez, au préalable, tester le fonctionnement de tout cela à partir du compte Administrateur « postgres ». Pour cela utilisez les commandes suivantes :
psql demo
# Pour afficher les tables
=> \dt
# consultez la table phonebook. Vous devriez avoir le résultat.
=>select * from phonebook; (Ne pas oublier ;)
#quitter
=> \q
3 Créer un compte d’utilisateur de base de données
Vous allez créer et utiliser deux comptes utilisateurs de bases de données. « $COMPTE_HTTP » qui est utilisé pour les accès HTTP, « TP1 » que vous utiliserez comme compte local. Vous leur affecterez pour l’instant les droits minimums.
3.1 Normalement le compte système$COMPTE_HTTP existe déjà, vous pouvez vérifier avec « grep $COMPTE_HTTP /etc/passwd ». Si ce n’est pas le cas, vous devrez créer un compte système pour $COMPTE_HTTP.
3.2 Création du compte système « TP1 »
# Création du compte
adduser TP1
# affectation d’un mot de passe.
passwd TP1
3.3 Vous allez créer les comptes de base de données pour $COMPTE_HTTP et TP1. Attention aux réponses que vous mettrez car $COMPTE_HTTP ne doit pas avoir la possibilité de créer des tables, ni créer d’autres comptes de bases de données.
3.3.1 Création du compte anonyme $COMPTE_HTTP
#passer en DBA (Data Base Administrator)
su postgres
$ createuser $COMPTE_HTTP
Enter user’s postgres ID or RETURN to use unix user ID: 99 ->
Is user « $COMPTE_HTTP » allowed to create databases (y/n) n
Is user « $COMPTE_HTTP » allowed to add users? (y/n) n
createuser: $COMPTE_HTTP was successfully added
#c’est terminé, voilà le résultat :
demo=# \q
sh-2.05b$ createuser www-data
Shall the new user be allowed to create databases? (y/n) n
Shall the new user be allowed to create more new users? (y/n) n
CREATE USER
sh-2.05b$
3.3.2 Création d’un compte DBA TP1
#passer en DBA (Data Base Administrator)
su postgres
$createuser TP1
Enter user’s postgres ID or RETURN to use unix user ID: 501 ->
Is user « TP1 » allowed to create databases (y/n) y
Is user « TP1 » allowed to add users? (y/n) y
createuser: TP1 was successfully added
#c’est terminé
3.3.3 $COMPTE_HTTP n’a aucune permission sur les bases de données. Vous allez lui donner la permission de faire des « select ».
Utilisez les commandes suivantes :
psql demo
grant select on phonebook to $COMPTE_HTTP ;
demo=# grant select on phonebook to « www-data »;
GRANT
demo=#
\q
4 Tester l’accès des comptes
Ouvrez une session avec le compte TP1 que vous avez créé.
psql demo
# Pour afficher les tables
=> \dt
# consultez la table phonebook. Vous devriez avoir le résultat.
=>select * from phonebook; (Ne pas oublier le ;)
#quitter
=> \q
Démarrez le serveur Apache : /etc/init.d/apache restart
Vérifiez que le serveur est bien actif et opérationnel.
Cherchez et relevez l’emplacement de stockage (Home Directory) des pages html d’Apache.
Vérification de la prise en charge de php par apache :
Normalement il n’y a plus rien à faire. Il s’agit de vérifier que le module PHP est bien pris en charge par Apache. Voici comment procéder:
1 – Créer dans Home Directory d’Apache le document testphp.php suivant:
<? echo (« Test du module PHP »);
phpinfo();
?>
2 – Lancez un navigateur (à partir de votre poste ou d’une autre machine) et tapez l’url « http://@IP de votre PC/testphp.php » .
Deux solutions :
- soit le résultat est bon, la fonction « phpinfo() » vous retourne des informations sur le module et sur Apache. Dans ce cas vous pourrez continuer,
Figure 39-1. Interrogation de PHP
- soit ce n’est pas le cas, il faut revoir la configuration.
39.5. Serveur PostgreSQL/Apache et PHP
Le serveur HTTP et le client fonctionnent, php est pris en charge par le serveur Apache. Maintenant, nous allons créer un formulaire qui permet de passer des requêtes SQL sur la base et un script qui exécute ces requêtes.
1 Test de la demo
1.1 En fait il s’agit de deux documents (formsql.html et resultsql.php) :
- le premier est une page HTML qui permet de saisir et « passer » des requêtes SQL,
- le deuxième au format PHP, met en forme le résultat de la requête.
1.2 Installez les pages fournies dans le répertoire d’Apache.
Lancez ensuite un navigateur. Tapez l’url http://@IP du PC/formsql.html. Vous pouvez saisir une chaîne sql et « envoyer » le formulaire.
2 Modifications
a) Copier insert.html dans le répertoire d’Apache, modifiez les permissions du compte $COMPTE_HTTP afin de lui donner la possibilité d’insérer des tuples dans la base de données. Modifiez le document resultsql.php afin de pouvoir réaliser des insertions dans la base. Les enregistrements à insérer seront saisis dans insert.html.
Figure 39-2. Formulaire insert.html
Durée de réalisation 20h en binômes
Vous allez créer une base de données conforme au schéma relationnel suivant :
cours (cours_no, cours_lib)
etudiant (etu_no, etu_nom)
inscrit(cours_no, etu_no)
On demande de développer l’interface web qui permet de :
- ajouter nouveau cours
- supprimer un cours
- modifier le libellé d’un cours
- ajouter un étudiant à un cours
Chapter 40. Surveillance, continuité de service
Heartbeat, logiciel de gestion de cluster pour la haute disponibilité (d’après Linux Magazine Hors Série 18 – Haute Disponibilité)
La continuité de service consiste à garantir la disponibilité de votre service. Si le serveur qui est chargé d’offrir ce service tombe en panne, il faut être capable de basculer rapidement sur une machine de secours. De même, il faudra gérer la remise en service du serveur principal. C’est le rôle de HEARTBEAT que je vous propose d’installer ici…
40.1. Principe de fonctionnement
Afin de garantir la continuité de service, nous devonsons utiliser des machines strictement identiques au niveau du contenu et des services offerts. Le rôle de hearbeat, c’est la surveillance de la machine principale par la (ou les) machine(s) de secours, et son activation en cas de défaillance du serveur principal. La synchronisation des contenus et des réglages n’est pas assurée par Heartbeat (pensez y notamment pour les contenus dynamiques, tels que les bases de données. Il faudra trouver une solution pour copier les contenus). Ces machines fonctionneront en cluster, c’est à dire qu’elles formeront à elles toutes UNE PSEUDO MACHINE.
Ainsi, définissons notre pseudo machine : 192.168.1.100.
Nos deux machines réelles auront pour adresses respectives 192.168.1.1, et 192.168.1.2.
le cluster (virtuel) www : 192.168.1.100
la première machine srv-principal : 192.168.1.1
la deuxième machine srv-secours : 192.168.1.2
C’est le cluster qui sera visible pour les clients. Ainsi, vous mettez à disposition la machine www (192.168.1.100). On décidera par exemple que c’est réellement la machine srv-principal (192.168.1.1) qui assure ce service, secondée par srv-secours (192.168.1.2).
Si d’aventure srv-principal tombait, alors très rapidement srv-secours le détectera, se donnera l’adresse IP de www (192.168.1.100), lancera des services selon sa configuration.
Au retour de srv-principal , on pourra, selon le fichier de configuration, continuer le service sur le serveur de secours, ou redonner la charge au serveur principal. Là encore, si il y a transfert d’identité, les scripts seront exécutés à nouveau (arrêt sur srv-secours, et lancement sur srv-principal).
40.2.1. Assurer la surveillance entre machines du cluster
Plusieurs solutions :
- Soit utiliser le réseau existant entre les machines, mais alors l’ensemble du réseau risque d’être pollué par des messages UDP,
- Soit utiliser de nouvelles cartes réseaux pour relier les différents noeuds du cluster (leur propre réseau de surveillance),
- Soit utiliser un câble NULL MODEM pour relier les deux noeuds du cluster par l’interface série (pour seulement deux machines).
Il est preferable de privilégier une communication spécifique entre les noeuds du cluster, afin de ne pas polluer le réseau avec les diffusions UDP associées au service Heartbeat. Ce faisant, on rencontre le problème suivant : On ne teste pas la rupture du câble réseau, ou un problème de carte réseau. Seul l’arrêt complet de la machine est testé (plus de signal sur le port série).
40.2.1.1. La surveillance sur le réseau de production
Cette méthode a l’inconvénient de polluer le réseau, et de modifier les éventuelles règles du firewall, car Heartbeat utilise des trames UDP sur le port 694 (configurable). Cet inconvénient est compensé par la surveillance de la rupture du câble, ou d’une défaillance quelconque du réseau en lui-même.
40.2.1.2. Le NULL-MODEM sur le port série
Le câble NULL MODEM permet d’échanger des données sur les prises séries de deux machines. Sous Linux, le port série est accessible (/dev/ttyS0 ) comme tout périphérique. Pour le tester, envoyez des données par une redirection :
Example 40-2. Après avoir connecté le NULL MODEM
Sur la première machine, lire le port série :
cat /dev/ttyS0
Sur l’autre machine, envoyer des données dans le port série :
echo « test » > /dev/ttyS0
Sur la première machine, le mot test devrait apparaître…
40.2.1.3. Le réseau de surveillance
Vous pouvez choisir de monter un réseau spécifique chargé de faire circuler les informations de contrôle des différents noeuds. Grâce à des cartes réseaux et un hub ou un switch (voir un simple câble croisé si il n’y a que deux noeuds). Dans ce cas, vous pouvez choisir par exemple d’adresser ce réseau en 10.0.0.0, et de construire la structure suivante :
Example 40-3. le cluster en réseau doublé
le cluster (virtuel) www : 192.168.1.100
la première machine srv-principal :
- eth0 : 192.168.1.1
- eth1 : 10.0.0.1
la deuxième machine srv-secours
- eth0 : 192.168.1.2
- eth1 : 10.0.0.2
Ici, le contrôle du fonctionnement de votre réseau de surveillance se fera par les outils habituels tel que ping,nmap,iptraf, comme pour le réseau de production.
Il est impératif de contrôler les points suivants :
- Le nom que vous utiliserez pour désigner votre machine doit bien être celui donné par la commande uname -n. Sinon, le logiciel le refusera. (Pour définir le nom d’une machine, il faut renseigner le fichier /etc/hostname.
- De même, les noms utilisés pour désigner les autres noeuds (machines) de votre cluster doivent être connus par chaque machine, soit par l’utilisation d’un dns, soit par le fichier /etc/hosts.
Sur une debian stable, l’installation se fait par la méthode standard :
apt-get install heartbeat
Debconf va ensuite vous aider à configurer ce service (pas sur sarge). J’ai preferé construire mes fichiers de configuration manuellement.
40.3.3. les fichiers de configuration
Il y a trois fichiers de configuration principaux :
- ha.cf contient les réglages de la machine réelle.
- haresources contient les réglages du cluster (la machine à simuler).
- authkeys contient les modes d’authentification (utile si on utilise le réseau de production).
Il est important de noter qu’haresources décrit le cluster tel qu’il doit être vu (notamment la ‘fausse’ adresse IP), tandis qu’ha.cf décrit le fonctionnement du noeud réel. Ainsi, ha.cf pourra varier selon les machines (nom de la carte réseau différent, logs réglés différemment) alors que haresources est lui PARTOUT IDENTIQUE (tous les noeuds doivent être d’accord sur le cluster à simuler).
petit tour du propriétaire :
- choix de médium de surveillance
la carte réseau
bcast eth0
le câble NULL MODEM
baud 19200
serial /dev/ttyS0
- logs
Les pépins
debugfile /var/log/hda-debug
Les évènements
logfile /var/log/hda-log
la facility (la sémantique des messages, voir le cours sur syslog)
logfacility local0
- délais de réaction (en secondes)
délai entre deux ‘pouls’
keepalive 2
durée du silence avant de déclarer un noeud ‘mort’
deadtime 10
durée du silence avant de déclencher une alerte
warntime 8
temporisation lors du lancement du service (si un noeud est lent)
initdead 30
- réglages generaux
port UDP pour le ‘pouls’
udpport 694
liste des noeuds participants au cluster (Attention, tous les participants doivent connaitre la liste exhaustive des noeuds concernés)
node srv-principal
node srv-secours
le serveur principal reprend la main lors de son retour
nice_failback on
La première partie permet de définir le mode d’écoute du logiciel de surveillance. Il semble que l’emploi du port série implique de bien définir les bauds avant. Vous pouvez combiner plusieurs modes d’écoute, c’est alors le silence sur tous ces médias qui entraînera les actions d’heartbeat .
La partie sur les logs permet de bien contrôler le fonctionnement du logiciel et valider les échanges entre les différents noeuds. Vous pouvez choisir les noms de fichiers que vous désirez, ainsi que la facility (pour le traitement par le démon syslogd).
La gestion de temps de réaction peut être donnée en millisecondes (par défaut, elle est en seconde) en ajoutant le suffixe ms (keepalive 200ms). Attention au initdead qui permet de gérer un noeud un peu lent à démarrer, et ainsi éviter de l’exclure immédiatement du cluster. La documentation préconise de doubler au minimum ce temps par rapport au deadtime.
Enfin, partie TRES IMPORTANT, la liste des noeuds qui participent au cluster. Lorsque tous les noeuds seront actifs, alors heartbeat activera le cluster et les services qui lui sont associés (les services démarreront à ce moment là, sur la machine qui est porteuse de l’adresse ip du cluster).
Ce fichier peut legerement différer selon les noeuds, dans les deux premières parties uniquement (puisque ce fichier définit les caractéristiques techniques sécifiques à ce noeud).
exemple de fichier ha.cf
On écoute sur le port série, les deux noeuds s’appellent hypérion et endymyon, et on ne loggue rien.
baud 19200
serial /dev/ttyS0
keepalive 2
deadtime 10
warntime 8
initdead 30
node hyperion
node endymion
On a maintenant un cluster de trois machines ubik, slans et fundation. La surveillance se fait via un réseau spécifique (sur la deuxième carte réseau), et on veut logger les informations, identifiées comme informations de programmes serveurs.
bcast eth1
udpport 694
logfile /var/log/heartbeat.log
logfacility daemon
keepalive 2
deadtime 10
warntime 8
initdead 30
node ubik
node slans
node fundation
40.3.3.2. Le fichier haresources
Fichier de description du cluster a simuler. IL DOIT ETRE IDENTIQUE SUR TOUS LES NOEUDS !. Ce fichier décrit la machine maître parmi tous les noeuds du cluster, la ou les adresses IP à simuler, et les services à assurer sur ce cluster.
Dans notre exemple, si on veut que notre cluster www ait l’adresse IP 192.168.1.100, que srv-principal soit la machine qui assure prioritairement ce rôle, et que www soit un serveur Web et mysql, alors tous les noeuds auront le fichier haresources suivant :
Example 40-4. haresources pour tous
srv-principal 192.168.1.100 apache mysql
Avec un tel fichier, automatiquement, dès la mise en route du cluster, (c’est à dire quand toutes les machines qui participent au cluster auront démarrées) le service Web et le serveur de base de données seront automatiquement activés. Si le serveur principal tombe, alors le serveur de secours prend le relais, lance le Web et Mysql, se donne la bonne adresse IP, fait un broadcast ARP pour avertir le réseau…
En cas de problème (unable to find an interface for ip), on peut etre plus précis sur l’adresse IP du cluster. Ainsi, on peut indiquer le nombre de bits du masque, et même la carte réseau qui doit porter l’alias (En théorie, cela devrait être résolu automatiquement… Vous remarquerez que, dans ce cas, les fichiers diffèrent légèrement sur chaque machine).
Exemple, dans lequel c’est hyperion qui doit être le maître, en prenant l’adresse 192.168.4.200 sur sa carte eth1
hyperion 192.168.4.200/24/eth1 apache postfix
Ce fichier détermine le niveau de securite des échanges entre les différents noeuds du cluster. Si vous êtes sur un médium fiable, vous pouvez utiliser le niveau le plus bas de sécurité (crc = simple contrôle de contenu, par l’utilisation d’une somme de contrôle, aucun cryptage). Il est possible d’utiliser des systèmes plus puissant (crypté avec md5 ou mieux encore (mais plus gourmand en temps processeur) sha). Dans les deux derniers cas, il faut fournir une clé… Cette clé (ou plutot ce fichier authkeys sera présent et identique sur chacun des noeuds.
auth 1
1 md5 « cluster cluster password »
2 crc
3 sha « conquistador »
Dans cet exemple, les trois modes sont prêts à fonctionner, avec les clés associées aux services, et c’est le md5 qui est choisi (auth est à 1). Ces clés doivent bien sur être les mêmes sur l’ensemble des noeuds participant au cluster.
Attention aux droits sur ce fichier de sécurité (600).
Autre exemple de fichier authkeys
auth 1
1 crc
Tous les fichiers de configuration mis en place sur tous les noeuds, vous pouvez alors lancer le service (pour les recopies, vous pouvez éventuellement vous aider de scp). le lancement du service se fait de la façon habituelle.
/etc/init.d/heartbeat start
Des que le cluster est constitue (tous les noeuds sont actifs), alors srv-principal héritera d’une nouvelle adresse IP (en ip-aliasing) 192.168.1.100, et les services apache et mysql seront alors lancés (si ce n’était déjà fait). Les scripts de lancement apache et mysql sont ceux trouvés à l’endroit habituel (/etc/init.d). Le cluster fonctionne, et les clients peuvent s’y connecter.
Vous pouvez (VOUS DEVEZ !!) surveiller les fichiers de logs (grâce à tail -f /var/log/ha-log), et faire joujou en coupant brutalement le courant sur le serveur principal. Testez le nice_failback, la mise en route de différents services, ainsi que le réseau (ifconfig sur les noeuds, et sniff du réseau pour voir les broadcast ARP lors des changements de serveurs…
- Montez deux machines qui formeront le cluster, connectées à un réseau qui comporte aussi un client. Le client aura l’adresse IP 192.168.1.1, les deux serveurs 192.168.1.100 et 101. Le cluster aura l’adresse 192.168.1.200.
- Connectez le câble NULL MODEM. Vérifiez son bon fonctionnement.
- installez Heartbeat. Configurez le simplement, avec le ‘pouls’ sur le port série. Pour le moment, on ignore les différents services, seule l’adresse IP doit être gérée par le cluster.
- Sur le premier serveur, lancer heartbeat. Visualisez en continu le fichier de logs. Contrôlez les informations réseaux.
- Sur le second serveur, lancer heartbeat. Visualisez en continu le fichier de logs.
- Contrôlez le premier serveur : fichier de logs, et paramètres réseaux. Que remarquez vous ?. Faites des pings du cluster (192.168.1.200), et des deux serveurs. Contrôlez le contenu du cache arp (arp -a). Que remarquez vous ?
- Éteignez violemment le serveur principal. Consultez les logs du serveur secondaire. Que s’est il passé ? Affichez les informations réseaux. Que remarquez vous ? Affichez le cache arp du client. Que remarquez vous (bien que vous n’ayez lancé aucune demande de résolution arp) ?
- Heartbeat émet un ‘flood’ de réponses ARP (bien que personne n’ait posé de questions ARP) afin de forcer la mise à jour des caches ARP de tous les clients, le plus rapidement possible. Essayez de visualiser ces réponses ARP, en sniffant le réseau à partir du client, et en relançant le serveur principal. Vérifiez grâce aux logs, à ifconfig, et à votre sniff réseau l’ensemble des caractéristiques du logiciel.
- Modifiez la configuration sur l’ensemble des noeuds afin de créer un cluster dont l’adresse est 192.168.1.210, et qui assure le fonctionnement d’un serveur Web et d’une base de données MySql. Le pouls sera émis sur le port série et sur la carte réseau. Enfin, la remise en route du serveur principal ne déclenchera pas sa promotion, le serveur de secours restant le support du service jusqu’à sa défaillance. Vérifiez bien que les deux services à assurer ne sont pas lancés lors de l’init de la machine.
- Lancez le service heartbeat sur le premier serveur. Apache et MySql se lancent ils ?
- Lancez le service heartbeat sur le second serveur. Apache et MySql se lancent ils ?
- Testez le service à partir du client. Sniffez le réseau.
- Éteignez le premier serveur. Que se passe t’il sur le second ? Vérifiez si tous les services sont bien lancés. Arrêtez le sniff réseau du client. Retrouvez le ‘pouls’, l’arrêt de celui-ci, puis le flood de réponse ARP.
Chapter 41. Lilo : Linux Loader
Desciption des mécanismes de boot avec lilo
Le démarrage de votre système GNU/Linux ou d’autres systèmes, c’est le rôle de LILO
- Comprendre le fonctionnement de Lilo
- Adopter une stratégie d’installation de Linux
- En particulier : Lilo est un chargeur de Linux, LInux LOader
- En général : Lilo est un chargeur de systèmes d’exploitation
Lilo permet de charger sur une machine:
- plusieurs systèmes d’exploitation différents (multi boot)
- plusieurs noyaux différents de Linux (ex: pour des tests)
Prend en charge :
- les différentes partitions d’amorçage
- le chargement de Linux (disquette ou disque dur)
- la cohabitation d’autres systèmes (ex: Windows, *BSD, NT, …)
D’autres systèmes ont des chargeurs de systèmes. Si Lilo est le principal chargeur des systèmes il est :
- le chargeur principal, sinon il est
- le chargeur secondaire
41.2.1.1. « Lilo est limité à 1024 cylindres. » FAUX !
Les versions récentes de lilo utilisées depuis Debian Potato supportent lba32. Si le BIOS de la carte mère est assez récent pour supporter lba32, lilo devrait être capable de charger au-delà de la vieille limite des 1024 cylindres. Assurez-vous simplement d’ajouter la ligne « lba32 » vers le début de votre fichier /etc/lilo.conf si vous avez gardé une ancienne version de ce fichier.
- la documentation de lilo : en général dans /usr/share/doc/kernel-doc-(version) ou /usr/doc/kernel-doc-(version)
- les pages de manuels : man lilo lilo.conf
- la documentation de votre distribution
- le guide du ROOTard
Lilo a besoin d’informations pour accéder au répertoire /boot Ce répertoire est normalement sur la partition principale appelée / ou racine (root). quelques rappels et précisions sur :
- le système de gestion de fichiers (sgf) de Linux,
- les systèmes de partitions des disques.
Exemple de partitionnement qu’il faudra adapter à votre environnement.
/ (root) Fichiers de démarrage (/ + /boot + /bin + /sbin) (min 50MB)
/boot Partition contenant les images du noyau (Kernel) (Min 16MB)
/tmp Fichiers temporaires du système et des utilisateurs (min 100MB)
/var Journaux, spool (/var/log, /var/spool) (min 100MB)
/home Fichiers utilisateurs (min 100MB)
/usr Applications (min 300MB à 700MB avec X)
/usr/local Applications (en général hors distribution) (100MB)
/usr/src Sources des packages et du noyau
swap Fichier d’échange, à adapter en fonction de la RAM (en général 2 ois la taille de la RAM)
Lignes directrices pour la mémoire
Ce qui suit sont des indications grossières pour la mémoire.
4 Mo : Minimum suffisant pour faire fonctionner le noyau Linux.
16 Mo : Minimum pour un usage du système en mode console.
64 Mo : Minimum pour un système X simple.
128 Mo : Minimum pour le système X avec GNOME/KDE.
256+Mo : Confortable pour le système X avec GNOME/KDE.
L’option de boot mem=4m (ou lilo append= »mem=4m ») montrera comment le système se comporterait en ayant 4Mo de mémoire installée. Un paramètre de démarrage pour lilo est requis pour un système ayant plus de 64Mo de mémoire avec un vieux BIOS.
En fonction de la destination du serveur (impression, mail, news, …), il faudra prévoir une partition ou un disque pour les sous-systèmes.
- Un système de disque comporte un disque système ou une partition système, c’est le disque ou la partition de BOOT
- Un disque peut comporter plusieurs partitions primaires dites d’amorçage. Une partition d’amorçage est une partition sur laquelle il est possible d’amorcer un système d’exploitation. Ces partitions sont appelées partitions primaires.
- Sous Linux chaque disque peut comporter 4 partitions. 3 partitions primaires et une partition étendue, ou bien 4 partitions primaires par exemple.
- Un disque peut supporter jusqu’à 16 partitions. Exemple : 3 partitions primaires plus 12 partitions logiques sur une partition étendue.
Si vous avez 2 bus IDE1 et IDE2 avec 2 disques chacun vous pouvez:
- installer Linux (/boot) sur n’importe quelle partition primaire d’un des disques,
- installer Lilo sur le MBR du disque système si Lilo est le chargeur primaire,
- installer Lilo sur le PBR de la partition de Linux s’il y a un autre chargeur.
41.4.4. Disques E(i)DE et CDROM
Si vous avez un lecteur CDROM en deuxième lecteur sur le bus IDE1 vous devrez:
- installer Linux (/boot) sur n’importe quelle partition primaire du premier disque du bus IDE1,
- installer Lilo sur le MBR du disque système si Lilo est le chargeur primaire,
- installer Lilo sur le PBR de la partition de Linux s’il y a un autre chargeur.
41.4.5. Disques E(i)DE et SCSI
Si vous avez un bus SCSI et un bus IDE vous pourrez:
- installer Linux (/boot) sur n’importe quelle partition primaire du premier disque du bus IDE1,
- installer Linux (/boot) sur n’importe quelle partition primaire du disque d’id0 sur le bus SCSI, (les autres id ne fonctionnent pas),
- installer Lilo sur le MBR du disque système su Lilo est le chargeur primaire,
- installer Lilo sur le PBR de la partition de Linux s’il y a un autre chargeur.
Si vous avez 2 disques SCSI, vous pourrez:
- installer Linux (/boot) sur le disque d’id0 ou id1 (les autres id ne fonctionneront pas),
- installer Lilo sur le MBR du disque système si Lilo est le chargeur primaire,
- installer Lilo sur le PBR de la partition de Linux s’il y a un autre chargeur.
Attention avec les Bus SCSI
- connectez le lecteur de CDROM sur le connecteur le plus proche du processeur,
- affectez-lui un id supérieur à celui du dernier disque,
- vérifiez la terminaison physique et logique du Bus.
- Certains BIOS ne supportent pas de partitions d’amorçage au dessus du cylindre 1023,
- Attention si vous utilisez des outils comme fips.
- Ne créez pas de partition au-dessus de cette étendue avec un BIOS incompatible.
Installez Lilo
- sur le MBR (Master Boot Record), si vous n’avez pas d’autres chargeurs de système. Le MBR contient un enregistrement qui est chargé à chaque démarrage de la machine.
- sur le PBR (Partition boot Record) si vous utilisez un autre chargeur de système comme celui d’OS/2 ou Windows NT.
Quand ?
- Pendant l’installation de Linux.
- Après l’installation de Linux.
Où ?
- Sur une partition du disque dur. Dans ce cas il faudra bien choisir cette partition
- Sur le MBR si Lilo est le chargeur primaire
- Sur un PBR si Lilo est le chargeur secondaire (dans ce cas le chargement des systèmes est pris en charge par un autre chargeur)
- Linux doit être installé sur une partition primaire (ne pas utiliser de partition étendue)
- On peut modifier la partition de chargement en modifiant le fichier de configuration de Lilo (/etc/lilo.conf)
Attention: Si vous installez Lilo sur un MBR, alors qu’il y a déjà un chargeur, vous supprimerez le chargeur installé.
- Créez une partition pour Windows, installez Windows,
- Créez les partitions pour Linux, installez Linux,
- Installez Lilo sur le MBR
Pour lancer ou relancer lilo après une modification de configuration : /sbin/lilo
Attention : Linux ne lit pas naturellement les Fat 32 bits.
Windows NT propose son chargeur.
- Créez les partitions pour Windows NT et installez NT.
- Créez les partitions pour Linux et installez Linux.
- Installez Lilo sur le PBR de sa partition d’amorçage.
- Ajoutez Linux dans la table des partitions d’amorçage de NT (avec un utilitaire comme bootpart par exemple).
Le chargeur de NT permettra le chargement de Linux
41.5.5. Exemple avec 3 systèmes
Avec Windows 9.x et NT:
- créez les partitions appropriées,
- installez Windows 9.x,
- installez Windows NT et son chargeur,
- installez Linux sans mettre Lilo sur le MBR.
Attention aux systèmes de fichiers Fat, Fat 32, NTFS, ext2fs.
41.5.6. Avec d’autres systèmes
- voyez la documentation du système,
- les FAQs et HOWTOs,
- les forums de discussions.
- Lilo crée une copie de sauvegarde du secteur de Boot (MBR) dans le répertoire /boot.
- avec un disque IDE /boot/boot.0300
- avec un disque SCSI /boot/boot.0800
- il est possible de restaurer ce secteur de boot:
- dd if=/boot/boot.0300 of=/dev/hda bs=446 count=1
Explication On restaure le secteur de boot d’une partition primaire sur /dev/hda (disque IDE). Seuls les 446 premiers octets des secteurs sont nécessaires, les autres contiennent des informations sur les tables des partitions.
Attention il y a un risque, faire au préalable une disquette de démarrage.
Pour s’exécuter correctement, Lilo a besoin:
- d’information sur le système (type de disques, contrôleurs, …)
- d’un fichier de configuration (option d’exécution, partition d’amorçage, …).
41.6.2. Options de configuration
- boot partition qui contient le secteur de boot
- delay durée en 1/10 de seconde pendant laquelle le chargeur attend
- map emplacement du fichier de carte du noyau ou sinon /boot/map
- prompt affiche une invite au démarrage afin que l’utilisateur entre un choix
- image indique, pour la section, quelle image charger
- label alias permet de choisir entre plusieurs systèmes.
- append append permet de passer des paramètres au noyau, par exemple pour activer un peripherique specifique (graveur ide en SCSI).
- disk et bios disk et bios remplace le mapping entre nom de disque et l’ordre des disques dans le BIOS. A utiliser avec precaution.
41.6.3. Outils de configuration
- manuellement pour la création des fichiers et l’installation de Lilo,
- utilisation de l’environnement graphique (linuxconf ou webmin par exemple).
41.6.4. Exemple de fichier de configuration /etc/lilo.conf
# Support des disques de grande taille
lba32
#
#disk=/dev/hde
# bios=0x81
#disk=/dev/sda
# bios=0x80
boot=/dev/hda
map=/boot/map
install=/boot/boot.b
vga=normal
default= »linux »
keytable=/boot/fr_CH-latin1.klt
prompt
nowarn
timeout=100
message=/boot/message
menu-scheme=wb:bw:wb:bw
root=/dev/hda1
image=/boot/vmlinuz
label= »linux »
initrd=/boot/initrd.img
append= »devfs=mount hdc=ide-scsi acpi=ht resume=/dev/hda1 splash=silent »
vga=788
read-only
image=/boot/vmlinuz-old
label= »old »
initrd=/boot/initrd.img-old
append= »devfs=mount hdc=ide-scsi acpi=ht resume=/dev/hda1 splash=silent »
vga=788
read-only
image=/boot/vmlinuz-suze
label= »suse »
root=/dev/hda2
initrd=/boot/initrd.img
read-only
other=/dev/hda3
label= »win2k »
image=/boot/memtest-1.11.bin
label= »memtest-1.11″
Ici, il y a 4 images, et 4 systèmes différents
- si on veut installer un autre système sur la machine
- si Lilo est installé sur le MBR et doit être déplacé sur un PBR
Utilisez la commande « fdisk /mbr » sous Windows ou « /sbin/lilo -u sous Linux »
- Au démarrage du système utilisez les touches CTRL ou SHIFT. Les touches CTRL et SHIFT vont temporiser le système, pour permettre à l’utilisateur d’entrer une commande
- Au prompt « boot: » utilisez la touche TAB pour voir la liste des différents systèmes. La touche TAB affichera la liste des systèmes (champ « label » de /etc/lilo.conf).
41.8. Autres solutions sans Lilo
- Démarrer Linux avec la disquette de démarrage (si on ne désire pas modifier la configuration d’une machine)
- utiliser d’autres chargeurs commerciaux,
- utiliser loadlin, (pour charger Linux à partir de Windows)
- syslinux, chboot
loadlin permet de charger Linux à partir d’un prompt MS-DOS
- Exemple : Linux est installé sur la partition /dev/sda2
- Commande : loadlin NomDuNoyau root=/dev/sda2
- si Lilo n’est pas installé, les valeurs codées dans le noyau sont prises en compte.
- ces valeurs sont codées avec la commande rdev.
La commande rdev permet de voir quelle est la partition d’amorçage.
initrd est un fichier spécial (disque RAM), initialisé par Lilo, avant de charger le noyau,
Il permet de « pré-charger » les modules contenu dans /etc/modules.conf,
L’appel à initrd est configuré dans /etc/lilo.conf
Pour en savoir plus : man initrd mkinitrd mknod
Les modules pour les pilotes de périphériques sont configurés lors de l’installation initiale. modconf permet de configurer les modules ensuite au travers d’une interface utilisant des menus. Ce programme est utile lorsque des modules ont été oubliés lors de l’installation ou lorsqu’un nouveau noyau est installé.
Le nom des modules à précharger est listé dans /etc/modules. Utilisez lsmod et depmod pour les contrôler manuellement.
/etc/modules.conf
above snd-via82xx snd-pcm-oss
probeall scsi_hostadapter aic7xxx ide-scsi
alias ieee1394-controller ohci1394
probeall usb-interface usb-uhci ehci-hcd
alias sound-slot-0 snd-via82xx
alias eth0 tulip
alias autofs autofs4
alias eth1 via-rhine
Exemple de mise à jour, suite à la modification de /etc/modules.conf:
- Modification de /etc/modules.conf
alias scsi_hostadapter buslogic
- Création de la nouvelle image /sbin/mkinitrd -o /boot/NouveauNomInitrd.img numero_version_kernel
Vous avez vu :
- comment s’effectue le chargement de Linux,
- le rôle de lilo,
- comment installer et configurer Lilo,
- comment désinstaller lilo,
- adopter une stratégie pour installer plusieurs systèmes d’exploitation sur une machine Linux.
Chapter 42. Travaux pratiques : Kernel et Noyau
Mise en oeuvre des mécanismes de boot et d’optimisation du noyau.
Le but de ce TP est de savoir gérer le chargement du système, de la phase de boot à celle du chargement du noyau et de ses modules, init et les niveaux d’exécution seront abordés dans un autre TP.
- Utiliser Lilo
- Utiliser Grub
- Dé/Chargement de modules
- Librairies
- Installation d’un noyau standard
- Installation d’un noyau à partir des sources
- Durant l’installation, on sera interrogé sur le matériel ou les puces. Parfois, ces informations ne sont pas toujours faciles à trouver. Voici une méthode :
- Ouvrez le PC et inspectez l’intérieur.
- Notez les codes produits qui sont sur les grandes puces de la carte graphique, de la carte réseau, sur la puce à côté des ports série et la puce à côté des ports IDE.
- Notez les noms imprimés au dos des cartes PCI et ISA.
- Relevez dans /etc/lilo.conf, la configuration initiale et effectuez une copie de ce fichier avant toute modification.
- Relevez à l’aide de fdisk ou cfdisk le mapping de votre disque dur.
- Relevez à l’aide des commandes ci-dessous, les caractéristiques matérielles de votre poste de travail.
- $ lspci -v |less
- $ pager /proc/pci
- $ pager /proc/interrupts
- $ pager /proc/ioports
- $ pager /proc/bus/usb/devices
A partir d’une distribution Debian GNU/Linux
- Lisez attentivement ce document une première fois sans lancer les commandes.
- Lisez également les pages de manuel des commandes avec man et info
Notez la version actuelle de votre noyau :
uname -a
ls -l /boot/
ls -l /lib/modules/
ls -l /usr/src/
ou
cat /proc/version
Affichez les modules chargés et repérez celui chargé du support de la carte réseau
lsmod
lancez la commande ci-dessous, choisissez la dernière version du noyau en relançant à nouveau la commande avec le nom + version
apt-get install debhelper modutils kernel-package libncurses5-dev
apt-get install kernel-source-[2.4.26] # utilisez la dernière version
apt-get install fakeroot
entrez votre nom et adresse électronique
vi /etc/kernel-pkg.conf
déplacez vous dans le répertoire où se trouvent les sources
cd /usr/src
décompactez l’archive
tar xjvf kernel-source-(nouvelle-version).tar.bz2
supprimez le lien symbolique linux qui pointe sur la dernière version du noyau, s’il existe.
rm /usr/src/linux
créez un lien symbolique vers votre nouvelle version
ln -s /usr/src/kernel-source-(nouvelle-version) /usr/src/linux
déplacez vous dans les sources
cd /usr/src/linux
consultez les fichiers avec ,par exemple, mc
Documentation/*
README
README.debian
Makefile
lancez l’interface de configuration du noyau afin de constater que par défaut la sélection des modules du noyau ne correspond pas à celle que vous avez, c’est normal car à ce stade vous n’avez pas récupéré votre ancienne configuration (fichier .config dans les sources).
! pour le TP quitter sans sauver ! Si vous avez lu trop tard, lancer les commandes suivantes afin de purger vos sources
make mrproper
pour l’interface sous X
make xconfig
en mode console texte et ultra-basique
make menuconfig
make config
vérifiez la présence des modules réseau, video, … de votre machine
less /boot/config-(version-actuelle)
vérifiez également leur présence dans /lib/modules/kernel-(version-actuelle)/…
Vous pouvez également constater leur chargement dans le système et dans le fichier de chargement
lsmod
cat /etc/modules
copiez le fichier de config par defaut
cp /boot/config-(version-actuelle) /usr/src/linux/.config
alternative sous Suse : make cloneconfig
démarrez la configuration de votre nouveau noyau
make menuconfig
enlevez le module de votre carte réseau
au cours d’une autre manipulation , vous pourrez refaire ce TP en retirant tout support qui ne concerne pas votre architecture matérielle, afin d’obtenir un noyau optimisé à vos besoins, attention toutefois à ne pas retirer les modules nécessaires au fonctionnement de votre environnement.
help sur un module vous donne son label que vous retrouvez dans .config
quittez et sauvez les modifications
regardez vos modifications par rapport au fichier d’origine
pour voir vos modifications
diff /boot/.config-(version-actuelle) .config
éditez le fichier Makefile et mettez votre EXTRAVERSION personelle
profitez-en pour parcourir ce fichier et voir ce que font les différentes cibles (dep, clean, bzImage, …)
copiez votre /usr/src/linux/.config dans /boot
cp .config /boot/config-(nouvelle-version)
lancez les commandes de compilation suivantes:
make dep
make clean
make bzImage
make modules
Vous pourriez également enchaîner les traitements en une seule commande : make clean bzImage modules
Attention ! A ce point si vous recompiliez la même version de kernel, vous devez déplacer /lib/modules/kernel-(version-actuelle), afin de ne pas génerer, dans ce dernier, les modules issus de votre nouvelle compilation
mv /lib/modules/kernel-(version-actuelle) /lib/modules/kernel-version-actuelle-old
continuez ensuite par installer les modules
make modules_install
ls -l /lib/modules/ # Vous permet de constater la création du répertoire contenant les modules de kernel-(version-actuelle)
copiez les fichiers (noyau et System.map) créés par la compilation dans /boot
cp arch/i386/boot/bzImage /boot/vmlinuz-(nouvelle-version)
cp System.map /boot/Sytem.map-(nouvelle-version)
Si /boot/System.map existe et est un lien symbolique, vous devez le supprimer pour établir un lien avec le nouveau fichier.
rm /boot/System.map
ln -s /boot/Sytem.map-(nouvelle-version) /boot/Sytem.map
Supprimer /vmlinuz.old s’il existe, ou renommer le
rm /vmlinuz.old
permutez le lien symbolique /vmlinuz
mv /vmlinuz /vmlinuz.old
créez un lien symbolique pointant sur la nouvelle image du noyau
ln -s /boot/vmlinuz-(nouvelle-version) /vmlinuz
Editer lilo.conf et activer la section vmlinuz.old (si ce n’est pas fait) et valider vos changements
lilo -v
rebooter
shutdown -r now ou reboot
Extras, à faire plus tard
il est possible de rendre totalement automatique l’installation du noyau en lançant la commande (ne l’utilisez pas pour le TP)
cd /usr/src/linux
make modules_install install
Fabriquer un noyau « debianisé » en simple utilisateur: récupérer les sources du kernel et de pcmcia dans votre répertoire
$ cd ~/kernel-source-(nouvelle-version)
$ make menuconfig
$ make-kpkg clean
# N’utilisez pas –initrd, initrd n’est pas utilisé dans notre cas.
$ fakeroot make-kpkg –append_to_version -486 –initrd \
–revision=rev.01 kernel_image \
modules_image # modules_image pour pcmcia-cs* etc.
$ cd ..
# dpkg -i kernel-image*.deb pcmcia-cs*.deb # installation en tant que root
En réalité, make-kpkg kernel_image lance make oldconfig et make dep.
Si vous voulez les modules de pcmcia-cs, ou pas de support pcmcia, sélectionnez dans make menuconfig « General setup » dans « PCMCIA/CardBus support » et le déselectionner (càd décocher la case).
Sur une machine SMP, configurez CONCURRENCY_LEVEL selon kernel-pkg.conf(5).
Autre possibilité
cd /usr/src/linux
make-kpkg -revision debidon.2.4.26 kernel_image
après cette commande un noyau debianisé est créé dans /usr/src/
un utilisateur peut faire un package de kernel en utilisant fakeroot pour l’installer ensuite sur une autre machine, ou encore le stocker dans un repertoire dont le sources.list d’apt pointerait dessus.
fakeroot make-kpkg -revision debidon.2.4.26 kernel_image
root peut ensuite l’installer en lançant la commande
dpkg -i kernel_image-2.4.26_debidon.2.4.26_i386.deb
regardez les commandes mkboot et installkernel
42.4. Installation et activation de module
Affichez la liste des modules chargés et constatez que le module réseau n’est plus la, ni l’interface
lsmod
ifconfig -a
déplacez-vous dans les sources
cd /usr/src/linux
make menuconfig # (sélection du module de la carte réseau comme module)
quittez et sauvez
make dep
make modules modules_install
contrôlez les dépendences des modules
depmod -a
charger à chaud le module dans le système
modprobe nom_module
ou (ie remplacer alias par dans notre cas eth0) (voir /etc/modules.conf)
modprobe alias
contrôlez la présence du module
lsmod
réactivez le réseau
/etc/init.d/networking restart
NB: pour charger/décharger les modules du noyau.
modconf
si modules.dep ne se trouve pas dans /lib/modules/(version-encours)
depmod -a
pour prendre en compte un module au chargement, ajouter-le dans /etc/modules
man modules.conf
42.4.1. make-kpkg pour les modules
exemple pcmcia-cs + pcmcia-sources
cd /usr/src
récupérer sur http://pcmcia-cs.sourceforge.net/ et décompresser les sources pcmcia dans le repertoire modules après install du noyau
cd /usr/src/modules/pcmcia-cs
make clean
make config
cd /usr/src/linux
make-kpkg –revision=custom.1.0 modules_image
cd /usr/src/
dpkg -i pcmcia-modules*.*.deb
Pour plus d’informations sur la compilation http://www.debian.org/doc/manuals/reference/ch-kernel.fr.html
Le nouveau gestionnaire de démarrage grub du projet GNU Hurd peut être installé sur un système Debian Woody
# apt-get update
# apt-get install grub-doc
# mc /usr/share/doc/grub-doc/html/
… lisez le contenu
# apt-get install grub
# pager /usr/share/doc/grub/README.Debian
… à lire
Comment configurer les paramètres de démarrage de GRUB
GRUB est un nouveau gestionnaire de démarrage issu du projet Hurd et est beaucoup plus flexible que Lilo mais a une manière différente de gérer les paramètres de démarrage.
# grub
grub> find /vmlinuz
grub> root (hd0,2)
grub> kernel /vmlinuz root=/dev/hda3
grub> initrd /initrd # ne pas utiliser dans notre cas
grub> boot
Là, vous devez connaître les noms de périphériques de Hurd :
the Hurd/GRUB Linux MSDOS/Windows
(fd0) /dev/fd0 A:
(hd0,0) /dev/hda1 C: (habituellement)
(hd0,3) /dev/hda4 F: (habituellement)
(hd1,3) /dev/hdb4 ?
Voir /usr/share/doc/grub/README.Debian et /usr/share/doc/grub-doc/html/ pour les détails.
Pour modifier le menu de GRUB, éditez /boot/grub/menu.lst. Voir Comment configurer les paramètres de démarrage de GRUB, pour la configuration des paramètres de démarrage car la syntaxe est différente de celle de lilo.
Il faut distinguer les librairies statiques des librairies dynamiques.
Les librairies statiques possèdent l’extension « .a ». Ces librairies sont liées statiquement avec le binaire (programme). C’est à dire que durant la phase de linkage (édition des liens lors de la compilation) le compilateur va prendre le code des fonctions nécessaires de la librairie et les mettres en dur dans le binaire.
Les librairies dynamiques possèdent l’extension « .so ». Ces librairies sont liées dynamiquement avec le binaire. Dans ce cas, le code des fonctions utilisées par le programme ne se trouve pas dans le binaire. Mais lorsque ce bout de code est requis par le programme, il va charger ce code dynamiquement (durant l’exécution du programme).
Un programme lié statiquement avec une librairie sera plus gros en taille que pour une libriaire dynamique.
Pour les libriaires dynamiques, voici le fichier à configurer qui donne les chemins où se trouvent les librairies dynamiques /etc/ld.so.conf
La commande ldconfig parcours les chemins spécifiés dans le fichier de configuration et construit un cache. Ce cache est utilisé par le « run-time linker » (chargeur de librairies durant l’éxecution d’un programme).
Consulter les man page de la commande ldconfig pour plus de précision sur les arguments… elle s’utilise en général de manière très simple sans argument (doit être executée en root). Cette commande doit être exécutée après l’installation de nouvelles librairies (généralement cela est effectué automatiquement lors de l’installation des packages).
Consulter également les man page de la commande ldd et ld
Chapter 43. Init : Initialisation du système sous Linux
Initialisation du système sous Linux
Une fois le processus de boot terminé, votre système a besoin de lancer les daemons (ftp, nfs, gettys, …) , c’est le rôle d’init
- Guide de l’administrateur système (Traduction E. Jacoboni)
- Guide du RooTard
- BootDisk HowTo
- BootPrompt HowTo
- chargement du BIOS,
- initialisation du chargeur (LInux LOader LILO),
- chargement du noyau de Linux,
- exécution du programme « init » et initialisation des périphériques,
- chargement des extensions et des services.
Nous appelerons, à l’avenir le processus d’initialisation: processus de « BOOT » (c’est plus court…)
- Le BIOS détermine le premier secteur à lire (disque dur, CDROM, disquette). On dit que le BIOS détermine le disque système. Démarrer sur une disquette est utile si :
- on désire démarrer une machine équipée avec Linux sans toucher à ce qui existe déjà sur le disque, (voir xtermkit),
- pour une opération de maintenance ou de réparation du système,
- pour démarrer sur un deuxième disque miroir quand le premier est tombé en panne.
- chargement du bootstrap. Le bootstrap tient sur un secteur et contient le chargeur. Voir le cours sur Lilo.
- le chargeur active le système d’exploitation (kernel) ou noyau de Linux qui peut être n’importe où sur le disque principal ou sur un autre disque. Le noyau est un « micro système » normalement compressé sur le disque. Il se décompresse automatiquement au chargement.
- Linux initialise le matériel et les périphériques puis lance le programme « init ». Ce programme est dans /sbin, init utilise le fichier /etc/inittab
- « init » a en charge l’exécution d’autres scripts et programmes.
Le processus de BOOT d’un peu plus près.
- sur une disquette de Boot, il n’y a pas nécessairement de système de fichiers,
- le programme du secteur de Boot lit les secteurs séquentiellement pour charger le noyau,
- si la disquette contient un SGF, on utilise un autre procédé comme LILO.
- avec des disques durs, le disque principal contient un Master Boot Record, car un disque peut avoir plusieurs partitions, chacune ayant un Partition Boot Record (PBR),
- le MBR lit la table des partitions pour déterminer la partition bootable et lit le PBR,
- le PBR est un programme qui tient sur un seul secteur, ce programme initialise le système d’exploitation. Le rôle est similaire au processus de boot d’une disquette.
- comme un disque contient un SGF, le Boot record doit accéder à des secteurs. Pour cela on utilise Lilo,
- le noyau détecte le SGF et monte ensuite le système de fichier « root ».
- charge normalement le système d’exploitation par défaut,
- peut être configuré pour:
- charger d’autres noyaux de Linux que celui par défaut,
- charger d’autres systèmes d’exploitation,
- attendre au démarrage une commande de l’utilisateur.
- utiliser la combinaison de touche ALT CTRL SHIFT quand Lilo est chargé,
- les messages de la phase de démarrage sont journalisés dans /var/log,
- les messages sont consultables avec la commande « dmesg »
Voir le cours sur Lilo pour en savoir plus
Si tout s’est bien passé jusque-là, le noyau lance le programme « init »
Le fichier de configuration d’init /etc/inittab spécifie que le premier script à exécuter /etc/init.d/rcS. Ce script lance tous les scripts de /etc/rcS.d/ pour exécuter des initialisations, comme la vérification et le montage des systèmes de fichiers, le chargement des modules, le démarrage des services réseau, le réglage de l’horloge, et l’exécution d’autres initialisations. Ensuite, pour compatibilité, il lance aussi les fichiers (sauf ceux ayant un « . » dans leur nom) de /etc/rc.boot/. Les scripts de ce dernier répertoire sont habituellement réservés à l’administrateur système, et leur utilisation dans des paquets est obsolète.
- le programme init est dans /sbin
- init est chargé de lancer les daemons (ftp, nfs, gettys, …)
- il y a plusieurs versions d’init (BSD, System V)
- BSD a ses fichiers de configuration dans /etc
- System V a ses fichiers dans un sous-répertoire de /etc/rc.d
- init System V tend à devenir le standard sous Linux
43.6.1. Le répertoire /etc/rc.d
Contient le fichier rc.sysinit et les répertoires suivants:
- init.d
- rc0.d
- rc1.d
- rc2.d
- rc3.d
- rc4.d
- rc5.d
- rc6.d
- Le répertoire rc.d peut contenir également les fichiers rc.local, rc.serial, rc.news, …
- le répertoire init.d contient un script par service lancé au démarrage (nfs, ftp, inet, …)
- les répertoires rc0.d à rc6.d correspondent aux programmes qui seront chargés en fonction du niveau d’exécution de Linux que nous allons voir.
43.6.2. Séquences du programme init
- le noyau charge init,
- init exécute dans l’ordre,
- /etc/rc.d/rc.sysinit,
- les scripts nécessaires pour la configuration /etc/rc.d/rcx.d
- /etc/rc.d/rc.local
Remarque
- les scripts exécutés dépendent du niveau d’exécution de Linux,
- sinon c’est une configuration par défaut qui est sélectionnée.
43.6.3. Le niveaux d’exécution (runlevels)
- 0 sert pour l’arrêt du système (ne pas mettre ce niveau par défaut)
- 1 sert pour le mode mono utilisateur
- 2 mode multi utilisateurs et réseau (sans NFS)
- 3 mode multi utilisateurs et réseau
- 4 ne sert pas
- 5 demarrer avec l’environnement graphique (proposer un environnement)
- 6 sert pour rebooter le système (ne pas mettre ce niveau par défaut)
43.6.4. Le niveau d’exécution par défaut
- par défaut le niveau 3 – mode multi utilisateurs
- défini dans /etc/inittab id:3:initdefault:
Suivant la distribution, ce niveau par défaut peut être différent
- Debian : 2
- Mandrake : 5
Le fichier contient une suite d’instructions sous la forme:code:niveau d’action:action:commande Exemple: configurer le mode « single user » cl1:1:wait:/etc/rc.d/rc 1 Pour en savoir plus sur les niveaux d’actions respawn, wait, once, boot, … de lancement des commandes, voir man inittab
Un exemple de /etc/inittab
# Le niveau d’exécution par défaut
id:2:initdefault:
# Initialisation du système
si::sysinit:/etc/rc.d/rc.sysinit
# Les différents niveaux d’exécution
l0:0:wait:/etc/rc.d/rc 0
l1:1:wait:/etc/rc.d/rc 1
l2:2:wait:/etc/rc.d/rc 2
l3:3:wait:/etc/rc.d/rc 3
l4:4:wait:/etc/rc.d/rc 4
l5:5:wait:/etc/rc.d/rc 5
l6:6:wait:/etc/rc.d/rc 6
# Intercepter les touches CTRL-ALT-DELETE
ca::ctrlaltdel:/sbin/shutdown -t3 -r now
# Démarrer en mode graphique sous xdm
x:5:respawn:/opt/kde/bin/kdm -nodaemon
# Arrêt de la machine 2 mn après le signal donné par l’UPS s’il y a une coupure d’electricité.
pf::powerfail:/sbin/shutdown -f -h +2 « Power Failure; System Shutting Down »
# Annulation de l’arrêt si l’électricité est rétablie.
pr:12345:powerokwait:/sbin/shutdown -c « Power Restored; Shutdown Cancelled »
# Création des différentes consoles (CTRL ALT F[1-6])
1:2345:respawn:/sbin/mingetty tty1
2:2345:respawn:/sbin/mingetty tty2
3:2345:respawn:/sbin/mingetty tty3
4:2345:respawn:/sbin/mingetty tty4
5:2345:respawn:/sbin/mingetty tty5
6:2345:respawn:/sbin/mingetty tty6
43.8. Contenu d’un répertoire rcx.d
Extrait:
[root@pastorius root]# ll /etc/rc2.d/
total 0
lrwxrwxrwx 1 root root 18 oct 2 15:44 S10sysklogd -> ../init.d/sysklogd*
lrwxrwxrwx 1 root root 15 oct 2 15:44 S11klogd -> ../init.d/klogd*
lrwxrwxrwx 1 root root 13 oct 2 15:44 S14ppp -> ../init.d/ppp*
lrwxrwxrwx 1 root root 15 oct 2 21:06 S15bind9 -> ../init.d/bind9*
lrwxrwxrwx 1 root root 20 oct 2 16:35 S19nfs-common -> ../init.d/nfs-common*
lrwxrwxrwx 1 root root 13 oct 2 21:06 S19nis -> ../init.d/nis*
lrwxrwxrwx 1 root root 14 oct 2 15:44 S20postfix -> ../init.d/postfix*
lrwxrwxrwx 1 root root 13 oct 6 22:28 S20gpm -> ../init.d/gpm*
lrwxrwxrwx 1 root root 15 oct 2 15:44 S20inetd -> ../init.d/inetd*
lrwxrwxrwx 1 root root 13 oct 2 16:35 S20lpd -> ../init.d/lpd*
lrwxrwxrwx 1 root root 17 oct 2 15:44 S20makedev -> ../init.d/makedev*
lrwxr-xr-x 1 root root 16 oct 11 00:21 S20pcmcia -> ../init.d/pcmcia*
lrwxrwxrwx 1 root root 13 oct 2 16:35 S20ssh -> ../init.d/ssh*
lrwxrwxrwx 1 root root 16 oct 2 21:07 S20webmin -> ../init.d/webmin*
lrwxrwxrwx 1 root root 13 oct 3 02:15 S20xfs -> ../init.d/xfs*
lrwxrwxrwx 1 root root 17 oct 5 01:37 S20xfs-xtt -> ../init.d/xfs-xtt*
lrwxrwxrwx 1 root root 25 oct 2 21:07 S25nfs-user-server -> ../init.d/nfs-user-server*
lrwxrwxrwx 1 root root 17 oct 2 20:41 S50proftpd -> ../init.d/proftpd*
lrwxrwxrwx 1 root root 13 oct 2 15:44 S89atd -> ../init.d/atd*
lrwxrwxrwx 1 root root 14 oct 2 15:44 S89cron -> ../init.d/cron*
lrwxrwxrwx 1 root root 16 oct 2 21:06 S91apache -> ../init.d/apache*
lrwxrwxrwx 1 root root 13 oct 2 16:36 S99gdm -> ../init.d/gdm*
lrwxrwxrwx 1 root root 13 oct 3 01:12 S99kdm -> ../init.d/kdm*
lrwxrwxrwx 1 root root 19 oct 2 15:44 S99rmnologin -> ../init.d/rmnologin*
lrwxrwxrwx 1 root root 13 oct 3 02:15 S99xdm -> ../init.d/xdm*
Ce répertoire contient des liens logiques vers des scripts qui sont dans /etc/rc.d/init.d/
43.9. Comment choisir un mode d’exécution
- Vous pouvez modifier le mode par défaut dans /etc/inittab,
- ou lors du démarrage de Linux à l’affichage du prompt « boot »
- exemple « linux single » ou « linux 1 »
- cette méthode permet parfois le dépannage
43.10. Utilitaires de configuration
- configuration manuelle à l’aide d’un éditeur et/ou des commandes
- en environnement graphique:
- sous KDE ou gnome
- linuxconf,
- le control-panel.
- webmin https://localhost:10000/
43.11. Arrêter ou démarrer un service
En mode commande
- root:~# /etc/init.d/NomDuService stop
- root:~# /etc/init.d/NomDuService start
- root:~# /etc/init.d/NomDuService status (pour certains)
- root:~# /etc/init.d/NomDuService (vous donne l’usage)
En mode graphique
- ksysv
- contrôle center/système/services
43.12. Ajout ou suppression d’un service
- chkconfig –level 3 smb off (sous Mandrake, RedHat)
- update-rc.d -f ntp remove (sous Debian)
43.13. Placer une commande au démarrage du système
- Si vous voulez qu’une commande soit exécutée à chaque lancement, vous pouvez utiliser le script rc.local,
- ce script est exécuté en dernier, il vous permettra d’adapter la configuration de votre système.
Procédure
- signaler à tous les processus de se terminer pour fermer proprement les fichiers,
- démonter tous les systèmes de fichiers et partitions de swap,
- message d’avertissement du système « system halted »,
- couper l’alimentation
Attention
- ne pas utiliser cette procédure peut entraîner des pertes de données,
- ne pas utiliser « halt » ou « reboot » mais « shutdown »,
- l’opération est réalisée sur la console système ou par planification « cron »,
- limiter aux administrateurs.
Procédure
- Pour arrêter le système immédiatement
- root:~# shutdown -h now (h pour halt)
- Pour arrêter et relancer le système
- root:~# shutdown -r now (r pour reboot)
- Arrêter le système et prévenir les utilisateurs par un message
- root:~# shutdown -h+10 « les services réseaux vont s’arrêter et reprendre dans 2 heures »
- les utilisateurs auront un message sur leur console et auront le temps de quitter leur session.
La disquette de BOOT et Root
43.16.1. Création des disquettes
43.16.1.1. La disquette de Boot
Il existe plusieures solutions, dont l’utilitaire « mkbootdisk »
- relever la version de votre système « uname -r »
- supposons que la commande ait retourné 2.4.28
- tapez root:~# mkbootdisk –device /dev/fd0 2.4.18
43.16.1.2. La disquette de Root
Les distributions de Linux proposent souvent une disquette Root ou Rescue
- root:~# mount /mnt/cdrom /* monter le lecteur */
- root:~# cd /mnt/cdrom/images /* si les images de disquettes sont dans ce répertoire */
- tapez root:~# mkbootdisk –device /dev/fd0 2.4.18
- tapez root:~# dd if=rescue.img of=/dev/fd0 bs 1440 /* si l’image s’appelle rescue.img */
Dans tous les cas , testez les disquettes.
43.17.1. Mot de passe de root oublié
Le mot de passe de root est oublié ou on ne peut plus se logger
- booter avec les disquettes de Boot et de Root,
- ouvrez une session root (pas besoin de mot de passe),
- monter le disque dur exemple
root:~# mount -t ext2 /dev/sda1 /mnt
- modifiez le fichier /mnt/etc/passwd.
Cet exemple montre trois choses:
- ces disquettes peuvent être utiles,
- il ne faut pas laisser une machine critique en libre accès,
- il faut savoir utiliser vi.
43.17.2. Démarrer en « single user »
Au message boot: entrez
- boot: linux single root=/dev/hdxx initrd=initrd-2.4.18.img
- Charger le clavier suisse romand : loadkeys /usr/lib/kbd/keymaps/i386/qwertz/fr_CH-latin1.kmap.gz
- monter la racine :
root:~# mount -w -n -o remount /
Remarques:
- adapter /dev/hdxx au nom de votre disque
- pour le détail des options : man mount
Vous devez maintenant être en mesure:
- d’expliquer le processus de démarrage de Linux,
- modifier ce processus,
- créer une disquette de dépannage de Boot et de Root,
- dépanner un problème d’amorçage de Linux.
Chapter 44. TP : Sytème de gestion de fichiers
Ce TP va vous guider dans la manipulation des systèmes de fichiers.
A partir d’une distribution Debian GNU/Linux
Lisez attentivement ce document une première fois sans lancer les commandes.
Lisez également les pages de manuel des commandes avec man et info.
Sur une machine en runlevel 2 ou 5, relevez les daemons qui tournent sur votre système
root:~# ps axf
relevez également les informations concernant la mémoire
root:~# free
passer en mode maintenance c’est à dire en runlevel 1
root:~# init 1 # ou
root:~# telinit 1
man : ps runlevel free init inittab
Ajout d’un fichier swap de 10MB
root:~# mkdir /usr/local/fs
root:~# cd /usr/local/fs
root:~# dd if=/dev/zero of=test_swap bs=512 count=208000
root:~# mkswap test_swap
root:~# swapon test_swap -p 1
root:~# cat /proc/swaps
ajoutez dans /etc/fstab
/usr/local/fs/test_swap none swap sw,pri=1 0 0
au prochain reboot l’espace d’échange sera automatiquement chargé
man : dd mkswap swapon swapoff fstab
ajoutez 2 partitions de 2GB avec fdisk ou cfdisk et formatez les en type ext3
root:~# mkfs.ext3 /dev/hdax
root:~# mkfs.ext3 /dev/hday
root:~# mkdir /mnt/data1 /mnt/data2
ajoutez dans /etc/fstab
root:~# /dev/hdax /mnt/data1 ext3 defaults 0 2
root:~# /dev/hday /mnt/data2 ext3 defaults 0 2
montez les partitions
root:~# mount -a
faites une synchro vers le nouveau répertoire home
root:~# rsync -av /home/ /mnt/data1/home
faire un backup de home
root:~# mkdir /mnt/data2/backup
root:~# cd /mnt/data2/backup
root:~# tar czvf home-backup.tgz /home/
supprimer /home
root:~# rm -rf /home/
faire un lien symbolique vers le nouveau répertoire home
root:~# ln -s /mnt/data1/home /home
une autre possibilité aurait été de monter /dev/hdax dans un point de montage temporaire /mnt/tmp par exemple, de faire la synchro et le backup, supprimer le contenu de /home et monter /dev/hdax sur /home que l’on aura recréé
man : mkfs fstab mount tar rsync
Création d’un système virtuel de fichiers
root:~# mkdir /mnt/virtualfs
root:~# cd /usr/local/fs
Création du fichier destiné à la création du système de fichier
root:~# dd if=/dev/zero of=test_ext3fs bs=512 count=208000
Formatage
root:~# mkfs.ext3 test_ext3fs
Montage
root:~# mount -o loop -t ext3 -v test_ext3fs /mnt/virtualfs
écrire dans fstab
/usr/local/fs/test_ext3fs ext3 defaults 0 2
Copie de fichiers dans le nouveau système de fichiers
root:~# rsync -av /home/ /mnt/virtualfs/home
Affichage de la liste des fichiers
root:~# find /mnt/virtualfs
Démontage du système virtuel de fichiers
root:~# umount /mnt/virtualfs
44.3.1. Alternative permettant de choisir le device loop
root:~# losetup /dev/loop1 test_ext3fs
root:~# mount -v -t ext3 /dev/loop1 /mnt/virtualfs
root:~# find /mnt/virtualfs
root:~# umount /mnt/virtualfs
root:~# losetup -d /dev/loop1
la même chose en crypté (n’est pas l’objet du cours)
root:~# losetup -e aes /dev/loop0 test_ext3fs
root:~# mkfs.ext3 /dev/loop0
root:~# mount -t ext3 -v /dev/loop0 /mnt/virtualfs
root:~# rsync -av /home/ /mnt/virtualfs/home
root:~# find /mnt/virtualfs
root:~# umount /mnt/virtualfs
root:~# losetup -d /dev/loop0
root:~# mount -t ext3 -v -o loop,encryption=aes test_ext3fs /mnt/virtualfs
monter des images de CDROM et/ou DVD sans lecteur.
root:~# cd /usr/local/fs
copie de l’image du CDROM dans un fichier
root:~# cp /dev/cdrom image.iso
calcul de l’empreinte digitale de l’image du CDROM et de l’image
root:~# md5sum /dev/cdrom && md5sum image.iso
vérifiez que les deux empreintes sont identiques
root:~# mkdir /mnt/virtualcdrom
root:~# mount -o loop -t iso9660 -v image.iso /mnt/virtualcdrom
vous pouvez ensuite ajouter cette entrée dans la fstab pour avoir votre cdrom virtuel en permanence, idéal par exemple pour avoir plusieurs cd d’installation à disposition.
/usr/local/fs/image.iso iso9660 loop,noauto,ro,exec 0 0
arrêtez la machine
root:~# init 0
redémarrez et à l’invite du boot , saisissez :
boot: linux single ou linux 1
Modifier le runlevel de façon à démarrer en mode graphique en niveau 5 et non en niveau 2. Utiliser pour cela la commandeupdate-rc
passer en mode multi-utilisateurs
root:~# init 2
vérifiez que vos points de montage soient corrects
root:~# df -a
Chapter 45. CVS : Concurrent Version System
CVS (Concurrent Version System) permet une simplification de la gestion de projets pour le travail en groupe, conserve l’historique de toutes les modifications effectuées sur un fichier permettant ainsi une traçabilité totale.
CVS est un système de contrôle de versions de fichiers, il permet de conserver les modifications successives des fichiers placés sous son contrôle (généralement du code source) et de conserver l’historique des changements et de leur description. Il permet également de gérer l’édition de fichiers par plusieurs auteurs en parallèle et de gérer les conflits possibles, de déclencher des actions (mail, scripts, …) à différents moments du cycle de vie des fichiers.
L’horloge du serveur et toutes les machines clientes devront être synchronisées à l’aide de NTP (voir le cours sur NTP), en effet CVS se sert de l’heure et de la date pour effectuer ses opérations et cela est capital pour l’intégrité de la base CVS.
Le dépôt est la base centralisée de CVS à savoir les fichiers d’administration se trouvant dans le sous dossier CVSROOT ainsi que les dossiers des différents projets (livres, développements, sites web, …). Ce répertoire peut se trouver n’importe où sur le système de fichiers (ex: /usr/local/cvsroot) et le path pour l’atteindre doit être défini dans la variable d’environnement $CVSROOT. Afin que chaque utilisateur d’un groupe de travail puisse travailler sur un projet, le dossier ($CVSROOT/nom_projet) devra avoir les droits en lecture et écriture sur le groupe ainsi que le bit s positionné (garanti que chaque fichier/dossier cré appartient au groupe), il en sera de même pour /var/lock/cvs/nom_projet.
45.3.1. Initialisation du dépôt
Dans le cas ou vous installez CVS pour la première fois, ou que vous n’avez pas de dépôt. Une fois la variable d’environnement CVSROOT définie lancez la commande
mkdir /usr/local/cvsroot
cvs init
ou pour plus de contrôle sur la création du dépôt
cvs -d /usr/local/cvsroot init
chown -R cvs:cvs /usr/local/cvsroot
chmod g+rwxs /usr/local/cvsroot/CVSROOT
Pour les accès en mode connecté, vous devrez ensuite créer le fichier $CVSROOT/CVSROOT/passwd ayant la structure suivante:
login_CVS:[mot_de_passe_crypt][:login_systeme]
ce fichier étant particulièrement sensible il est préférable de ne pas mettre les mêmes mots de passe que ceux pour se connecter au serveur et de donner les droit suivants au fichier passwd de cvs.
chmod 400 $CVSROOT/CVSROOT/passwd
c’est un des rares cas où vous irez modifier un fichier dans $CVSROOT/CVSROOT. L’accès se fait par l’utilisation des commandes CVS.
Accédez au serveur avec un utilisateur faisant partie du groupe cvs.
mkdir ~/Projets/
cd ~/Projets/
cvs -d /usr/local/cvsroot checkout CVSROOT
si la variable CVSROOT est définie l’option -d /usr/local/cvsroot est facultative
-rw-rw-r– 1 jmj jmj 495 mai 17 01:49 checkoutlist
-rw-rw-r– 1 jmj jmj 760 mai 17 01:49 commitinfo
-rw-rw-r– 1 jmj jmj 986 mai 17 02:35 config
drwxr-xr-x 2 jmj jmj 4096 mai 23 19:01 CVS/
-rw-rw-r– 1 jmj jmj 602 mai 17 01:49 cvswrappers
-rw-rw-r– 1 jmj jmj 1025 mai 17 01:49 editinfo
-rw-rw-r– 1 jmj jmj 1141 mai 17 01:49 loginfo
-rw-rw-r– 1 jmj jmj 1151 mai 17 01:49 modules
-rw-rw-r– 1 jmj jmj 564 mai 17 01:49 notify
-rw-rw-r– 1 jmj jmj 649 mai 17 01:49 rcsinfo
-rw-rw-r– 1 jmj jmj 879 mai 17 01:49 taginfo
-rw-rw-r– 1 jmj jmj 1026 mai 17 01:49 verifymsg
Modifiez le fichier config :
cd CVSROOT
vi config
# Exemple de fichier config
SystemAuth=no
LockDir=/var/lock/cvs
TopLevelAdmin=no
LogHistory=TOEFWUPCGMAR
RereadLogAfterVerify=always
Validez les modifications
cvs commit -m « Configuration initiale de CVS » config
L’accès à cette base CVS peut s’effectuer de 5 manières différentes:
Les fichiers dans ce cas doivent être accessible directement au travers du système de fichier ou d’un système de fichier réparti tel que NFS ou SMB. Dans ce cas nous utilisons CVS en mode non connecté.
CVSROOT=:local:/usr/local/cvsroot ou CVSROOT=/usr/local/cvsroot
Le serveur CVS est en attente des requêtes clientes, sur le port TCP 2401. A ajouter dans /etc/services:
cvspserver 2401/tcp # CVS client/server operations
dans /etc/inetd.conf si vous utilisez inetd
cvspserver stream tcp nowait cvs /usr/bin/cvs cvs –allow-root=/usr/local/cvsroot pserver
pour qu’inetd prenne en compte les changements dans son fichier de configuration
killall -HUP inetd
si vous utilisez xinetd
# CVS configuration for xinetd don’t forget to specify your CVSROOT in
# /etc/cvs/cvs.conf.
service cvspserver
{
disable = no
socket_type = stream
protocol = tcp
wait = no
user = root
passenv = PATH
server = /usr/sbin/cvspserver
server_args = -f –allow-root=/usr/local/cvsroot pserver
}
pour que xinetd prenne en compte les changements
killall -HUP xinetd
Sur la machine cliente définir la variable CVSROOT
CVSROOT=:pserver:user@server:/usr/local/cvsroot
L’authentification est réalisée grâce à la commande :
cvs login
qui enregistrera le mot de passe sous forme chiffrée dans le fichier .cvspass si la connexion est acceptée (pour changer le nom du fichier.cvspass, définissez le dans $CVS_PASSFILE). Pour que la connexion aboutisse, ce fichier devra également exister dans $CVROOT/passwd
L’algorithme ci-dessous explicite l’utilisation que fait pserver de ces fichier pour décider d’accorder un droit d’accès en lecture seule ou en lecture-écriture à l’utilisateur user.
SI user n’existe pas dans le fichier passwd OU son mot de passe est incorrect ALORS -> ACCES REFUSÉ
SINON SI le fichier readers existe ET user y figure ALORS -> ACCES LECTURE SEULE
SINON SI le fichier writers existe ET user n’y figure pas ALORS -> ACCES LECTURE SEULE SINON -> ACCES LECTURE-ÉCRITURE FINSI
Le serveur CVS est en attente sur le port TCP 1999 ajoutez dans /etc/services:
cvskserver 1999/tcp
dans inetd.conf
cvskserver stream tcp nowait cvs /usr/bin/cvs cvs –allow-root=/usr/local/cvsroot kserver
Sur la machine cliente définir la variable CVSROOT
CVSROOT=:kserver:server:/usr/local/cvsroot
sur la machine cliente utilisez kinit pour obtenir un ticket kerberos vous permettant ensuite de vous connecter et d’utiliser les commandes cvs.
Permet d’accéder à des systèmes sécurisés tel que kerberos 5. CVS et ses outils auront été compilés préalablement en incluant le support GSSAPI (option –with-gssapi). Ce mode est équivalent au mode serveur et utilise également le fichier $CVSROOT/passwd. Par défaut les communications ne sont ni authentifiées ni chiffrées et il faudra utiliser des options spéciales de CVS (voir détail des commandes man et info). Sur la machine cliente définir la variable CVSROOT
CVSROOT=:gserver:server:/usr/local/cvsroot
Dans ce mode le client accède au serveur en utilisant rsh. Sur la machine cliente définir la variable CVSROOT
CVSROOT=:ext:user@server:/usr/local/cvsroot
Vérifier que la commande rsh fonctionne indépendamment de cvs.
rsh -l user server uname -a
Il faudrait configurer rsh pour ne pas demander à chaque fois le mot de passe (.rhosts ou encore host.equiv), mais cette méthode n’est pas du tout sécurisée, nous utiliserons ssh en remplacement de rsh. Définissez la variable d’environnement CVS_RSH
CVS_RSH=ssh
Vous devrez mettre votre clef publique dans ~/.ssh/authorized_keys sur le serveur pour ne plus entrer le mot de passe à chaque fois. Nous retiendrons ce mode ou shell sécurisé utilisant kerberos pour toutes communications distantes afin d’éviter d’exposer votre système à des attaques, en chiffrant les connexions et les transferts de données.
# depuis le poste client
$ ssh-keygen -t dsa # PubkeyAuthentication : clé DSA pour SSH2
$ cat .ssh/id_dsa.pub | ssh user1@remote \
« cat – >>.ssh/authorized_keys[2] »
Chaque projet que vous ajoutez dans CVS correspond à un module. Pour ajouter un module
mkdir /usr/local/cvsroot/nom_projet && mkdir /var/lock/cvs/nom_projet
chowm cvs:groupe_du_projet /usr/local/cvsroot/nom_projet /var/lock/cvs/nom_projet
chmod g+rwxs /usr/local/cvsroot/nom_projet /var/lock/cvs/nom_projet
45.4. Les commandes principales de CVS
- cvs login (pour se connecter en mode client server)
- cvs logout (pour se déconnecter en mode client server)
- cvs import -m « Liste nouveaux composants » nom_projet/HOWTO LFO V1 (ajoute les fichiers du répertoire courant avec le vendeur-tag LFO et le release-tag V1, sans avoir de copie de travail et évite de recourir aux sous-commandes add et commit pour tous les fichiers et répertoires ajoutés)
- cvs checkout nom_projet (récupère en local le module nom_projet)
- cvs update (met à jour les fichiers de la copie de travail en local)
- cvs status -v nom_fichier (visualise l’état et les noms de versions symboliques du fichier)
- cvs -n update (idem que cvs status mais les informations sont plus condensées)
- cvs add -m (ajout de la procédure d’installation » INSTALL, ajoute le fichier INSTALL)
- cvs remove -f nom_fichier (supprime physiquement et dans la base CVS nom_fichier), pour être validée cette commande devra être suivie d’un cvs commit
- cvs commit -m « première version » index.html (archive la version dans CVS)
- cvs export -k v -d version_prod -r STABLE-V1_1 nom_projet (extrait une copie du module nom_projet dans le répertoire projet_v1_1 sans les répertoires de gestion utilisés par CVS)
- cd nom_projet/srv_server & cvs tag SRV-V1_0 (défini le nom symbolique SRV-V1_0 pour tous les fichiers de nom_projet/srv_server)
- cvs co -r SRV-V1_0 nom_projet/srv_server (récupère les fichiers ayant le tag SRV-V1_0 de nom_projet/srv_server)
- cvs rtag SRV-V2_0 nom_projet (défini le nom symbolique SRV-V2_0 à la dernière version présente dans la base des fichiers du module nom_projet)
- cvs diff –ifdef=V1_2 -r1.1 -r1.3 index.html (affiche les différences entre les versions 1.1 et 1.3 en séparant les modifications par le symbole préprocesseur V1_2)
- cvs rdiff -s -r STABLE-V1_0 nom_projet (résume les différences entre la version STABLE-V1_0 et la dernière version en base)
- cvs rdiff -u -r STABLE-V1_0 nom_projet (visualise les différences)
- cvs release -d nom_projet (vérifie que toutes vos modifications sont archivées et indique à CVS que vous n’utilisez plus votre copie de travail)
Chapter 46. Travaux pratiques : Concurrent Version System
CVS (Concurrent Version System) permet une simplification de la gestion de projets pour le travail de groupe, conserve l’historique de toutes les modifications effectuées sur un fichier permettant ainsi une traçabilité totale.
- Installer et configurer CVS
- Gestion d’un projet en mode non connecté
- Gestion d’un projet en mode connecté
46.2. Installer et configurer CVS
Cette première partie vous indique comment installer et configurer un Serveur CVS
apt-get install cvs
dans /etc/profile et/ou ~/.bashrc ~/.bash_profile ajoutez
CVSROOT=/usr/local/cvsroot
export CVSROOT
création du répertoire d’archive cvs
mkdir /usr/local/cvsroot
Ajoutez un utilisateur cvs et groupe cvs sans mot de passe et shell, vous ajouterez les administrateurs cvs dans son groupe. Initialisation de l’archive (cette action ne doit s’effectuer qu’une seule fois)
cvs -d /usr/local/cvsroot init
chown -R cvs:cvs /usr/local/cvsroot
chmod g+rwxs /usr/local/cvsroot/CVSROOT
mkdir /var/lock/cvs/CVSROOT
chown -R cvs:cvs /var/lock/cvs/CVSROOT
chmod g+rwxs /var/lock/cvs/CVSROOT
Les principaux fichiers d’administration de cvs sont maintenant créés
ls -lR /usr/local/cvsroot/*
/usr/local/cvsroot/CVSROOT:
total 14
-r–r–r– 1 cvs cvs 495 mai 17 01:49 checkoutlist
-r–r–r– 1 cvs cvs 760 mai 17 01:49 commitinfo
-r–r–r– 1 cvs cvs 991 mai 17 01:49 config
-r–r–r– 1 cvs cvs 602 mai 17 01:49 cvswrappers
-r–r–r– 1 cvs cvs 1025 mai 17 01:49 editinfo
drwxrwxr-x 2 cvs cvs 4096 mai 17 01:49 Emptydir/
-rw-rw-rw- 1 cvs cvs 68 mai 17 02:00 history
-r–r–r– 1 cvs cvs 1141 mai 17 01:49 loginfo
-r–r–r– 1 cvs cvs 1151 mai 17 01:49 modules
-r–r–r– 1 cvs cvs 564 mai 17 01:49 notify
-r–r–r– 1 cvs cvs 649 mai 17 01:49 rcsinfo
-r–r–r– 1 cvs cvs 879 mai 17 01:49 taginfo
-rw-rw-rw- 1 cvs cvs 0 mai 17 01:49 val-tags
-r–r–r– 1 cvs cvs 1026 mai 17 01:49 verifymsg
Les fichiers d’administration ne doivent pas être édités directement dans l’archive mais en faisant un checkout du dossier CVSROOT (premier module de CVS)
mkdir cvs_admin && cd cvs_admin
cvs -d /usr/local/cvsroot checkout CVSROOT
cd CVSROOT
éditez le fichier config et prenez en connaissance.
# Pour faciliter les tests dans un premier temps nous mettrons l’option suivante à no
# afin que pserver ne contrôle pas users/passwords
SystemAuth=no
# Nous mettrons les fichiers de lock en dehors du repository de CVS.
LockDir=/var/lock/cvs
# Par de création au toplevel
TopLevelAdmin=no
# Toutes les transactions dans le fichier d’historique
LogHistory=TOEFWUPCGMAR
# On autorise le script verifymsg de changer le message de log.
RereadLogAfterVerify=always
envoyez vos modifications au serveur
cvs commit
libérez l’archive
cd ..
cvs release -d CVSROOT
46.3. Gestion d’un projet en mode non connecté
Vos projets sont connus sous le terme de module dans CVS. Création du module test
mkdir /usr/local/cvsroot/test
chowm user:groupe /usr/local/cvsroot/test
chmod g+rwxs /usr/local/cvsroot/test
mkdir /var/lock/cvs/test
chowm user:groupe /var/lock/cvs/test
chmod g+rwxs /var/lock/cvs/test
créez votre répertoire de travail
cd ~
mkdir -p Projets/test/
copiez quelques fichiers de configuration de /etc/ dans Projets/test/
cd Projets/test && cp /etc/host* .
importez votre projet
cvs -d /usr/local/cvsroot import -m « Création du module test » test LFO V1
cd .. && rm -rf test/ && ls -la
cvs -d /usr/local/cvsroot co test
cd test && ls -la
Editez le fichier hosts et apportez y quelques modifications, validez vos modifications
cvs commit
cvs status
dans un terminal connectez-vous avec un utilisateur différent
mkdir -p Projets
cvs -d /usr/local/cvsroot co test
ajoutez des fichiers au projet test
cp /etc/aliases . && cp /etc/fstab .
cvs add aliases fstab
cvs commit -m « ajout du fichier aliases et fstab » aliases fstab
liberez votre archive
cd ..
cvs release -d test
retournez sur le compte utilisateur initial
cd Projets/test
cvs -n update
cvs update
liberez votre archive
cd ..
cvs release -d test
46.4. Gestion d’un projet en mode connecté
Définissez maintenant les variables suivantes (server étant le nom ou l’adresse ip d’une machine distante et user votre compte sur cette dernière) votre clef publique ssh devra se trouver dans le fichier authorized_keys de la machine distante, afin de ne pas devoir ressaisir le mot de passe à chaque action de cvs. pour plus de détails voir le cours sur ssh, ainsi que les pages de manuel.
CVSROOT=:ext:user@server:/usr/local/cvsroot
CVS_RSH=ssh
ajouter dans /etc/services:
cvspserver 2401/tcp
dans /etc/inetd.conf
cvspserver stream tcp nowait cvs /usr/bin/cvs cvs –allow-root=/usr/local/cvsroot pserver
forcez inetd à prendre en compte les modifications
killall -HUP inetd
récupérez le module test du serveur distant
cd Projets
cvs co test
Un annuaire électronique est une solution permettant la création d’une collection d’objets. Dans les réseaux, les annuaires permettent à l’échelle d’une entreprise de déclarer tous les objets (utilisateurs, applications, équipements matériels…), et pour chaque objet de définir ses propriétés (attributs).
Cela permet d’avoir un recensement de tous les objets dans une base de données. Cette base étant, le plus souvent répartie. Novell, Microsoft utilisent des bases de données d’annuaires (respectivement les NDS Netware Directory Services et AD Active Directory) pour la manipulation des ressources sur leurs réseaux.
Les annuaires sont ensuites accessibles à partir de tous types d’applications (outlook, mozilla, konqueror…), mais aussi par les processus d’identification/authentification, les processus systèmes…
LDAP (Light Directory Access Protocol) est un service d’annuaire dérivé de la norme X.500. La norme X.500 est très lourde, LDAP en est une version allégée (« light ») dans un sens absolument pas péjoratif.
Vous trouverez de bien meilleures descriptions du principe, concept et du protocole LDAP en suivant les références indiquées à la fin de ce document.
Un serveur LDAP permet de centraliser des informations très diverses. Il offre de nombreux avantages :
- un serveur d’annuaire (recensement de tous les objets d’un système) : c’est la fonction la plus connue, on peut trouver des serveurs LDAP chez bigfoot, netscape (netcentrer), infoseek et bien d’autres ;
- Information sur les utilisateurs (nom, prénom…), et données d’authentification pour les utilisateurs : cela permet aussi la définition de droits.
- Information pour les applications clientes et fonctions de serveur d’accès itinérant : cela permet de stocker ses informations personnelles sur un serveur et de les récupérer lors de la connexion;
- bien d’autres choses…
LDAP supporte le chiffrement SSL et cohabite parfaitement avec les applications Samba, DNS, NFS… ce qui permet son utilisation pour des applications comme les serveurs de liste de diffusion(sympa par exemple).
L’objet de cette séquence sera de voir comment installer, configurer puis administrer un serveur LDAP. Nous utiliserons la distribution OpenLDAP disponible sur les distributions Linux
LDAP fournit un ensemble d’outils.
- un protocole permettant d’accéder à l’information contenue dans l’annuaire,
- un modèle d’information définissant l’organisation et le type des données contenues dans l’annuaire,
- un modèle de nommage définissant comment l’information est organisée et référencée
- un modèle fonctionnel qui définit comment accéder à l’information,
- un modèle de sécurité qui définit comment accéder aux données et comment celles-ci sont protégées. OpenLDAP est souvent configuré avec SASL (Simple Authentication and Security Layer), qui permet les transactions cryptées avec les protocoles fonctionnant en mode connecté.
- un modèle de duplication qui définit comment la base est répartie entre serveurs,
- des APIs pour développer des applications clientes,
- LDIF, (Ldap Data Interchange Format) un format d’échange de données.
Un protocole d’accès aux données, qui décrit comment ajouter, modifier, supprimer des données dans la base de donnée, quels protocoles de chiffrement (kerberos, ssl…), et quels mécanismes d’authentification sont utilisés. Ce protocole est utilisé dans la relation client/serveur, mais également entre serveurs (serveur/serveur) car une base de données LDAP peut être répartie.
47.2.2.1. Le Directory Information Tree
LDAP fournit un modèle d’organisation des données. Ces données sont organisées sous forme hiérarchique. L’arbre est nommé Directory Information Tree (DIT). Le sommet (racine), contient le « suffixe ». Chaque noeud représente une « entrée » ou « Directory Entry Service » (DSE). Les données sont stockées sur un format de base de données hiérarchique de type « dbm ». Ce format est différent des bases de données relationnelles, conçues pour supporter de multiples mises à jour. DBM est conçu pour supporter peu de mises à jour, mais de nombreuses consultations.
Figure 47-1. LDAP : le DIT Directory Information Tree
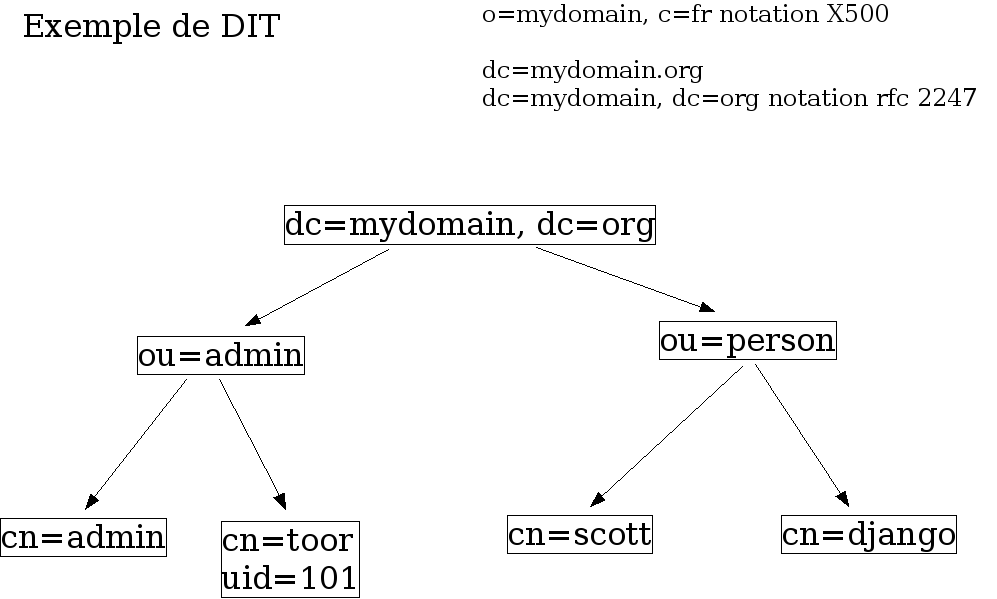
47.2.2.2. Classes d’objets, objets, attributs et schéma
Une entrée (DSE) dnas le DIT correspond à un objet abstrait (organisation, ressource) ou concret (personne, équipement…). Les objets possèdent une description dans une « classe d’objet ». Une classe d’objet donne une représentation modélisée des objets qu’elle représente en caractérisant tous les attributs des objets.
Certaines classes dobjet ont fait l’objet d’une normalisation et sont réutilisables. Elles sont définies par un nom, un OID (Object Identifier), la liste des attributs (facultatifs ou obligatoires), et, pour chaque attribut, un type. Le type est lié à la nature (essentiellement texte ou binaire) des attributs utilisés.
Une classe d’objet est définie par un nom, un OID (Object IDentifier), la liste des attributs (facultatifs et obligatoires), un type. Le type est lié à la nature des attributs utilisés.
Chaque objet est composé d’attributs en fonction des types d’attributs décrits dans les classes d’objets. Un attribut est généralement un couple clé/valeur, mais peut être caractérisé par un nom, un OID, s’il est mono ou multi-évalué, un indicateur d’usage (facultatif/obligatoire), un format (voir par exemple pour les images).
Les OID sont normalisés par la RFC2256 et sont issus d’un schéma X500. Les OID sont tenus à jour par l’IANA Internet Assigned Numbers Authority. Un OID est une séquence de chiffres séparés par un « . » point (Exemple 1.2.3.4 ) qui permet d’identifier de façon unique un élément du schéma LDAP.
Exemple de la la classe inetOrgPerson (dépend de organizationalPerson)
# The inetOrgPerson represents people who are associated with an
# organization in some way. It is a structural class and is derived
# from the organizationalPerson which is defined in X.521 [X521].
Objectclass ( 2.16.840.1.113730.3.2.2 <————– OID
NAME ‘inetOrgPerson’
DESC ‘RFC2798: Internet Organizational Person’
SUP organizationalPerson
STRUCTURAL
MAY (
audio $ businessCategory $ carLicense $ departmentNumber $
displayName $ employeeNumber $ employeeType $ givenName $
homePhone $ homePostalAddress $ initials $ jpegPhoto $
labeledURI $ mail $ manager $ mobile $ o $ pager $
photo $ roomNumber $ secretary $ uid $ userCertificate $
x500uniqueIdentifier $ preferredLanguage $
userSMIMECertificate $ userPKCS12 )
)
et l’attibut employeeType
# employeeType
# Used to identify the employer to employee relationship. Typical values
# used will be « Contractor », « Employee », « Intern », « Temp », « External », and
# « Unknown » but any value may be used.
Attributetype ( 2.16.840.1.113730.3.1.4
NAME ’employeeType’
DESC ‘RFC2798: type of employment for a person’
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
Signification des mots réservés :
DESC : Description
SUP : Objet parent
MUST : Attributs requis
MAY : Attributs possibles
Chaque objet de l’annuaire qui correspond à une classe d’objet est décrit par des valeurs en fonction des attributs qui décrivent la classe d’objets. Un attribut est généralement un couple clé/valeur, mais peut être caractérisé par un nom, un OID, indique s’il est mono ou multi-évalué, donne un indicateur d’usage (facultatif/obligatoire), impose un format (par exemple base64 pour les images, utf-8 pour les données).
Les objets sont rattachés obligatoirement à au moins une classe d’objet. Une classe d’objet caractérise ou modélise les objets qui lui seront rattachés. On en déduit qu’un objet ne pourra pas avoir d’attribut non déclaré dans la classe d’objet. Par contre dans la classe d’objet, un attribut pourra être soit optionnel, soit obligatoire. L’administrateur a déjà des classes d’objets prédéfinies, il a la possibilité d’en définir d’autres.
Chaque objet hérite des attributs des objets dont il hérite. Quand on décrit un objet « fils », on doit décrire tous les liens de parenté avec l’attribut « ObjetClass ». Les objets forment une hiérarchie, avec, au sommet, l’objet « top ». Exemple pour enrichir l’objet « person » des attributs « technicalPerson ».
objectClass: top
objectClass: myOrganization
objectClass: person
objectClass: technicalPerson
L’ensemble de la description des classes d’objet et des types d’attributs définissent le « schéma ».
Une entrée peut appartenir à plusieurs classes d’objets. Les attributs de l’objets sont la réunion des attributs de toutes les classes d’objets :
Entry Type Required Attributes Optional Attributes
person commonName (cn) mail
surName (sn) mobile
objectClass …
OrganizationUnit ou description
objectClass localisation
…
Organization o description
onjectClass …
Les OID sont normalisés par la RFC2256 et sont issus d’un schéma X55. Les OID sont tenus à jour par l’IANA Internet Assigned Numbers Authority. Un OID est une séquence de chiffres séparés par un « . » point. Exemple 1.2.3.4
Le « dn », ou Distinguished Name, est le chemin absolu de l’entrée dans le DIT à partir de la racine. Par exemple :
dc=org, dc=mydomaine, ou=person, uid=toor
On peut utiliser aussi un nommage « relatif » par rapport à une position courante. Dans ce cas on utilise le RDN (Relative Distinguished Name).
47.2.2.3. Le format d’échange de donnée LDIF
Le format d’échange permet l’import/export de données des bases, mais sert également pour l’ajout ou la modification. Les données sont en ASCII codées en UTF-8, sauf pour le binaire qui est codé en base64 (images par exemple).
Les fichiers au format LDIF respectent une structure de description des objets et des commandes :
Syntaxe générale :
dn: <distinguished name
objectClass: <object class
objectClass: <object class
…
<attribute type:<attribute value
<attribute type:<attribute value
…
Exemple :
dn: cn= Manon Des Sources, ou= compta, dc=mydomain, dc=org
objectClass: person
objectClass: organization
cn: AN GROSSI
sn: GROSSI
givenName: AM
userPassword: {sha}KDIE3AL9DK
uid: amg
Les fichiers supportent également des commandes pour ajouter, modifier ou supprimer une entrée.
dn: distinguished name
changetype <identifier
change operation identifier
list of attributes…
…
–
change operation identifier
list of attributes
…
<identifier :
add (ajouter une entrée,
delete (suppression),
modrdn (modification du RDN),
modify (modification : add, replace, delete d’un attribut)
On utilise le caractère « – » pour séparer 2 instructions. Par exemple :
dn: cn= Morina Fuentes, ou=admin, dc=mydomain, dc=org
changetype: modify
add: telephonenumber
telephonenumber: 05 55 55 55 55
–
add: manager
manager: cn= toor root, ou=admin, dc=mydomain, dc=org
Les opérations de base sont résumées ici :
Opération
Search recherche dans l’annuaire d’objets
Compare comparaison du contenu de deux objets
Add ajout d’une entrée
Modify modification du contenu d’une entrée
Delete suppression d’un objet
Rename (Modify DN) modification du DN d’une entrée
Bind connexion au serveur
Unbind deconnexion
Les requêtes de type « search » ou « compare » reçoivent des paramètres.
Paramètre
base object l’endroit de l’arbre où doit commencer la recherche
scope la profondeur de la recherche
size limit nombre de réponses limite
time limit temps maxi alloué pour la recherche
attrOnly renvoie ou pas la valeur des attributs en plus de leur type
search filter le filtre de recherche
list of attributes la liste des attributs que l’on souhaite connaître
Le scope (Profondeur de recherche)
Le scope définit la profondeur de la recherche dans l’arbre des données. La figure montre la portée d’une recherche ou d’une comparaison en fonction du paramètre scope.
search scope=base recherche uniquement dans l’entrée définie
search scope=one recherche dans l’entrée définie et le premier sous-niveau
search scope = subtree, cherche dans toute la sous-arborescence.
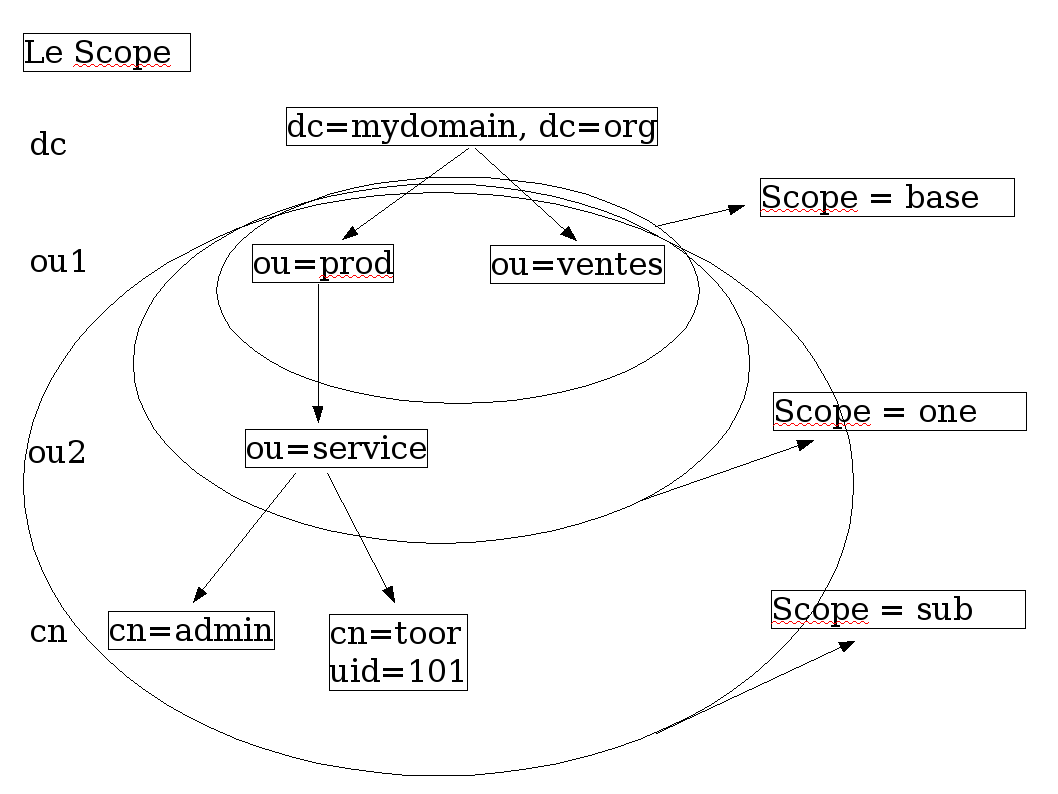
search scope=base recherche uniquement dans l’entrée définie
search scope=onelever search, cherche dans tous les noeuds fils rattachés directement au noeud courant
search scope = subtree, cherche dans toute la sous-arborescence.
Les URL LDAP offrent aux client web un accès aux bases de données :
ldap[s]://<hostname>:<port>/<base_dn>?\
<attributes>?<scope>?<filter>
<base_dn> : DN de l’entrée qui est le
point de départ de la recherche
<attributes>: les attributs que l’on veut consulter
<scope> : la profondeur de recherche dans le
DIT à partir du
<base_dn> : »base » | « one » | « sub »
<filter> : filtre de recherche,
par défaut (objectClass=*)
Exemples :
ldap://ldap.netscape.com/ou=Sales,o=Netscape,c=US?cn,\
tel,mail?scope=sub?(objetclass=person)
ldap://ldap.point-libre.org/cn=Manon,ou=Contact,o=point-libre.org
47.2.4. Le langage de commande
- – slapadd, slapcat, slapindex, slappasswd, fournis avec les serveurs LDAP (utilisables sous le compte root).
- – ldapadd, ldapdelete, ldapmodify, ldapmodrdn, ldappasswd, ldapsearch, fournis avec les utilitaires ldap (utilisable par les utilisateurs et les applications). Ils sont fournis par le paquet (ldap-utils)
Exemple :
ldapsearch -x -h localhost -b « dc=mydomain,dc=fr » « objectclass=* »
Recherche de tous les objets sur l’annuaire de la machine locale, à partir de la racine. (-b indique à partir de quel niveau la recherche doit être exécutée). L’option « -x » indique de ne pas utiliser la méthode d’authentification SASL si elle n’est pas activée.
ldapdelete ‘cn=Jean Colombani,cn=mydomain,cn=fr’
Suppression d’une entrée dans l’annuaire
ldapadd -f /tmp/unFichierAuFormatLDIF
Ajout dans l’annuaire à partir d’un fichier contenant des données au format LDIF.
Note: Pour éviter d’avoir à préciser à chaque fois certains paramètres (machine, port, annuaire…) il est possible de configurer le fichier de configuration « ldap.conf » qui sera utilisé par les applications clientes.
47.3.1. Déterminer les besoins, les données, le schéma
La première opération est une phase d’analyse qui va permettre de déterminer l’organisation du système. Le résultat sera souvent représentable sous une forme arborescente. Cette étape permet de déterminer quel « schéma » sera nécessaire pour le contexte.
LDAP fournit par défaut une hiérarchie de classe déjà complète. Ces classes font l’objet d’une normalisation. Il sera nécessaire d’en prendre connaissance, puis, ensuite de procéder aux extensions nécessaires pour l’étude en cours.
47.4. Créer une base de données
Créer une base de données LDAP, va consister donc d’abord à créer
- une country (c)
- une ou plusieurs organisation (o) à 1 ou plusieurs niveaux
- définir les objets (feuilles de l’arbre)
Il est possible d’importer les informations à partir d’un fichier texte dans la base de données grâce à un format d’échange de données, le format LDIF (Lightweight Data Interchange Format).
47.5. Installer, configurer et Administrer LDAP
Vous allez avoir schématiquement 4 étapes :
- Installer les packages nécessaires
- configurer les fichiers de configuration
- initialiser la base de données
- configurer un client et tester le ou les services à partir d’un client
- passer à l’administration
47.5.1. Installer les packages sur le serveur
Il va falloir installer les packages OpenLDAP. La procédure est standard à partir de paquets (debian ou rpm), sinon à partir des sources.
tar xzvf openldap-x.y.z.tgz
cd openldap.x.y.z
./configure
make
make depend
make test
make install
Installez également les packages perl, php et « dévelop » pour l’administration.
ii slapd 2.1.30-2 OpenLDAP server (slapd)
ii ldap-utils 2.1.30-2 OpenLDAP utilities
ii libldap2 2.1.30-2 OpenLDAP libraries
ii php4-ldap 4.3.8-1 LDAP module for php4
Il est intéressant de prévoir aussi les bibliothèques de développement.
47.5.2. Les fichiers de configuration du serveur
Il faut bien identifier les objets à référencer et les objectifs de l’annuaire. Les fichiers sont dans « /etc/openldap ».
Le premier fichier est « sldapd.conf » qui décrit les principaux paramètres de votre annuaire :
# $OpenLDAP: pkg/ldap/servers/slapd/slapd.conf,v 1.8.8.6 2001/04/20 23:32:43 kurt Exp $
#
# See slapd.conf(5) for details on configuration options.
# This file should NOT be world readable.
#
# Inclusion des schémas nécessaires
include /etc/openldap/schema/core.schema
include /etc/openldap/schema/cosine.schema
include /etc/openldap/schema/inetorgperson.schema
include /etc/openldap/schema/nis.schema
# Options que vous pouvez modifier
#pidfile //var/run/slapd.pid
#argsfile //var/run/slapd.args
#######################################################################
# ldbm database definitions
#######################################################################
# Choix du format de base de données pour le stockage des informations.
database ldbm
# Configurer le suffixe (racine) de l’annuaire
# en fonction du domaine DNS
suffix « dc=my-domain,dc=com »
# ou d’une autre organisation
#suffix « o=My Organization Name,c=US »
# L’administrateur de l’annuaire
rootdn « cn=Manager,dc=my-domain,dc=com »
# Le mot de passe de l’administrateur, préférer une option cryptée
# La commande htpasswd peut très bien faire l’affaire pour encrypter
# rootpw secret
# rootpw {crypt}ijFYNcSNctBYg
# Emplacement de la base de données
directory /var/lib/ldap
# Création des index.
# Comme pour une base de données, indexer les rubriques
# les plus utilisées.
index objectClass,uid,uidNumber,gidNumber,memberUid eq
index cn,mail,surname,givenname eq,subinitial
# La réplication ne sera pas utilisée ici
# Vous pouvez répliquer tout ou partie d’un arbre
# activée par le daemon slurpd
# Directives de replication
# sinon les mettre dans un fichier à part et utiliser
# replogfile /chemincomplet/du/fichier
# Indiquer quels sont les serveurs réplicats
# et la méthode d’authentification
# Ici le serveur local, se répliquera sur ldap1
#replica host:ldap-1.example.com:389
# bindmethod=simple
# binddn= »cn=replicat_slave1, dc=mydomain, dc=fr »
# credential=UnMotDePasse
# Accés par défaut sur la base
defaultaccess read
Protéger ensuite le fichier avec un « chmod 600 /etc/openldap/slapd.conf ».
Les autorisations d’accès nécessitent une remarque.
Ici l’accès par défaut est « read », mais il est possible d’affiner. Par exemple avec des règles d’écriture comme:
access to <what> [ by <who> <none | compare | search | read | write>]
# Donne un accés en écriture pour le manager du domaine
access to * by dn= »cn=Manager,dc=mydomain,dc=fr » write
# Donne un accés en lecture à tout le monde sur la base
access to * by * read
# Donne un accés en écriture sur un attribut pour le manager
# en lecture pour les autres.
access to attr=uid
by dn= »manager,dc=mydomain,dc=fr » write
by * none
Le nombre d’options est très important, utilisez la commande « man slapd.conf« .
Chapter 48. TP 1- Installer, configurer et Administrer LDAP
Le but de ce TP est de découvrir une première mise en oeuvre du service d’annuaire LDAP.
Vous allez avoir schématiquement 4 étapes :
- Installer les packages nécessaires
- configurer les fichiers de configuration
- initialiser la base de données
- configurer un client et tester le ou les services à partir d’un client
- passer à l’administration
48.1. Installer les packages sur le serveur
Il va falloir installer les packages OpenLDAP. La procédure est standard à partir de paquets (debian ou rpm), sinon à partir des sources.
tar xzvf openldap-x.y.z.tgz cd openldap.x.y.z
./configure
make
make depend
make test
make install
Installez également les packages perl, php et « dévelop » pour l’administration.
$> rpm -qa | grep ldap
mod_auth_ldap-1.6.0-7mdk
libldap2-devel-2.0.25-7mdk
libldap2-2.0.25-7mdk
openldap-2.0.25-7mdk
nss_ldap-194-3mdk
libldap2-devel-static-2.0.25-7mdk
openldap-back_ldap-2.0.25-7mdk
openldap-back_sql-2.0.25-7mdk
pam_ldap-148-3mdk
php-ldap-4.2.3-1mdk
perl-ldap-0.26-2mdk
openldap-clients-2.0.25-7mdk
openldap-servers-2.0.25-7mdk
openldap-migration-2.0.25-7mdk
openldap-back_passwd-2.0.25-7mdk
openldap-guide-2.0.25-7mdk
openldap-back_dnssrv-2.0.25-7mdk
Il est intéressant de prévoir aussi les bibliothèques de développement.
48.2. Les fichiers de configuration du serveur
Il faut bien identifier les objets à référencer et les objectifs de l’annuaire. Les fichiers sont dans « /etc/openldap ».
Le premier fichier est « sldapd.conf » qui décrit les principaux paramètres de votre annuaire :
# $OpenLDAP: pkg/ldap/servers/slapd/slapd.conf,v 1.8.8.6 2001/04/20 23:32:43 kurt Exp $
#
# See slapd.conf(5) for details on configuration options.
# This file should NOT be world readable.
#
# Inclusion des schémas nécessaires
include /etc/openldap/schema/core.schema
include /etc/openldap/schema/cosine.schema
include /etc/openldap/schema/inetorgperson.schema
include /etc/openldap/schema/nis.schema
# Options que vous pouvez modifier
#pidfile //var/run/slapd.pid
#argsfile //var/run/slapd.args
#######################################################################
# ldbm database definitions
#######################################################################
# Choix du format de base de données pour le stockage des informations.
database ldbm
# Configurer le suffixe (racine) de l’annuaire
# en fonction du domaine DNS
suffix « dc=my-domain,dc=com »
# ou d’une autre organisation
#suffix « o=My Organization Name,c=US »
# L’administrateur de l’annuaire
rootdn « cn=Manager,dc=my-domain,dc=com »
# Le mot de passe de l’administrateur, préférer une option cryptée
# La commande htpasswd peut très bien faire l’affaire pour encrypter
# rootpw secret
# rootpw {crypt}ijFYNcSNctBYg
# Emplacement de la base de données
directory /var/lib/ldap
# Création des index.
# Comme pour une base de données, indexer les rubriques
# les plus utilisées.
index objectClass,uid,uidNumber,gidNumber,memberUid eq
index cn,mail,surname,givenname eq,subinitial
# La réplication ne sera pas utilisée ici
# Vous pouvez répliquer tout ou partie d’un arbre
# activée par le daemon slurpd
# Directives de replication
# sinon les mettre dans un fichier à part et utiliser
# replogfile /chemincomplet/du/fichier
# Indiquer quels sont les serveurs réplicats
# et la méthode d’authentification
# Ici le serveur local, se répliquera sur ldap1
#replica host:ldap-1.example.com:389
# bindmethod=simple
# binddn= »cn=replicat_slave1, dc=mydomain, dc=fr »
# credential=UnMotDePasse
# Accés par défaut sur la base
defaultaccess read
Protéger ensuite le fichier avec un « chmod 600 /etc/openldap/slapd.conf ».
Les autorisations d’accès nécessitent une remarque.
Ici l’accès par défaut est « read », mais il est possible d’affiner. Par exemple avec des règles d’écriture comme:
access to <what> [ by <who> <none | compare | search | read | write>]
# Donne un accés en écriture pour le manager du domaine
access to * by dn= »cn=Manager,dc=mydomain,dc=fr » write
# Donne un accés en lecture à tout le monde sur la base
access to * by * read
# Donne un accés en écriture sur un attribut pour le manager
# en lecture pour les autres.
access to attr=uid
by dn= »manager,dc=mydomain,dc=fr » write
by * none
Pour configurer un réplicat, procédez comme suit :
# Configurez le fichier slrupd.conf du réplicat
# Ajoutez les options updatedn
# Le dn replicat_slave1 doit être identique à celui déclaré sur le maître.
rootdn = »cn=replicat_slave1, dc=mydomain, dc=fr »
rootpw=UnMotDePasse
updatedn = « cn=replicat_slave1, dc=mydomain, dc=fr »
Le nombre d’options est très important, utilisez la commande « man slapd.conf ».
Chapter 49. Installation d’un annuaire LDAP et utilisation du langage de commande
Relevez l’emplacement des fichiers des configuration et des schémas sur votre machine.
Le fichier ldap.conf et le fichier de configuration des applications clientes.
Le fichier slapd.conf et le fichier de configuration du serveur.
Le service serveur se nomme slapd.
Vérifier l’installation des schémas prédéfinis (généralement dans « /etc/shema » ou dans « /usr/share/openldap/schema/ »)
Faites une sauvegarde de tous vos fichiers de configuration.
Dans le répertoire « schema », sont référencés des définitions normalisées utilisables avec slapd. Les définitions, et ordre de définitions doivent respecter des règles (héritage des objets).
Notez de quels fichiers héritent les définitions données dans le fichiers inetorgperson.schema
Notez de quelles classes d’objets hérite la classe inetorgperson Identifier les propriétés des classes dont dépend la classe inetorgperson. Notez celles qui sont obligatoires.
49.1.1. Configuration du fichier slapd.conf
Modifier le fichier slapd.conf en adaptant l’exemple ci-dessous :
Include /usr/share/openldap/schema/cosine.schema
include /usr/share/openldap/schema/corba.schema
include /usr/share/openldap/schema/inetorgperson.schema
include /usr/share/openldap/schema/java.schema
include /usr/share/openldap/schema/krb5-kdc.schema
include /usr/share/openldap/schema/kerberosobject.schema
include /usr/share/openldap/schema/misc.schema
include /usr/share/openldap/schema/nis.schema
include /usr/share/openldap/schema/openldap.schema
include /usr/share/openldap/schema/autofs.schema
include /usr/share/openldap/schema/samba.schema
include /usr/share/openldap/schema/kolab.schema
# Inclusion des schémas utilisateurs
include /etc/openldap/schema/local.schema
# Définition des ACLs
include /etc/openldap/slapd.access.conf
pidfile /var/run/ldap/slapd.pid
argsfile /var/run/ldap/slapd.args
modulepath /usr/lib/openldap
# Support de TLS, il faut créer un certificat dans /etc/ssl/openldap/ldap.pem
# et décommenter les lignes ci-dessous
#TLSCertificateFile /etc/ssl/openldap/ldap.pem
#TLSCertificateKeyFile /etc/ssl/openldap/ldap.pem
#TLSCACertificateFile /etc/ssl/openldap/ldap.pem
# Journalisation
loglevel 256
###########################################################
# database definitions
###########################################################
database bdb
suffix « dc=foo,dc=org »
rootdn « cn=Manager,dc=foo,dc=org »
# Mot de passe d’accès à la racine de l’arbre.
rootpw secret
# rootpw {crypt}ijFYNcSNctBYg
# Emplacement de la base de la base de données
# The database directory MUST exist prior to running slapd AND
# should only be accessable by the slapd/tools. Mode 700 recommended.
directory /var/lib/ldap
# Création des index sur la base
index objectClass,uid,uidNumber,gidNumber eq
index cn,mail,surname,givenname eq,subinitial
# Contrôle d’accès aux données
# Basic ACL (deprecated in favour of ACLs in /etc/openldap/slapd.access.conf)
access to attr=userPassword
by self write
by anonymous auth
by dn= »cn=Manager,dc=foo,dc=org » write
by * none
access to *
by dn= »cn=manager,dc=foo,dc=org » write
by * read
Lancement du serveur
# /etc/init.d/slapd start
Starting OpenLDAP: slapd.
# ps aux | grep slapd
root 17433 0.1 1.6 7780 2144 ? S 12:54 0:00 /usr/sbin/slapd
root 17434 0.0 1.6 7780 2144 ? S 12:54 0:00 /usr/sbin/slapd
root 17435 0.0 1.6 7780 2144 ? S 12:54 0:00 /usr/sbin/slapd
root 17437 0.0 0.5 1716 716 pts/3 R 12:54 0:00 grep slapd
# netstat -natup | grep LISTEN
tcp 0 0 0.0.0.0:389 0.0.0.0:* LISTEN 17433/slapd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 290/sshd
Le serveur fonctionne bien.
Identifiez à l’aide de la commande netstat, le port sur lequel « écoute » par défaut le service ldap.
49.1.2. Création de l’annuaire
Vous allez utiliser un fichier au format ldif afin de créer l’arbre initial et déclarer l’administrateur. La base de données sera créée dans /var/lib/ldap. En cas d’erreur d’interprétation du fichier ldif, vous devrez relancer la commande. Pour cela :
– arrêtez le serveur ldap,
– supprimez la base de données
(pas le répertoire, mais le contenu du répertoire),
– relancez le serveur, puis le script corrigé.
[ #] /etc/init.d/slapd stop
[ #] rm -rf /var/lib/ldap/*
[ #] /etc/init.d/slapd start
Pour le fichier LDIF, vous pouvez voir ou utiliser les annexes pour l’exemple de fichier LDIF utilisable.
49.1.3. Création de l’annuaire
Créer un fichier « base.ldiff » basé sur celui ci :
dn: dc=foo, dc=org
objectClass: organization
dc: foo
o: foo
telephoneNumber: 05 05 05 05 05
street: cours du General de Gaulle
postalCode: 87000
postalAddress: Limoges
l: Limoges
st: Haute-Vienne
dn: cn=manager, dc=foo, dc=org
objectClass: top
objectClass: person
userPassword: secret
cn: admin
sn: Administrateur
La création de l’annuaire et l’ajout peut se faire, sous le compte root, avec les commandes :
slapadd < leFICHIER.diff
Vérifiez que le serveur a bien enregistré les premières informations à l’aide la commande « slapcat ».
Note : il faut parfois redémarrer le service serveur pour qu’il tienne compte des modifications (ajouts).
49.1.4. Enrichissement de l’annuaire
Récupérez le jeu d’essai et ajoutez les entrées dans l’annuaire.
slapadd < le_FICHIER_LDIFF
Vérifier le résultat à l’aide de la commande slapcat.
49.1.5. Le langage de commande
OpenLDAP fournit un langage et des API pour accéder à la base de données à partir de tous les langages (perl, php, python, c…) mais aussi du shell.
Vous allez utiliser les commandes ldapsearch, ldapadd, ldapmodify
Modifier le fichier ldap.conf de façon à ne pas avoir à préciser à chaque fois les paramètres sur la ligne de commande (machine, et base de l’annuaire)
BASE dc=foo, dc=org
HOST 127.0.0.1
Ainsi une ligne de commande :
ldapsearch -x -h localhost -b ‘dc=foo, dc=org’ ‘objectclass=person’ sn cn
devient
ldapsearch -x ‘objectclass=person’ sn cn
Exemple d’utilisation de la commande ldapsearch
ldapsearch -x ‘objectclass=*’ # On veut tous les objets
ldapsearch -x ‘objectclass=person’ sn cn # On récupère les cn et sn
ldapsearch -x ‘uid=mlx’ mail # On veut le mail de la personnes d’uid mlx
Trouver les numéros de téléphone de toutes les personnes.
Donner les caractéristiques de la personne faisant partie de l’ou « user » et ayant pour uid « mlx ».
Ajout d’un objet (mode interactif) avec ldapadd.
Il faut créer un fichier au format LDIF pour chaque objet que l’on souhaite ajouter. Voici un exemple :
dn: cn=be good, ou=user, dc=foo,dc=org
objectclass: top
objectclass: person
objectclass: organizationalPerson
objectclass: inetOrgPerson
objectclass: posixAccount
cn: be good
sn: Bourg
givenName: good
uid: begood
uidNumber:1010
gidNumber:1010
homedirectory:/home/begood
loginshell:/bin/bash
userpassword:{crypt}2/yajBmqc3tYw
mail: begood@foo.org
telephoneNumber: 00-00-00-00-00
street: none
postalCode: 87400
postaladdress: Chabant
preferredLanguage: fr
Seul un compte ayant le droit d’écrire « write » peut ajouter des occurrences. Ici vous n’utiliserez ces commandes avec un compte système standard (pas le compte root)
$ ldapadd -x -D « cn=manager,dc=foo,dc=org » -w secret -f leFICHIER.ldif
ou alors
$ ldapadd -x -D « cn=manager, dc=foo, dc=org » -W -f le_FICHIER_ldiff
mais vous devrez saisir le mot de passe.
50.1. Authentification système LDAP sur un système GNU/Linux
Faites une sauvegarde de vos fichiers de configuration.
root@uranus:/etc/ldap# cp ldap.conf ldap.conf.orig
root@uranus:/etc/ldap# cp slapd.conf slapd.conf.orig
root@uranus:/etc# cp nsswitch.conf nsswitch.conf.orig
root@uranus:/etc# cp libnss-ldap.conf libnss-ldap.conf.orig
Vérifier que votre serveur LDAP fonctionne.
Vérifier que votre serveur Annuaire est opérationnel.
50.1.1. Configuration de l’environnement pour l’authentification système
Les fichiers /etc/libnss-ldap.conf et /etc/pam_ldap.conf sont normalement configurés. Sinon vous pouvez utiliser les commandes :
dpkg-reconfigure libnss-ldap
dpkg-reconfigure libpam-ldap
Prenez les options par défaut en prenant soin de tenir compte de la structure de votre annuaire. Pour nous :
dc=point-libre,dc=org
Vous devez également modifier le fichier /etc/nssiwtch.conf afin que les applications utilisent aussi bien les fichiers standards (passwd, shadow) que l’annuaire ldap. :
passwd: files ldap
group: files ldap
shadow: files ldap
50.1.2. Premiers tests de l’annuaire
La commande getent passwd doit vous permettre de récupérer à la fois les comptes du fichier /etc/passwd, mais également les compte de l’annuaire ldap qui n’existent pas dans la base passwd.
# getent passwd
[…]
mlx:2/yajBmqc3tYw:1005:1005:BOURG Jean:/home/mlx:/bin/bash
mly:2/yajBmqc3tYw:1006:1006:BOURG Marine:/home/mly:/bin/bash
Ces deux comptes proviennent bien de l’annuaire ldap.
50.1.3. Vérification du fonctionnement de l’annuaire.
L’utilisateur mly n’a pas de compte système. Il n’existe que dans l’annuaire ldap. Créez un répertoire et affectez-le au compte.
# mkdir /home/mly
# chown 1006:100 /home/mly
# ls -al /home/mly
drwxr-sr-x 2 mly users 4096 2003-06-09 13:50 .
# Ici le serveur fonctionne car il substitue bien l’UID à l’uidNumber
# ls -al /home/mly
# Ici le serveur LDAP n’a pas été trouvé ou il ne fonctionne pas.
drwxr-sr-x 2 1006 users 4096 2003-06-09 13:50 .
50.1.4. Mise en place de l’authentification
On va mettre en place maintenant l’authentification ldap. Il faut modifier les fichiers de configuration qui assurent l’authentification. Mettez en début de fichier :
#/etc/pam.d/login
auth sufficient pam_ldap.so
account sufficient pam_ldap.so
password required pam_ldap.so
#/etc/pam.d/passwd
auth sufficient pam_ldap.so
account sufficient pam_ldap.so
password sufficient pam_ldap.so
Vérification de l’authentification :
mlx@uranus:~$ su mly
Password: #ici taper toto
mly@uranus:~$ cd
mly@uranus:~$ pwd
/home/mly
Chapter 51. L’annuaire LDAP avec PHP
51.1. Utilisation de PHP avec LDAP
Faites une sauvegarde de vos fichiers de configuration.
Vérifier que vos serveurs HTTP et LDAP fonctionnent.
Vérifier que votre serveur Annuaire est opérationnel.
51.1.1. Les principales fonctions
$conn=ldap_connect(hote[,port])
établir une connexion avec un serveur LDAP, retourne un entier positif en cas de succès, FALSE en cas d’erreur
$dn = « cn=admin, dc=foo, dc=org »; $mdp= « secret »
$cr=ldap_bind($conn, $dn, $mdp) //connexion authentifiée
$cr=ldap_bind($conn) //connexion anonyme
Retourne TRUE ou FALSE.
$result=ldap_search($conn,$dn,$filtre)
Recherche sur le serveur LDAP avec le filtre $filtre et retourne un identifiant de résultat, ou bien FALSE en cas d’erreur.
$n=ldap_count_entries($conn, $result)
Retourne le nombre d’entrées trouvées ou FALSE en cas d’erreur.
$info=ldap_get_entries($conn, $result)
Retourne un tableau associatif multi-dimensionnel ou FALSE en cas d’erreur. Structure du tableau associatif :
$info[« count »] = nombre d’entrées dans le résultat
$info[0] : sous-tableau renfermant les infos de la première entrée
$info[n][« dn »] : dn de la n-ième entrée du résultat
$info[n][« count »] : nombre d’attributs de la n-ième entrée
$info[n][m] : m-ième attribut de la n-ième entrée
info[n][« attribut »][« count »] : nombre de valeur de cet attribut pour la n-ième entrée
$info[n][« attribut »][m] : m-ième valeur de l’attribut pour la n-ième entrée
$r=ldap_add($conn, $dn, $info)
$dn est l’identification complète de l’entrée à ajouter, et $info un tableau contenant les valeurs des attributs
ldap_modify($conn, $dn, $info)
modifie l’entrée identifiée par $dn, avec les valeurs fournies dans le tableau $info.
51.1.2. Accès anonyme pour une recherche
Le script ci-dessous permet d’exécuter une recherche. Testez ce script avec la commande « php4 ./LeNomDuScript », puis à partir d’une requête http (via mozilla ou konqueror par exemple)
<?
$baseDN = « dc=foo,dc=org »;
$ldapServer = « localhost »;
$ldapServerPort = 389;
$mdp= »secret »;
$dn = ‘cn=manager,dc=foo,dc=org’;
echo « Connexion au serveur <br /> »;
$conn=ldap_connect($ldapServer);
// on teste : le serveur LDAP est-il trouvé ?
if ($conn)
echo « Le résultat de connexion est « .$conn . »<br /> »;
else
die(« connexion impossible au serveur LDAP »);
/* 2ème étape : on effectue une liaison au serveur, ici de type « anonyme »
* pour une recherche permise par un accès en lecture seule */
// On dit qu’on utilise LDAP V3, sinon la V2 par défaut est utilisé
// et le bind ne passe pas.
if (ldap_set_option($conn, LDAP_OPT_PROTOCOL_VERSION, 3)) {
echo « Utilisation de LDAPv3 \n »;
} else {
echo « Impossible d’utiliser LDAP V3\n »;
exit; }
$bindServerLDAP=ldap_bind($conn);
print (« Liaison au serveur : « . ldap_error($conn). »\n »);
// en cas de succès de la liaison, renvoie Vrai
if ($bindServerLDAP)
echo « Le résultat de connexion est $bindServerLDAP <br /> »;
else
die(« Liaison impossible au serveur ldap … »);
/* 3ème étape : on effectue une recherche anonyme, avec le dn de base,
par exemple, sur tous les noms commençant par B */
echo « Recherche suivant le filtre (sn=B*) <br /> »;
$query = « sn=B* »;
$result=ldap_search($conn, $baseDN, $query);
echo « Le résultat de la recherche est $result <br /> »;
echo « Le nombre d’entrées retournées est »
echo ldap_count_entries($conn,$result). »<p /> »;
echo « Lecture de ces entrées ….<p /> »;
$info = ldap_get_entries($conn, $result);
echo « Données pour « .$info[« count »]. » entrées:<p /> »;
for ($i=0; $i < $info[« count »]; $i++) {
echo « dn est : « . $info[$i][« cn »] . »<br /> »;
echo « premiere entree cn : « . $info[$i][« cn »][0] . »<br /> »;
echo « premier email : « . $info[$i][« mail »][0] . »<p /> »;
}
/* 4ème étape : clôture de la session */
echo « Fermeture de la connexion »;
ldap_close($conn);
?>
51.1.3. Accès authentifié pour une recherche
Modifiez le script de façon à obtenir une connexion authentifiée (manager/secret) et retournez la valeur du « sn » de l’admin.
Construisez un formulaire html qui doit vous permettre de vous connecter en saisissant un compte utilisateur et un mot de passe sur l’annuaire LDAP via HTTP.
Adapter le script afin qu’il réalise l’authentification sur l’annuaire.
Vous retournerez les informations en cas de succés, un message d’erreur en cas d’échec.
Chapter 52. Annexes à la séquence sur LDAP
Exemple de fichier utilisable
# Penser à recoder en UTF-8
# avec recode ou iconv
dn: dc=point-libre,dc=org
objectclass: organization
objectclass: dcObject
o: point-libre.org
dc: point-libre.org
description: Annuaire de test
postalCode: 87000
dn: ou=ressource,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou: ressource
description: Branche ressource
dn: ou=user,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou: user
description: Branche utilisateurs
dn: ou=agenda,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou: agenda
description: Branche contact
dn: ou=people,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou: people
description: Branche personne
dn: ou=service,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou: service
description: Branche service
dn: ou=etudiant,ou=people,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou:etudiant
description:Branche etudiant
dn: ou=personnel,ou=people,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou: personnel
description: Branche personnel
dn: ou=nfs,ou=service,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou:nfs
description:nfs
dn: ou=groupe,ou=service,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalUnit
ou:groupe
description: Groupes
dn: cn=manager,ou=ressource,dc=point-libre,dc=org
objectclass: top
objectclass: organizationalrole
cn:manager
#Ajout d’un contact
dn: cn=Aline BOURG, ou=agenda, dc=point-libre,dc=org
objectclass: top
objectclass: person
objectclass: inetOrgPerson
cn: BOURG Aline
sn: Bourg
givenName: Aline
mail: bingo@point-libre.org
telephoneNumber: 00-00-00-00-00
street: none
postalCode: 87400
postaladdress: Chabant
preferredLanguage: fr
#Ajout d’un utilisateur
dn: cn=Aline BOURG, ou=user, dc=point-libre,dc=org
objectclass: top
objectclass: person
objectclass: inetOrgPerson
objectclass: posixAccount
cn: BOURG Aline
sn: Bourg
givenName: Aline
uid: mlx
uidNumber:1005
gidNumber:1005
homedirectory:/home/mlx
loginshell:/bin/bash
userpassword:{crypt}2/yajBmqc3tYw
mail: bingo@point-libre.org
telephoneNumber: 00-00-00-00-00
street: none
postalCode: 87400
postaladdress: Chabant
preferredLanguage: fr
dn: cn=Marine BOURG, ou=user, dc=point-libre,dc=org
objectclass: top
objectclass: person
objectclass: inetOrgPerson
objectclass: posixAccount
cn: BOURG Marine
sn: Bourg
givenName: Marine
uid: mly
uidNumber:1006
gidNumber:1006
homedirectory:/home/mly
loginshell:/bin/bash
userpassword:{crypt}2/yajBmqc3tYw
mail: bingo@point-libre.org
telephoneNumber: 00-00-00-00-00
street: none
postalCode: 87400
postaladdress: Chabant
preferredLanguage: fr
Création de l’annuaire, ajout de données et test.
# slapadd -l init.ldiff
# slapcat
dn: dc=point-libre,dc=org
objectClass: organization
objectClass: dcObject
o: point-libre.org
dc: point-libre.org
description: Annuaire de test
postalCode: 87000
dn: ou=ressource,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: ressource
description: Branche ressource
dn: ou=user,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: user
description: Branche utilisateurs
dn: ou=agenda,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: agenda
description: Branche contact
dn: ou=people,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: people
description: Branche personne
dn: ou=service,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: service
description: Branche service
dn: ou=etudiant,ou=people,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: etudiant
description: Branche etudiant
dn: ou=personnel,ou=people,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: personnel
description: Branche personnel
dn: ou=nfs,ou=service,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: nfs
description:: bmZzICA=
dn: ou=groupe,ou=service,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalUnit
ou: groupe
description:: R3JvdXBlcyA=
dn: cn=manager,ou=ressource,dc=point-libre,dc=org
objectClass: top
objectClass: organizationalrole
cn: manager
dn: cn=Jean BOURG, ou=agenda, dc=point-libre,dc=org
objectClass: top
objectClass: person
objectClass: inetOrgPerson
cn: BOURG Jean
sn: Bourg
givenName: Jean
mail: bingo@point-libre.org
telephoneNumber: 00-00-00-00-00
street: none
postalCode: 87400
postalAddress: Chabant
preferredLanguage: fr
dn: cn=Jean BOURG, ou=user, dc=point-libre,dc=org
objectClass: top
objectClass: person
objectClass: inetOrgPerson
objectClass: posixAccount
cn: BOURG Jean
sn: Bourg
givenName: Jean
uid: mlx
uidNumber: 1005
gidNumber: 1005
homeDirectory: /home/mlx
loginShell: /bin/bash
userPassword:: e2NyeXB0fTIveWFqQm1xYzN0WXc=
mail: bingo@point-libre.org
telephoneNumber: 00-00-00-00-00
street: none
postalCode: 87400
postalAddress: Chabant
preferredLanguage: fr
dn: cn=Marine BOURG, ou=user, dc=point-libre,dc=org
objectClass: top
objectClass: person
objectClass: inetOrgPerson
objectClass: posixAccount
cn: BOURG Marine
sn: Bourg
givenName: Marine
uid: mly
uidNumber: 1006
gidNumber: 1006
homeDirectory: /home/mly
loginShell: /bin/bash
userPassword:: e2NyeXB0fTIveWFqQm1xYzN0WXc=
mail: bingo@point-libre.org
telephoneNumber: 00-00-00-00-00
street: none
postalCode: 87400
postalAddress: Chabant
preferredLanguage: fr
52.2. L’annuaire ldap vu de konqueror
Figure 52-1. LDAP sous konqueror
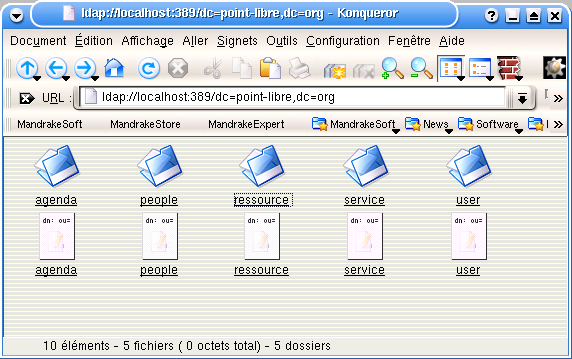
52.3. L’annuaire ldap vu de gq
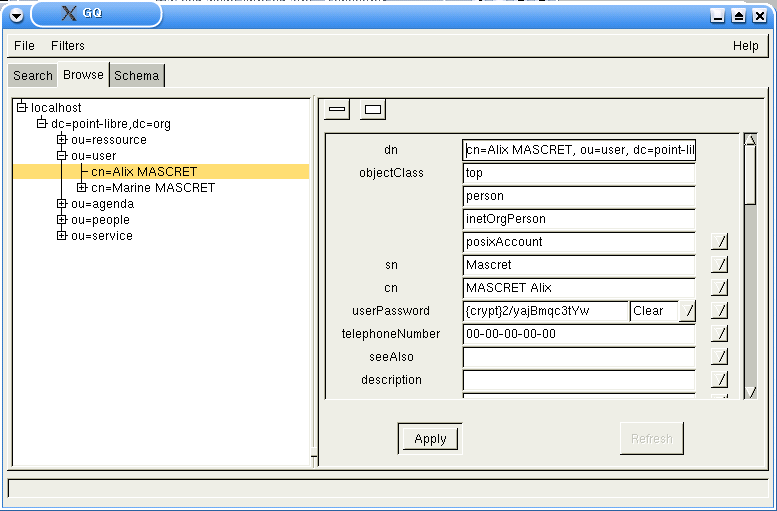
Figure 52-3. Schéma LDAP sous gq
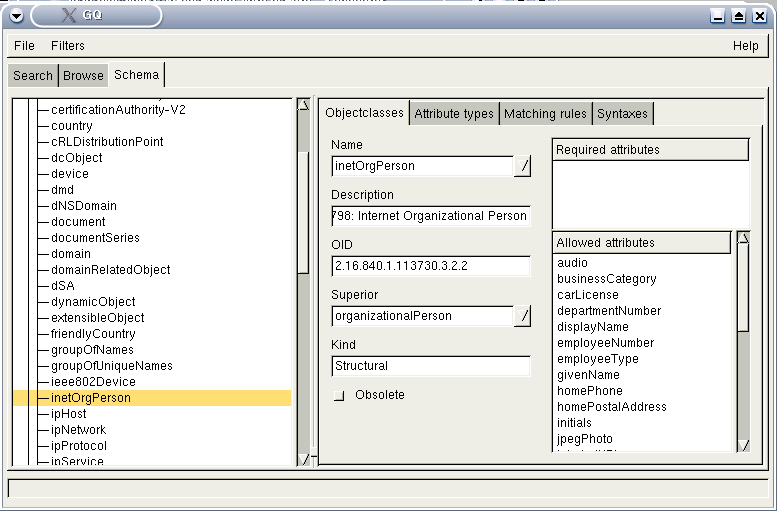
52.5. Authentification avec php sur LDAP
<?
$baseDN = « dc=foo,dc=org »;
$ldapServer = « localhost »;
$ldapServerPort = 389;
$rdn= »admin »;
$mdp= »secret »;
$dn = ‘cn=manager,dc=foo,dc=org’;
echo « Connexion au serveur <br /> »;
$conn=ldap_connect($ldapServer);
// on teste : le serveur LDAP est-il trouvé ?
if ($conn)
echo « Le résultat de connexion est « .$conn . »<br /> »;
else
die(« connexion impossible au serveur LDAP »);
/* 2ème étape : on effectue une liaison au serveur, ici de type « anonyme »
* pour une recherche permise par un accès en lecture seule
*/
// On dit qu’on utilise LDAP V3, sinon la V2 par défaut est utilisé
// et le bind ne passe pas.
if (ldap_set_option($conn, LDAP_OPT_PROTOCOL_VERSION, 3)) {
echo « Utilisation de LDAPv3 \n »;
} else {
echo « Impossible d’utiliser LDAP V3\n »;
exit;
}
// Instruction de liaison.
// Décommenter la ligne pour une connexion authentifiée
// ou pour une connexion anonyme.
// Connexion authentifiée
// print (« Connexion authentifiée …<br /> »);
// $bindServerLDAP=ldap_bind($conn,$dn,$mdp);
// print (« Connexion anonyme…<br /> »);
// $bindServerLDAP=ldap_bind($conn);
print (« Liaison au serveur : « . ldap_error($conn). »\n »);
// en cas de succès de la liaison, renvoie Vrai
if ($bindServerLDAP)
echo « Le résultat de connexion est $bindServerLDAP <br /> »;
else
die(« Liaison impossible au serveur ldap … »);
/* 3ème étape : on effectue une recherche anonyme, avec le dn de base,
* par exemple, sur tous les noms commençant par B
*/
echo « Recherche suivant le filtre (sn=B*) <br /> »;
$query = « sn=B* »;
$result=ldap_search($conn, $baseDN, $query);
echo « Le résultat de la recherche est $result <br /> »;
echo « Le nombre d’entrées retournées est « .ldap_count_entries($conn,$result). »<p /> »;
echo « Lecture de ces entrées ….<p /> »;
$info = ldap_get_entries($conn, $result);
echo « Données pour « .$info[« count »]. » entrées:<p /> »;
for ($i=0; $i alt; $info[« count »]; $i++) {
echo « dn est : « . $info[$i][« cn »] . »<br /> »;
echo « premiere entree cn : « . $info[$i][« cn »][0] . »<br /> »;
echo « premier email : « . $info[$i][« mail »][0] . »<p /> »;
}
/* 4ème étape : cloture de la session */
echo « Fermeture de la connexion »;
ldap_close($conn);
>
Chapter 53. Planification prévisionnelle des séquences LDAP
- Première fiche de cours (fait)
- Install d’un serveur LDAP et authentification système (fait)
- Installation d’un secondaire (en cours)
- Développement via les lib php, c, php et/ou perl (en cours)
- Intgration de l’authentification Samba ou d’autres services (en cours)
- Rajouter une note sur les différences de notation X500 et ldap dans le cours (en cours)
Chapter 54. Synchroniser ses machines avec NTP
54.1. Introduction à ntpdate et ntpd
NTP (Network Time Protocol) permet de synchroniser sa machine avec des serveurs via le reseau et de garder sa machine à l’heure. Nous allons voir deux methodes pour se synchroniser: ntpdate et ntpd. Ces deux outils peuvent s’utiliser de manière complementaire ou bien de manière indépendante.
ntpdate est un des moyens de synchroniser la machine. Il va synchroniser quelle que soit la différence d’horaire avec le serveur.
54.2.1. Installation de ntpdate
apt-get install ntpdate
dpkg demande un ou plusieurs serveurs NTP. Vous pouvez entrer les suivants par exemple:
ntp.metas.ch
swisstime.ethz.ch
chronos.cru.fr
ntp.univ-lyon1.fr
Confirmez l’enregistrement du fichier de configuration de ntp.
Il est possible d’utiliser ntpdate directement sur la ligne de commande avec par exemple:
# ntpdate ntp.metas.ch
31 May 19:07:54 ntpdate[3085]: step time server 193.5.216.14 offset -7192.143171 sec
Votre machine est maintenant à l’heure du serveur ntp.metas.ch
54.2.2. Configuration de ntpdate
Par defaut l’installation avec apt-get configure pour executer ntpdate à chaque démarrage. On peut d’ailleurs le vérifier facilement:
# ls /etc/rcS.d/ | grep ntpdate
S51ntpdate
Il est possible de verifier ce que dpkg a ajouté dans le fichier de configuration /etc/defaults/ntp-servers. Normalement vous devriez avoir ceci:
NTPSERVERS= »ntp.metas.ch »
Désormais, au démarrage de la machine, ntpdate se lancera et synchronisera la machine.
ntp et ntp-simple font tourner un daemon pour synchroniser en permanence la machine et ntp-doc contient toute la documentation au format HTML de NTP
apt-get install ntp ntp-doc ntp-simple
dpkg detecte que vous avez déjà un fichier /etc/default/ntp-servers et propose de modifier votre configuration:
choisissez no pour pourvoir modifier vous-même le fichier de configuration.
les fichiers principaux se trouvent aux endroits suivants:
- /etc/ntp.conf
Fichier de configuration de NTP, c’est là qu’on indique les serveurs avec lesquels ntpd doit se synchroniser.
- /usr/share/doc/ntp-doc/html/index.htm
La documentation ntp au format HTML
- /usr/sbin/ntpd
L’executable principal
- /etc/init.d/ntp
Le script d’initialisation de ntp
Il suffit d’éditer le fichier /etc/ntp.conf (qui n’existe pas pour l’instant) et d’y mettre une liste de serveurs NTP valides.
Utiliser plusieurs serveurs devrait augmenter la précision et éviter les problemes si un des serveurs ne répond pas.
server ntp.metas.ch
server swisstime.ethz.ch
server chronos.cru.fr
server ntp.univ-lyon1.fr
Il suffit maintenant de sauvegarder et relancer ntpd avec la commande:
/etc/init.d/ntp restart
On le voit ces deux outils se completent: ntpdate « remet les pendules à l’heure » au boot alors que ntpd va synchroniser la machine durant l’uptime, de maniere tres précise et par petits règlages. .Il est parfaitement possible d’utiliser ntpdate en crontab afin de synchroniser la machine toutes les heures par exemple, et dans ce cas ntpd n’est plus du tout indispensable cependant il faut garder à l’esprit qu’il est bien plus précis (encore qu’à ce degré là vous ne verrez probablement pas la différence).
- Une liste de serveurs http://www.eecis.udel.edu/~mills/ntp/servers.html
- Tout ce qu’il y a à savoir sur le NTP http://www.eecis.udel.edu/~mills/ntp.html
Chapter 55. Eléments de cours sur le routage et le filtrage de paquets IP
Le document présente des éléments sur le filtrage de paquets par le noyau linux.
55.1. Routage, Filtrage sur les paquets IP
Les paquets ip sont routés en fonction de leur adresse de destination et de leur adresse d’émission. Ils utilisent un protocole de transport (UDP ou TCP). La session est identifiée par un port source et par un port de destination.
Une connexion (session au sens OSI du terme) entre un processus client et un processus serveur est matérialisée par le couple de triplets :
(@IP-source, TCP/UDP, port source) , (@IP-dest., TCP/UDP, portdest.)
Une session nous permet de déterminer quelle application (service serveur) est sollicitée.
Figure 55-1. Squelette de trame IP
Ce sont les principaux éléments que nous utiliseront dans le cadre du routage et du filtrage sur un réseau IP. Le schéma nous montre qu’il sera possible de filtrer sur les adresses (hôtes ou réseaux), les protocoles de transport ou les applications en filtrant sur les ports.
La capture de trame ci-dessous, indique bien les éléments présents dans une trame.
Figure 55-2. Capture de trame sur le port 80
L’analyse de trafic va consister à traiter les paquets en fonction d’un certain nombres de critères.
55.2. Technique de masquage et de traduction d’adresse
Le terme anglais « address translation » a été souvent repris sous la forme « translation d’adresse ». Les documentations en Français tendent aujourd’hui à utiliser plutôt le terme de « traduction d’adresse » dont la signification est plus proche de ce que fait réellement le noyau (et de la traduction littérale du terme anglais « translation » ). Une adresse est ainsi « traduite en une autre ».
Cette technique est principalement utilisée pour partager une ou plusieurs adresses publiques pour un réseau privé (pénurie d’adresses publiques).Elle permet également de sécuriser un réseau en entrée, de limiter les sorties.
Dans la traduction d’adresse encore appelé masquage ou camouflage (ip masquerade), le routeur modifie dans le paquet l’adresse source (SNAT ou ip masquerade) ou l’adresse de destination (DNAT). La modification est réalisée lors de l’envoi et du retour du paquet.
Il y a bien deux fonctions différentes : le routage et le filtrage. Le filtrage va consister à appliquer des règles supplémentaires aux paquets qui sont routés.
Ces deux fonctions sont prises en charge par le noyau Linux. Elles sont prises en charges par « ipchains » pour les noyaux 2.2.x et par « netfilter » pour les noyaux 2.4.
Le filtrage consiste à mettre en place des règles qui seront appliquées aux paquets. Pour netfilter, on utilise la commande « iptables » qui permet de mettre en place ou modifier des chaînes de règles. Les chaînes sont des ensemble de règles qui sont appliquées séquentiellement aux paquets jusqu’à ce que l’une d’entre elles soit applicable. Il y a toujours au moins une chaîne par défaut. Ces chaînes, sont placées dans des tables.
Il y a 3 tables principales pour netfilter (filter, nat et mangle).
La table « filter » est la table par défaut qui contient les règles de filtrage.
La table « nat » contient les règles pour faire de la traduction d’adresse.
La table « mangle » contient les règles qui permettent de modifier les paquets ip, par exemple le champ TOS.
Dans la table filter, il y a 3 principales chaînes : (INPUT, OUTPUT, FORWARD).
La chaîne « INPUT » contient les règles appliquées aux paquets entrants qui sont généralement destinées aux processus locaux.
La chaîne « OUTPUT » contient les règles appliquées aux paquets sortants qui sont généralement émis par les processus locaux.
La chaîne « FORWARD » contient les règles appliquées aux paquets qui traversent.
Figure 55-3. Routage pris en charge par le noyau
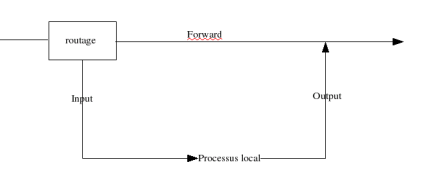
Le routeur est une « boîte noire ». Chaque paquet entrant, quelque soit l’interface d’entrée est « routé » par le noyau. Les paquets qui ne font que traverser le routeur Linux, sont concernés par la chaîne FORWARD. Ceux qui sont destinés aux processus internes, c’est à dire qui entrent, sont concernés par la chaîne INPUT, ceux émis par les processus internes, c’est à dire qui sortent, par la chaîne OUTPUT.
55.3. Masquerading et Forwarding
Le forwarding est une fonction qui permet de router les paquets entre deux réseaux.
Le masquerading est le fait de permettre aux machines de votre réseau interne de pouvoir sortir sur votre réseau externe en utilisant une seule adresse IP officielle. Cette adresse officielle est mise à la place de l’adresse IP de votre machine cliente et re-remplacée au retour du paquet. Dans le cas du masquerading, les machines internes ne peuvent pas être atteintes sans règles supplémentaires par une machine de l’extérieur.
Les techniques de masquerading sont vues dans les parties applications sur ipchains et iptables.
56.1. ICMP et le filtrage de paquets
Les réseaux fonctionnant en IP ont besoin de s’envoyer des messages de contrôle, de temps à autre. Par exemple, cela permet de dire qu’un hôte est inaccessible ou encore que le paquet n’est pas arrivé à destination car la destination est trop lointaine. Ces messages sont regroupés dans le protocole ICMP, Internet Control Message Protocol, rfc 792.
Ce protocole peut facilement se filtrer avec les firewalls, il est donc important de savoir quels messages on doit/veut bloquer et ceux que l’on peut/veut voir traverser notre pare-feu.
Chaque paquet ICMP a un code et un type. Ceux-ci établissent une correspondance exacte sur le « but » du paquet :
type 0 Réponse Echo
code 0 = réponse à une demande d’echo
type 3 Destination non accessible
code 0 = réseau inaccessible
code 1 = hôte inaccessible
code 2 = protocole non disponible
code 3 = port non accessible
code 4 = fragmentation nécessaire mais interdite
code 5 = échec d’acheminement source
type 4 Contrôle de flux
code 0 = ralentir le flux de l’émission
type 5 Redirection
code 0 = redirection de datagramme sur la base du réseau
code 1 = redirection de datagramme sur la base de l’adresse d’hôte
code 2 = redirection de datagramme sur la base du réseau et du Type de Service
code 3 = redirection de datagramme sur la base de l’hôte et du Type de Service
type 8 Echo
code 0 = envoi d’un echo
type 11 Durée de vie écoulée
code 0 = durée de vie écoulée avant arrivée à destination
code 1 = temps limite de réassemblage du fragment dépassé
type 12 Erreur de Paramètre
code 0 = l’erreur est indiquée par le pointeur
type 13 Marqueur temporel
code 0 = envoi d’une étiquette temporelle d’émission
type 14 Réponse à marqueur temporel
code 0 = envoi d’une étiquette temporelle de réception et de transmission
type 15 Demande d’information
code 0 = demande du numéro de réseau
type 16 Réponse à demande d’information
code 0 = réponse du numéro de réseau
Résumé des commandes et exemples Ipchains.
Ipchains est utilisable avec les anciennes versions de netfilter sur les versions des noyaux 2.2.
D’après la page de man d’ipchains :
ipchains -[ADC] chain rule-specification [options]
ipchains -[RI] chain rulenum rule-specification [options]
ipchains -D chain rulenum [options]
ipchains -[LFZNX] [chain] [options]
ipchains -P chain target [options]
ipchains -M [ -L | -S ] [options]
Ipchains est utilisé pour configurer, maintenir et surveiller les règles du firewall IP du noyau Linux. Ces règles sont stockées dans quatre catégories de chaînes différentes, la chaîne input, la chaîne output, la chaîne forward, les chaînes utilisateurs. Pour chacune de ces catégories une table de règles propre à la chaîne est maintenue.
target : une règle de firewall spécifie un ensemble de critères à appliquer pour un paquet et une destination. Si le paquet ne peut être traité, la règle suivante est examinée, si le paquet peut être traité, alors la règle est appliquée. Cette règle peut être :
* JUMP RegleUtilisateur, le paquet sera traité par une règle d’une chaîne utilisateur,
* une des valeurs ACCEPT, DENY, REJECT, MASQ, REDIRECT, RETURN.
* ACCEPT laisse le paquet traverser la chaîne,
* DENY jette purement et simplement le paquet,
* MASQ est utilisé pour masquer les adresses sources des paquets.
Commandes : ces options spécifient les actions à réaliser. Il est possible d’en spécifier qu’une seule à la fois sur la ligne de commande.
-A, –append Ajoute une règle à la fin de la chaîne.
-D, –delete Supprime une ou n règles dans une chaîne.
-I, –insert Insère une ou plusieurs règles dans la chaîne mentionnée.
-L, –list Donne une liste des règles en cours d’application.
-Z, –zero Initialise un compteur de paquet et de bytes des règles.
-p, –protocol[!] protocol Spécifie le protocole à traiter dans la règle.
tcp, udp, icmp, all.
-s, –source [!] address[/mask] [!] [port[:port]] permet de définir la source.
Exemple -s 192.168.1.0/24 port 80 signifie tous les paquets adressés
sur le port 80 et en provenance des machines du réseau d’adresse 192.168.1.0.
Si le port est précisé, la règle doit préciser à quel protocole elle s’applique
(icmp, tcp, udp, all).
-d, –destination [!] address[/mask] [!] [port[:port]]
Même remarque que pour le paramètre « –source » mais appliqué à la destination.
-j, –jump target utilisé dans une règle pour définir une autre chaîne
de traitement du paquet (chaîne utilisateur) ou pour indiquer le traitement
à réaliser.
-i, –interface [!] name Paramètre optionnel.
Permet de spécifier une règle qui va traiter les paquets entrants
ou à destination d’une interface réseau.
Attention à l’écriture. Les cibles (target) sont sensibles à la casse.
Exemples d’écriture :
Voir toutes les règles actives :
ipchains -L ou ipchains -n -L (mode numérique sans résolution de nom)
Supprimer les règles du firewall et fermer maintenant toutes les portes
avec les commandes :
ipchains -A input -p all -j DENY ou ipchains -A input -j DENY
ipchains -A output -p all -j DENY
ipchains -A forward -p all -j DENY
La première chaîne signifie que pour tous les protocoles qui entrent les paquets seront détruits. Pour modifier les règles par défaut des chaînes input, output ou forward, utiliser -P
ipchains -P forward -j DENY
#par défaut les paquets seront refusés sur la chaîne forward.
; Supprime la première règle de la chaîne input
ipchains -D input 1
; Refuser tous les paquets sur la chaîne input
ipchains -I input -j DENY ou alors ipchains -P input DENY
; Crée une nouvelle chaîne utilisateur « machaine »
ipchains -N machaine
; Ajoute à la chaîne « machaine » une autorisation pour tous les paquets
; de type HTTP à destination de la machine 192.168.90.1
ipchains -A machaine -s 0.0.0.0/0 www -d 192.168.90.1 -j ACCEPT
; Redirige tous les paquets sur le port 8080 (service mandataire)
ipchains -A input -p tcp -s 192.168.1.1/24 -d 0.0.0.0/0 80 -j redirect 8080
; Accepter les requêtes DNS sur la machine 192.168.1.1
ipchains -A input -p udp -s 0/0 dns -d 192.168.1.1/24 -j ACCEPT
; Les deux règles suivantes permettent de se protéger de
; l’ip-spoofing si eth0 est l’interface du réseau privé.
ipchains -A input -i eth0 -s ! 192.168.1.0/255.255.255.0 -j DENY
ipchains -A input -i ! eth0 -s 192.168.1.0/255.255.255.0 -j DENY
— Configuration du Firewall – masquage :
; Ouvrez toutes les portes du firewall à l’aide des commandes suivantes :
ipchains -A input -j ACCEPT
ipchains -A output -j ACCEPT
ipchains -A forward -j ACCEPT
# Pensez à vérifiez l’état des chaînes à l’aide de la commande » ipchains -n -L »
; Activer l’ip masquerading à l’aide de la commande :
ipchains -A forward -p all -s 192.168.1.0/24 -d 0.0.0.0/0 -j MASQ
; Cela signifie qu’il faudra masquer (effectuer une translation
; d’adresse -j MASQ) pour tous les paquets qui proviennent (-s source)
; du réseau 192.168.1.0 et vont à destination de n’importe quelle adresse.
; Autres exemples commentés de règles.
; Autoriser la circulation des protocoles FTP, HTTP et refuser tous les autres.
ipchains -A output -p tcp -s 192.168.1.0/24 -d 0.0.0.0/0 80 -j ACCEPT
# pour les requêtes HTTP
ipchains -A output -p tcp -s 192.168.1.0/24 -d 0.0.0.0/0 21 -j ACCEPT
# pour les requêtes FTP
ipchains -A output -p tcp -s 192.168.1.0/24 -d 0.0.0.0/0 20 -j ACCEPT
# pour les requêtes FTP-DATA
ipchains -A output -p tcp -s 192.168.1.0/24 -d 0.0.0.0/0 113 -j
; ACCEPT
# pour les requêtes AUTH
ipchains -A output -s 192.168.1.0/24 -d 0.0.0.0/0 -j DENY
; Le port tcp/80 permet de laisser sortir les requêtes HTTP,
; Le port tcp/21 permet d’ouvrir une session sur un hôte distant,
; Le port tcp/20 permet l’échange de donnée (put/get),
; Le port tcp/113 permet l’authentification.
; On refuse d’envoyer tout le reste.
; Interdire toutes les requêtes qui sortent vers l’extérieur,
; sauf celles qui vont sur un port 80 (requêtes http),
; Ici, on utilise les noms de protcoles définis dans /ets/services
ipchains -A input -p tcp -d 0.0.0.0/0 ! www -j DENY
; Créer une nouvelle chaîne qui aura en charge les paquets icmp.
; Tous les paquets icmp seront détruits,
ipchains -N ch-icmp
ipchains -I ch-icmp -j DENY
# détruire les paquets
ipchains -I input -p icmp -j ch-icmp
# si c’est un paquet icmp alors, traiter dans ch-icmp
; Remarque : Le traitement des paquets icmp demande une
; attention particulière. Voir ipchains-HOWTO pour cela.
; Créer une nouvelle chaîne qui aura en charge les paquets provenant
; du réseau interne et qui passent sur l’interface eth0,
ipchains -N int-ext /* paquets qui vont de l’intérieur vers l’extérieur */
ipchains -I int-ext -j ACCEPT /* on accepte tout c’est juste pour tester */
ipchains -I input -i eth0 -j int-ext /* si c’est un paquet qui vient du réseau
interne alors, traiter dans int-ext */
; Interdire la sortie de tous les protocoles sauf le protocole HTTP,
; (deux formes d’écriture possible),
; Première solution :
ipchains -A output -p tcp -s 192.168.1.0/24 -d 0.0.0.0/0 80 -j ACCEPT
ipchains -A output -s 192.168.1.0/24 -d 0.0.0.0/0 -j DENY
; Deuxième solution
ipchains -A output -p tcp -s 192.168.1.0/24 -d 0.0.0.0/0 !80 -j DENY
; /* Rejette tout ce qui n’est pas à destination d’un port 80.
; Scénario, on souhaite :
; 1 – pour toutes les machines d’un réseau privé sauf les machines
; » .1 » et » .2 « , laisser sortir tous les paquets par translation
; d’adresse sur les ports 25, 110 et 53 (smtp, pop3 et DNS) interdire tout le reste.
; 2 – interdire pour toutes les machines, tout passage des protocoles MS.
#Règles IPCHAINS du FW en date du 24/10/2000
# On ferme d’abord tout
ipchains -P forward DENY
#SMTP on laisse passer
ipchains -A forward -j MASQ -p tcp -s 192.168.90.0/24 -d 0.0.0.0/0 25
g
ipchains -A forward -j MASQ -p tcp -s 192.168.90.0/24 -d 0.0.0.0/0 110
#DNS oui avec les protocoles de transport UDP et TCP
ipchains -A forward -j MASQ -p tcp -s 192.168.90.0/24 -d 0.0.0.0/0 53
ipchains -A forward -j MASQ -p udp -s 192.168.90.0/24 -d 0.0.0.0/0 53
#machines .1 et .2
ipchains -A forward -j MASQ -s 192.168.90.1/32 -d 0.0.0.0/0
ipchains -A forward -j MASQ -s 192.168.90.2/32 -d 0.0.0.0/0
#Les protocoles de MS (transport UDP et TCP)
ipchains -A input -j DENY -p udp -s 192.168.90.0/24 -d 0.0.0.0/0 137
ipchains -A input -j DENY -p udp -s 192.168.90.0/24 -d 0.0.0.0/0 138
ipchains -A input -j DENY -p tcp -s 192.168.90.0/24 -d 0.0.0.0/0 137
ipchains -A input -j DENY -p tcp -s 192.168.90.0/24 -d 0.0.0.0/0 138
Extrait de la page de manuel et de l’aide :
Synopsis :
Usage iptables -commande chaine spécification_de_règle [options]
Commandes : Fonction :
iptables -h aide en ligne
iptables -L lister les chaînes et règles actives
iptables -N chain créer une nouvelle chaîne utilisateur
iptables -X chain supprimer chaîne utilisateur
iptables -F [chain] vider une chaîne (ou toutes)
iptables -P chain cible traitement par défaut pour une règle
iptables -A chain règle ajouter une règle à la chaîne
iptables -I chain [numéro] règle insérer une chaîne en position numéro
iptables -D chain [numéro] [règle] effacer une règle
iptables -R chain [numéro] [règle] remplacer une règle
iptables -C chain tester un paquet dans une règle
iptables -Z [chain] remettre à zéro les compteurs
Options : Les principaux paramètres qui peuvent apparaître dans la partie règle sont :
Paramètres :
-i interface appliquer la règle sur cette interface d’entrée
-o interface appliquer la règle sur cette interface de sortie
-t table table concernée ( filter par défaut)
-s [!] X.X.X.X/lg adresse source, longueur du masque
le ! signifie la négation (cf. exemple)
-d [!] X.X.X.X/lg adresse dest (et longueur du masque)
-p protocole tcp / udp / icmp / all
–source-port [!] [port[:port]] port source (ou intervalle de ports)
–destination-port [!] [port[:port]] port destination (ou intervalle de ports)
–tcp-flags [!] masq comp flags de paquets tcp ( ex. SYN)
-j cible ACCEPT/DROP/QUEUE/RETURN/REDIRECT/
MASQUERADE / DNAT/ SNAT/ LOG
Exemple d’utilisation des règles :
# iptables -F INPUT [-t filter]
# iptables -P INPUT ACCEPT
# iptables -A INPUT -i eth0 -s ! 192.168.0.0.0/24 -j DROP
Attention à l’écriture. Les cibles (target) sont sensibles à la casse.
Les tables passées en lignes de commandes ou dynamiquement, ne sont pas conservées lors du redémarage de la machine. Il est nécessaire d’utiliser les commandes iptables-save et iptables-restore pour les sauvegarder, ou les mettre dans un script qui est exécuté au démarrage de la machine, par exemple dans /etc/init.d/rc.local.
58.2. Exemples d’utilisation d’iptables
Prenez l’habitude avant toute chose de vérifier l’état des règles avant de procéder à des tests. Videz les au besoin avant de commencer.
iptables -F INPUT && iptables -P INPUT ACCEPT
iptables -F FORWARD && iptables -P FORWARD ACCEPT
iptables -F OUTPUT && iptables -P OUTPUT ACCEPT
Interdire en entrée toute requête HTTP
iptables -A INPUT -s 192.168.0.0/24 -p tcp –dport 80 -j REJECT
Iptables permet de journaliser les informations avec l’option –log-prefix
iptables -A INPUT -s 192.168.0.0/24 -p tcp –dport 80 -j REJECT \
–log-prefix « Session http rejetée »
58.3. La traduction d’adresse – NAT
La traduction d’adresse est gérée avec les chaînes PREROUTING, POSTROUTING et OUTPUT. Dans la chaîne PREROUTING (avant routage), on ne peut modifier que l’adresse de destination. L’adresse source est conservée. On fait donc du DNAT. On dit qu’on fait du « NAT destination ». Dans la chaîne POSTROUTING, (après routage) on ne peut modifier que l’adresse source. L’adresse de destination est conservée. On fait donc du SNAT. On dit qu’on fait du « NAT source ».
Certaines applications arp, ftp, irc … nécessitent des options. Ces options sont compilées directement dans votre noyau ou sous forme de modules.
Figure 58-1. Compilation du noyau pour netfilter
Les modules sont dans :
/lib/modules/VotreNoyau/kernel/net/ipv4/netfilter/
58.3.1. Le DNAT ou NAT Destination
On substitue à l’adresse de destination des paquets provenant du réseau public, une adresse du réseau local privé. Dans l’exemple, les paquets à destination de la machine 195.x sont redirigés vers la machine 172.y. On ne tient pas compte du port.
iptables -F INPUT ; iptables -P INPUT ACCEPT
iptables -F OUTPUT ; iptables -P OUTPUT ACCEPT
iptables -F FORWARD ; iptables -P FORWARD ACCEPT
iptables -t nat -F PREROUTING
iptables -t nat -A PREROUTING -d 195.115.19.35/32 \
-j DNAT –to-destination 172.16.0.1/32
Le SNAT consiste à substituer une adresse source dans un paquet sortant à son adresse source d’origine. On substitue ici, aux requêtes provenant du réseau 192.168.0.0/24, une des 10 adresses publiques.
iptables -F INPUT ; iptables -P INPUT ACCEPT
iptables -F OUTPUT ; iptables -P OUTPUT ACCEPT
iptables -F FORWARD ; iptables -P FORWARD ACCEPT
iptables -t nat -F POSTROUTING
iptables -t nat -A POSTROUTING -s 192.168.0.0/24 \
-j SNAT –to-source 195.115.90.1-195.115.90.10
Dans ce cas, les adresses privées, utilisent toutes la même adresse publique. C’est le procédé qui est utilisé avec ipchains. Il s’agit en fait de translation de port avec ipchains ou de SNAT (Nat Source) avec iptables.
iptables -F INPUT ; iptables -P INPUT ACCEPT
iptables -F OUTPUT ; iptables -P OUTPUT ACCEPT
iptables -F FORWARD ; iptables -P FORWARD ACCEPT
iptables -t nat -F POSTROUTING
iptables -t nat -A POSTROUTING -s 10.10.10.0/8 \
-j SNAT –to-source 139.63.83.120
Une autre option consiste à utiliser l’option « MASQUERADE »
iptables -t nat -F POSTROUTING
iptables -t nat -A POSTROUTING -s 10.10.10.0/8 -j MASQUERADE
58.3.4. Exemple sur un réseau privé
L’exemple ci-dessous indique comment partager un accès internet chez soi pour plusieurs machines. Vous voulez partager un accès « dial » sur votre réseau.
#ifconfig
eth0 Lien encap:Ethernet HWaddr 00:80:C8:7A:0A:D8
inet adr:192.168.0.1 Bcast:192.168.0.255 Masque:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:19950 errors:0 dropped:0 overruns:0 frame:0
TX packets:24988 errors:0 dropped:0 overruns:0 carrier:0
collisions:2 lg file transmission:100
RX bytes:2830076 (2.6 Mb) TX bytes:12625623 (12.0 Mb)
Interruption:5 Adresse de base:0x240
ppp0 Lien encap:Protocole Point-à-Point
inet adr:212.47.248.114 P-t-P:212.47.251.49 Masque:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1524 Metric:1
RX packets:27 errors:0 dropped:0 overruns:0 frame:0
TX packets:29 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 lg file transmission:3
RX bytes:4924 (4.8 Kb) TX bytes:1365 (1.3 Kb)
#echo 1 > /proc/sys/net/ipv4/ip_forward
#iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -j MASQUERADE
iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all — 192.168.90.0/24 anywhere
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Le tour est joué, vous n’avez plus qu’à configurer les autres clients avec un DNS et une passerelle par défaut. Votre accès wan est partagé.
Chapter 59. Application sur le routage et le filtrage de paquets IP
L’objectif est de configurer une machine sous Linux, munie de trois cartes réseau 10/100 Base T, pour en faire un firewall. Voir schéma réseau et maquette. Le TP est réalisable avec Ipchains ou Iptables.
L’objectif est de configurer une machine sous Linux, munie de trois cartes réseau 10/100 Base T, pour en faire un firewall. Pour visualiser les trames qui sont échangées sur le réseau, vous utiliserez un outil d’analyse de trames comme tcpdump, ethereal ou autre. Enfin pour filtrer le trafic et faire de la translation de port (PAT) la fonctionnalité ipchains du noyau Linux sera utilisée. Un outil comme iptraf est intéressant pour visualiser la translation de port sur le routeur.
Le rôle d’un routeur (ou passerelle/gateway en terminologie IP) est de « router » les paquets entrants par une interface, vers une de ses interfaces de sortie, en fonction de l’adresse IP du destinataire (en fait du réseau auquel il appartient).
Le routeur dispose d’une table de routage interne, visible avec la commande route.
Exemple de table de routage :
Destination Passerelle Genmask Indic Metric Ref Use Iface
192.168.0.0 * 255.255.255.0 U 0 0 0 eth0
172.16.0.0 * 255.255.0.0 U 0 0 0 eth1
10.0.0.0 * 255.0.0.0 U 0 0 0 eth2
127.0.0.0 * 255.0.0.0 U 0 0 0 lo
default 192.168.0.254 0.0.0.0 UG 0 0 0 eth0
Le noyau Linux sait router les paquets entre différentes interfaces et vers des réseaux. Il faut que la fonction « ip forwarding » soit activée. Cela est faisable soit dynamiquement :
echo 0/1 > /proc/sys/net/ipv4/ip_forward
soit en modifiant un fichier de configuration.
/etc/network/options sur debian
/etc/sysconfig/network sur mandrake
Le filtrage des paquets au niveau IP, transport ou adresse est utilisé pour des raisons de sécurité. Par exemple autoriser ou interdire l’accès à un service, à un réseau ou à une machine (voir fiche de cours).
Avec les noyaux 2.2, il est possible de faire du filtrage et du masquage d’adresse IP par translation de port (PAT). Ipchains utilise, de base, trois chaînes (input, output, forward) qui contiennent des règles de filtrage/masquage.
Les règles de filtrage sont analysées de manière séquentielle, dès qu’une règle correspond au paquet analysé, elle est appliquée.
Chaque paquet est analysé au travers des chaînes. Si un filtre correspond, la règle associée est appliquée au paquet ( ACCEPT, DENY, MASQ …). Sinon le filtre suivant est testé. A la fin de chaque chaîne un traitement « par défaut » est appliqué en dernier ressort ( ACCEPT/DENY)
Vous trouverez à la fin du document, un récapitulatif des commandes.
Références : les HOWTOs (Linux Ipchains et IP Masquerade l’on peut télécharger sur http://www.linuxdoc.org)
Utiliser la documentation donnée à la fin du document.
Figure 59-1. Schéma maquette TD
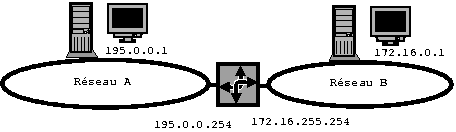
Ecrire les règles de filtrage iptables qui répondent aux différents problèmes exprimés ci-dessous.
Notation :
A = 195.0.0, B = 172.16,
A.0 = toutes les machines du réseau 1, B.0 = toutes les machines du
réseau B
A.1, B.1, indiquent respectivement 195.0.0.1 et 172.16.0.1
- Interdire tous les paquets de A.0 vers B.0
- Interdire tous les paquets de A.0 vers B.1
- Interdire tous les paquets NetBIOS sur A.254
- Masquer toutes les adresses de A.0 pour tous les protocoles
- Masquer toutes les adresses de A.0 pour tous les protocoles uniquement pour les services SMTP et POP3
- N’autoriser que les paquets de A.1 vers B.1, interdire tout le reste
- Interdire les paquets de A.1 vers B.1, autoriser tout le reste
- N’autoriser que les paquets telnet de A.1 vers B.1, interdire tout le reste
- N’autoriser que les paquets TCP de A.0 vers B.0, interdire tout le reste.
59.4. Schéma de la maquette pour le TP
Schéma d’un réseau simple. Le routeur a trois interfaces réseau. Les segments de classe A et le segment de classe B peuvent être réalisés à l’aide de simple machines et de câbles croisés.
Schéma d’un réseau simple plus complexe. Quatre maquettes construites sur le schéma précédent sont reliées à un segment fédérateur. Ce dernier peut être le réseau de l’établissement.
Vous allez réaliser ce TP sur la maquette que vous avez monté pour le routage. Vous utiliserez trois machines C, R et S. R fait référence à votre routeur. C fait référence au client installé sur le réseau de classe B, S fait référence au serveur installé sur le réseau de classe A.
C est sur un réseau « privé » (C sera client pour les tests)
S est sur un réseau « public »
R servira de routeur et pare-feu (firewall) entre votre réseau privé et le réseau public.
Vous allez réaliser ce TP en trois parties :
- Première partie : vérification du routage sur le routeur logiciel R,
- Deuxième partie : mise en oeuvre de règles de filtrage simples et de la tranduction d’adresse sur R
- Troisième partie : mise en place de règles de filtrage par adresse, par port et par protocole.
Vous utiliserez la documentation de ipchains ou iptables ainsi que les exemples commentés qui vous sont fournis.
59.4.1. Première partie : installation et configuration du routage
- Installez les interfaces réseau sur le routeur et démarrer la machine.
- Créez les fichiers de configuration des interfaces eth0, eth1 et eth2.
- Installez le module de la carte dans le fichier » /etc/module.conf » si nécessaire
- Lancez le service réseau sur R » /etc/rc.d/init.d/network restart « , relevez les routes.
- Vérifiez à l’aide de la commande » ifconfig » que les interfaces sont bien actives. Corrigez tant que ce n’est pas le cas. Configurez et installez C sur votre réseau privé,
- Testez l’accès de C vers les deux interfaces de R. Pourquoi l’accès vers le réseau public ne fonctionne pas ?
- Activez le routage (ip forward) entre les interfaces réseau. (NETWORKING=yes dans /etc/sysconfig/network pour Mandrake ou ip_forward=yes dans /etc/network/options pour Debian.
Vous pouvez également utiliser la commande :
echo 1 > /proc/sys/net/ipv4/ip_forward
Relancez le service réseau, relevez les routes de R à l’aide de la commande » route « .
- Vérifiez avec une commande » ping » que les deux interfaces de R sont bien visibles à partir de C.
- Vérifiez l’installation du programme iptraf sur R
59.4.2. Règles de filtrage simples
- Interdisez toutes les requêtes de C vers S (extérieur) (tester)
- Autorisez toutes les requêtes du client C vers S (tester)
- Interdisez tout passage sur la chaîne FORWARD en laissant l’option » ACCEPT » sur les chaînes INPUT et OUTPUT (tester)
- Activez le masquage d’adresse pour toutes les machines du réseau auquel appartient C vers tous les autres réseaux (tester)
- Activez le masquage d’adresse pour toutes les machines du réseau auquel appartient C vers un seul des autres réseaux. Exemple si vous êtes sur le domaine vert.org, activer le masquage vers bleu.org. Les paquets ne devront pas passer vers noir.org ou rouge.org. (tester)
- Restaurez l’état réalisé au point 4 (après masquage). Activez » iptraf » sur l’interface publique. Vérifiez que seule, l’adresse ip de l’interface du réseau privé apparaît et que toutes les autres sont » masquées « . Notez la traduction de port et identifiez les sessions.
59.4.3. Règles de filtrage par adresse, port et protocoles
- Relevez dans le fichier » /etc/protocol » et » /etc/services » les ports et noms des protocoles utilisés par les services ftp et http. Refusez tout trafic de C vers l’extérieur à destination de ces ports. Vérifier que telnet est accepté. (tester puis restaurer)
- N’autorisez à C l’accès qu’à une seule machine (par exemple le client C de rouge.org si vous êtes sur vert.org), refusez tout le reste. (tester puis restaurer)
- Refusez tout accès à la machine (192.168.x.1) de votre réseau (192.168.x.0) vers le réseau (192.168.y.0). (tester.) (tester aussi en modifiant l’adresse ip de votre client que celui-ci passe.)
- Relevez les ports et protocoles utilisés par les services de résolution de noms Construisez les règles afin qu’elles répondent au problème suivant. On désire que : toutes les machines du réseau privé puissent avoir accès à tous les autres services de n’importe quel réseau, la machine C de votre réseau privé ne peut pas envoyer de requête UDP/DOMAIN vers la machine S.
(tester pour les requêtes sur le serveur de noms puis pour des requêtes sur le serveur ftp en utilisant l’adresse IP)
- Pour les deux traitements qui suivent, vous utiliserez deux écritures, dont l’opérateur » ! » (not) qui permet d’obtenir des compléments.
Autorisez toutes les requêtes qui sortent vers l’extérieur, sauf celles qui vont sur un port ftp
N’autorisez aucune requête hormis celles qui sont à destination du port 80