60. Outils et ressources complémentaires pour les TP
60.1. Iptraf
60.2. Documentations complémentaires
61. Initiation au routage
61.1. Initiation au routage
61.1.1. Les principes du routage
61.1.2. Place à la pratique
61.1.3. Conclusion
62. Le routage dynamique avec RIP
62.1. Introduction
62.1.1. Pourquoi le routage dynamique ?
62.1.2. Le protocole RIP
62.1.3. Place à la pratique
62.1.4. Conclusion
63. Le routage dynamique avec OSPF
63.1. Introduction
63.1.1. Rappels sur les éléments vus
63.1.2. Les grands principes
63.1.3. Le fonctionnement d’OSPF un peu plus en détail
63.1.4. Place à la pratique
63.1.5. Conclusion
64. Le routage dynamique avec BGP
64.1. Introduction
64.1.1. Les grands principes
64.1.2. Place à la pratique
64.1.3. Cohabitation entre BGP et les IGP
64.1.4. Conclusion
65. TP sur le routage statique avec Zebra
65.1. Introduction
65.1.1. Présentation des concepts importants
65.1.2. Architecture de Zebra
65.1.3. Topologie de travail
65.1.4. Mise en place
65.1.5. Démarrage du démon zebra
65.1.6. Connexion au démon zebra
65.1.7. Prise en main de Zebra (principe)
65.1.8. Prise en main de Zebra (mise en pratique)
65.1.9. Problèmes rencontrés
66. Multi-router looking glass
66.1. Présentation
67. Annexe sur le langage de commande de Zebra
67.1. Annexe sur le langage de commande de Zebra
68. Concepts généraux sur le routage
68.1. Présentation
68.2. Jargon réseau sur le routage
68.2.1. Notion de système autonome (SA)
68.2.2. Choix d’une route et métrique
68.3. Les protocoles de routages IGP’s
68.3.1. Les algorithmes Vector-Distance
68.3.2. Algorithme Link State (État de Liens)
68.3.3. Les techniques hybrides
68.4. Les protocoles de routages extérieurs EGP
69. Remerciements et licence
69.1. Copyright
Chapter 60. Outils et ressources complémentaires pour les TP
Outils et ressources complémentaires
60.1. Iptraf
Iptraf est utile pour la visualisation des connexions tcp, de la translation de port et de la translation d’adresse.
Figure 60-1. iptraf
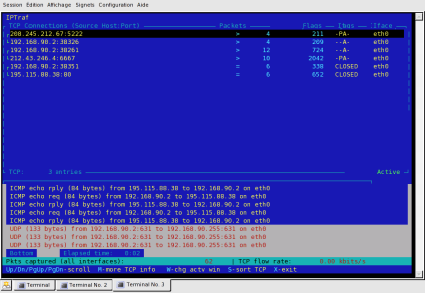
Pour démarrer automatiquement le moniteur de traffic IP
iptraf -i all
Pour démarrer automatiquement les statistiques générales des interfaces
iptraf -g
Pour démarrer automatiquement les informations détaillées d’une interface
iptraf -d eth0
60.2. Documentations complémentaires
Le guide de l’administration de la couche IP avec Linux : http://linux-ip.net/
fwbuilder : http://www.fwbuilder.org/
Chapter 61. Initiation au routage
Initiation au routage statique
61.1. Initiation au routage
Comment, au travers d’un réseau étendu comme Internet, un ordinateur arrive-t-il à communiquer avec un autre situé à des kilomètres et dont il ne connaît à peu près rien si ce n’est son adresse IP ? Les réseaux de nombreux opérateurs publics et privés assurent une connexion physique entre les deux appareils. Mais ce n’est pas tout. Cela fonctionne parce que le protocole IP est routable. Les objectifs de cette série d’articles sont de vous présenter les principes du routage ainsi que la configuration des routeurs dans un réseau.
D’un point de vue utilisateur, nous considérons Internet comme sur la figure A : un immense et unique réseau. En réalité, Internet est composé d’un ensemble de réseaux reliés via des appareils particuliers : les routeurs (figure B).
Figure 61-1. Internet
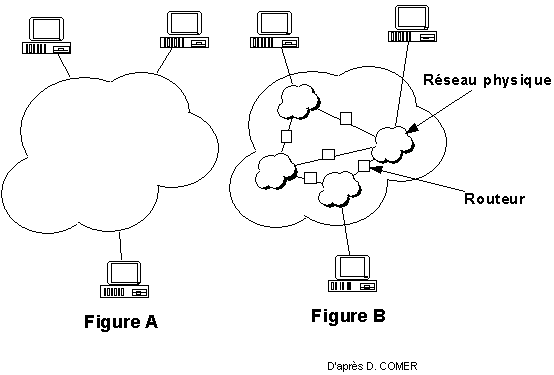
Le protocole IP est capable de choisir un chemin (une route) suivant lequel les paquets de données seront relayés de proche en proche jusqu’au destinataire. À chaque relais sur la route correspond un routeur. L’ordinateur émetteur du paquet de données doit trouver le premier relais. Ensuite, chaque routeur est chargé de trouver le suivant. Enfin, le dernier routeur remet le paquet sur le réseau du destinataire. Le routage IP fonctionne de façon totalement décentralisée au niveau des appareils qui constituent le réseau. Aucun n’a une vision globale de la route que prendront les paquets de données.
61.1.1. Les principes du routage
Avant d’aborder la partie pratique, je vais vous présenter quelques explications théoriques qui me semblent un préalable indispensable à une compréhension précise du routage. Je vais essayer de ne pas être trop long. Le routage IP repose sur quatre principes :
61.1.1.1. Une adresse IP est structurée
Chaque interface réseau d’un appareil possède une adresse IP unique dans tout le réseau global. Cette adresse est structurée en deux partie : la première partie (ou préfixe) donne le numéro du réseau. La seconde partie (ou suffixe) donne le numéro de l’interface dans ce réseau. Un masque est associé à cette adresse et permet au logiciel IP de déterminer le préfixe réseau d’une adresse en calculant un ET logique avec le masque. Exemple :Interface : eth0 Adresse IP : 192.168.2.254 Masque réseau : 255.255.255.0
192.168.2.1 ET 255.255.255.0 donne le préfixe réseau de l’adresse soit : 192.168.2.0
Si vous ne vous sentez pas à l’aise avec ces notions, inutile d’aller plus loin : je vous renvoie vers les précédents numéros de Linux magazine qui ont déjà traité ce point.
61.1.1.2. Les paquets de données comportent l’adresse IP de l’émetteur et du destinataire
Lors de l’émission, le protocole découpe les données en petits paquets (souvent appelés datagrammes IP). Ces paquets ont tous la même structure :
Figure 61-2. Datagramme

C’est l’en-tête qui contient, entre autre, les adresses de l’émetteur et du destinataire. Un appareil chargé du routage analysera l’adresse du destinataire afin d’aiguiller le paquet vers le prochain routeur menant à sa destination.
61.1.1.3. Chaque appareil possède une table de routage gérée par le logiciel IP
Une table de routage est une liste contenant essentiellement trois types d’information : des adresses réseau avec le masque réseau associé et le moyen de les atteindre. Soit le réseau est directement connecté à l’appareil, dans ce cas le moyen de l’atteindre est le nom de l’interface, soit, il s’agit de l’adresse du prochain routeur situé sur la route vers ce réseau. Par exemple, considérons sur un appareil quelconque, sa table de routage :
| Réseau | Masque | Moyen de l’atteindre |
| 192.168.2.0 | 255.255.255.0 | eth0 |
| 100.0.0.0 | 255.0.0.0 | eth1 |
| 101.0.0.0 | 255.0.0.0 | eth2 |
| 192.168.1.0 | 255.255.255.0 | 100.0.0.1 |
| 192.168.3.0 | 255.255.255.0 | 101.0.0.2 |
Cette table est riche d’enseignements. On apprend très précisemment que l’appareil possède trois interfaces réseau (eth0, eth1, eth2) ainsi que les adresses IP des réseaux qui sont directement reliés à ces interfaces. On connaît les adresses IP de deux routeurs. On sait qu’il existe deux réseaux 192.168.1.0 et 192.168.3.0 et qu’ils sont respectivement derrière les routeurs 100.0.0.1 et 101.0.0.2. Par contre, il est impossible d’affirmer que ces deux réseaux sont directement reliés à ces routeurs. Pour résumer, on peut dresser le schéma suivant :
Figure 61-3. Topologie 1
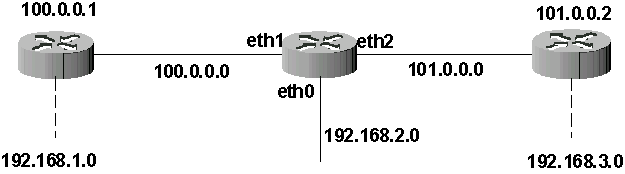
Quelques observations complémentaires :
- – étant donné que l’appareil observé possède trois interfaces, c’est très probablement un routeur. Cependant, notez que tout appareil fonctionnant sous TCP/IP possède une table de routage (qu’il soit routeur ou non);
- – pour que le routage fonctionne, il est impératif que toutes les interfaces réseau possédant le même préfixe réseau soient reliées au même réseau physique.
61.1.1.4. Tous les appareils sous IP exécutent le même algorithme
Lors de l’émission d’un paquet de données, le logiciel IP recherche une correspondance dans la table en appliquant le masque réseau de chaque ligne avec l’adresse IP de destination du paquet. Notez qu’il parcourt la table dans l’ordre décroissant des masques afin de garantir le best match (la correspondance la plus précise entre l’adresse dans la table et l’adresse de destination).
Au total, seules quatre possibilités sont imaginables :
- ce préfixe correspond à celui d’un réseau directement connecté : il y a remise directe du paquet sur le réseau et le routage est terminé.
- ce préfixe correspond à celui d’un réseau accessible via un routeur : on récupère l’adresse physique de ce routeur et on lui transmet le paquet. Notez que l’adresse IP de l’émetteur reste inchangée.
- ce préfixe n’a pas de correspondance dans la table mais il existe un routeur par défaut dans la table : on transmet au routeur par défaut.
- si aucun des trois cas précédents n’est rempli, on déclare une erreur de routage.
Si tous les appareils exécutent le même algorithme de routage, alors qu’est-ce qui différencie un simple ordinateur d’un routeur ? Un élément fondamental : un routeur est en mesure de relayer des paquets reçus et dont il n’est pas l’émetteur.
61.1.2. Place à la pratique
Voilà, vous savez tout sur les aspects théoriques. Une mise en pratique est maintenant indispensable. Je vous propose de travailler avec le routeur logiciel GNU Zebra. C’est, à mon sens, un excellent logiciel, pour les raisons suivantes :
- c’est un logiciel libre sous licence GNU ;
- il propose une interface de configuration interactive accessible via telnet ;
- il fonctionne selon une philosophie et un langage de configuration proche de routeurs répandus dans les entreprises (ce qui permet d’avoir accès à une bonne bibliographie);
- il supporte les principaux protocoles de routage (nous développerons ce point dans la deuxième partie de cet article);
- il fonctionne avec Ipv6.
Les manipulations présentées ci-après ont été réalisées avec Zebra 0.91a sous une Redhat 7.2. Ce logiciel est prévu pour fonctionner sous Linux (noyau 2.0.37 et suivants) et BSD. Une version pour Hurd est prévue.
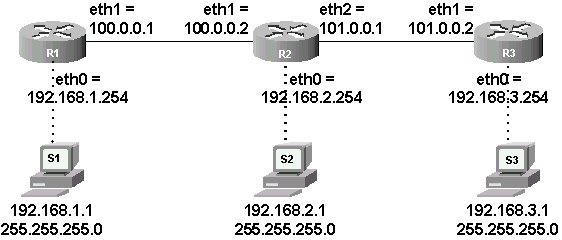
Je vous propose de travailler avec la maquette suivante :
Figure 61-4. Topologie pratique
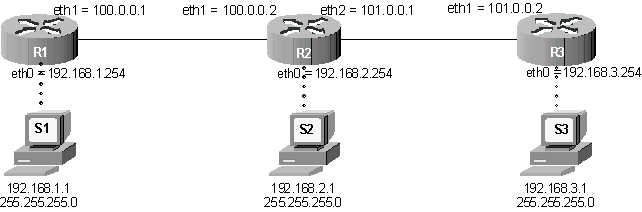
Ce réseau est composé de 3 routeurs (R1, R2 et R3) et de trois stations (S1, S2, S3). Je suppose que toutes les interfaces réseau sont actives et correctement configurées. Les masques réseau à utiliser sont les masques par défaut de la classe d’adresse (255.0.0.0 pour les adresses commençant par 100 et 101 et 255.255.255.0 pour les adresses commençant par 192).
61.1.2.1. Mise en place des routeurs
Zebra doit être installé sur chaque ordinateur qui fera office de routeur. Vous pouvez vous procurer des paquetages d’installation ou bien compiler le logiciel à partir des fichiers sources. Dans ce cas, l’installation se fait par les habituels ./configure ; make ; make install . Cette phase produit plusieurs exécutables (un par protocole de routage) mais nous n’utiliserons pour l’instant que zebra. En principe, les exécutables ont été copiés dans /usr/local/bin et les fichiers de configuration dans /usr/local/etc (ils portent le même nom que l’exécutable avec l’extension .conf). Suivant la méthode d’installation, ils pourront être situés ailleurs, ce n’est pas un problème. Pour une aide plus détaillée, reportez-vous sur mon site, vous y trouverez une traduction française du manuel.
Avant de charger le démon de routage, sur chaque routeur créez un fichier /usr/local/etc/zebra.conf. Insérez les deux lignes suivantes :hostname Rx(Zebra) ! remplacez le x par le numéro du routeurpassword foo
À la place de foo, indiquez le mot de passe que vous souhaitez saisir lorsque vous vous connecterez au routeur via telnet. Maintenant, vous pouvez lancer le démon de routage avec la commande zebra -d afin qu’il s’exécute en tâche de fond.
61.1.2.2. Configuration des stations
Plaçons-nous dans le shell de S1 et observons la configuration des interfaces :
S1 # ifconfigeth0 Lien encap:Ethernet HWaddr 00:50:56:40:40:98
inet adr:192.168.1.1 Bcast:192.168.1.255 Masque:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RXpackets:89 errors:0 dropped:0 overruns:0 frame:0*
TX packets:58 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 lg file transmission:100
RX bytes:6771 (6.6 Kb) TX bytes:3357 (3.2 Kb)
Interruption:10 Adresse de base:0x1080
lo Lien encap:Boucle locale
inet adr:127.0.0.1 Masque:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:77 errors:0 dropped:0 overruns:0 frame:0
TX packets:77 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 lg file transmission:0
RX bytes:4758 (4.6 Kb) TX bytes:4758 (4.6 Kb)
Cet appareil dispose d’une interface Ethernet active nommée eth0 ainsi que de l’interface de bouclage logiciel lo. Toute machine fonctionnant avec IP possède cette interface.
Je vous ai dit tout à l’heure que tout appareil fonctionnant sous IP disposait d’une table de routage. Listons le contenu de cette table sur S1 :
S1 # route
| Destination | Passerelle | Genmask | Indic | Metric | Ref | Use | Iface |
| 192.168.1.0 | * | 255.255.255.0 | U | 0 | 0 | 0 | eth0 |
| 127.0.0.0 | * | 255.0.0.0 | U | 0 | 0 | 0 | lo |
À partir des adresses IP des interfaces de l’ordinateur, le logiciel IP en a déduit cette table de routage élémentaire. Pour lui, toutes les machines qui disposent d’une adresse commençant par 192.168.1.0 sont forcément sur le réseau physique connecté à l’interface eth0.
Conclusion, si je tente un ping vers une adresse de ce réseau (et si une machine possède cette adresse), j’obtiens une réponse. Essayons entre S1 et R1 qui font partie du même réseau :
S1 # ping 192.168.1.254
PING 192.168.1.254 (192.168.1.254) from 192.168.1.1 : 56(84) bytes of data.
64 bytes from 192.168.1.254: icmp_seq=0 ttl=255 time=23.411 msec
Warning: time of day goes back, taking countermeasures.
64 bytes from 192.168.1.254: icmp_seq=1 ttl=255 time=2.308 msec
— 192.168.1.254 ping statistics —
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/mdev = 2.308/12.859/23.411/10.552 ms
Je cherche à contacter un appareil dont l’adresse commence par 192.168.1.0. Cette adresse figure dans la table routage, donc tout va bien.
Essayons maintenant de contacter l’interface eth1 de R1 :
S1 # ping 100.0.0.1 connect: Network is unreachable
La sanction est immédiate. En clair, votre système d’exploitation favori vous répond : « désolé, mais je n’ai absolument aucune idée de la façon dont je pourrais bien atteindre le réseau 100.0.0.0 ».
Pour résoudre ce problème, il faut que je renseigne ma table de routage et que j’indique comment atteindre le réseau 100.0.0.0. Sur le schéma, c’est très clair. Pour aller sur ce réseau, il faut passer par R1. Comme S1 ne peut joindre pour l’instant que les appareils dont l’adresse commence par 192.168.1.0, j’indiquerai comme moyen d’atteindre le réseau, l’adresse 192.168.1.254 qui est l’adresse IP de l’interface du routeur qui se situe sur le réseau de S1.Pour réaliser cette configuration, tapons la commande :
S1 # route add -net 100.0.0.0 netmask 255.0.0.0 gw 192.168.1.254
Félicitations ! Vous venez de saisir votre première commande de configuration de routage. Elle signifie que le réseau 100.0.0.0/8 (masque réseau sur 8 bits) est situé derrière le routeur (gw = gateway) d’adresse 192.168.1.254.Vous pouvez le tester, cette configuration fonctionne pour le réseau 100.0.0.0 mais si l’on généralise, il faudrait saisir pour tous les réseaux que l’on cherche à contacter, une commande identique ! Observez bien le schéma. R1 est le seul routeur directement accessible par S1. Quel que soit le réseau que S1 cherche à contacter, il ne peut être que derrière R1. Par conséquent, il existe une commande qui permet d’indiquer une route par défaut :
S1 # route add default gw 192.168.1.254
Listons le contenu de la table de routage :
s1 # route Table de routage IP du noyau
| Destination | Passerelle | Genmask | Indic | Metric | Ref | Use | Iface |
| 192.168.1.0 | * | 255.255.255.0 | U | 0 | 0 | 0 | eth0 |
| 127.0.0.0 | * | 255.0.0.0 | U | 0 | 0 | 0 | lo |
| 100.0.0.0 | 192.168.1.254 | 255.0.0.0 | U | 0 | 0 | 0 | eth0 |
| default | 192.168.1.254 | 0.0.0.0 | UG | 0 | 0 | 0 | eth0 |
La ligne commençant par 100.0.0.0 est devenue inutile. Supprimons la :
S1 # route del -net 100.0.0.0 netmask 255.0.0.0 gw 192.168.1.254
La plupart du temps, il n’existe qu’un seul routeur pour sortir d’un réseau d’extrémité. On configure alors sur chaque station l’adresse IP de ce routeur par défaut. Le logiciel IP crée une entrée dans sa table de routage identique à celle que nous venons d’observer. Vous devrez donc, sur chaque station de notre réseau définir l’adresse de son routeur par défaut, soit en tapant une commande route, soit en modifiant les fichiers de configuration des cartes réseau et en redémarrant.
Revenons sur S1 et testons notre configuration. Contactons à nouveau l’interface 100.0.0.1 du routeur R1 :
S1 # ping 100.0.0.1 PING 100.0.0.1 (100.0.0.1) from 192.168.1.1 :
56(84) bytes of data. Warning: time of day goes back, taking countermeasures.
64 bytes from 100.0.0.1: icmp_seq=0 ttl=255 time=3.746 msec
64 bytes from 100.0.0.1: icmp_seq=1 ttl=255 time=1.812 msec
— 100.0.0.1 ping statistics —
2 packets transmitted, 2 packets received, 0% packet
loss round-trip min/avg/max/mdev = 1.812/2.779/3.746/0.967 ms
Parfait ça marche ! Je devrais donc pouvoir également contacter R2 puisqu’il est lui aussi dans le réseau 100.0.0.0 :
S1 # ping 100.0.0.2 PING 100.0.0.2 (100.0.0.2) from 192.168.1.1 :
56(84) bytes of data. (il ne se passe rien, donc CTRL-C)
— 100.0.0.2 ping statistics —
10 packets transmitted,
0 packets received, 100% packet loss
Eh bien, ce n’est pas brillant. Certes, S1 n’indique plus de message d’erreur mais les paquets transmis ne sont jamais retournés. Vous vous doutez qu’il existe une solution. Profitons-en, c’est l’occasion de vous donner quelques éléments pour repérer un problème de routage.
61.1.2.3. Configuration des routeurs
Puisque le routage est une chaîne, il faut suivre les paquets dans chaque maillon afin de trouver l’origine du problème. Nous savons que l’interface eth1 du routeur R1 reçoit les paquets puisqu’elle nous les retourne. Donc, le problème vient de R2. Positionnons-nous dans le shell de R2, la commande tcpdump va nous aider à observer ce qu’il se passe sur son interface eth1 :
R2 # tcpdump -nt -i eth1 tcpdump: listening on eth1 192.168.1.1 >
100.0.0.2: icmp: echo request (DF) 192.168.1.1 >
100.0.0.2: icmp: echo request (DF)
Oui, elle reçoit les paquets… mais elle n’en retourne aucun. Vous l’avez compris : comme pour S1 tout à l’heure, R2 n’a aucune idée de l’endroit où se trouve le réseau de l’émetteur des paquets (192.168.1.0) puisque celui-ci n’est pas directement connecté. Il faut donc configurer sa table de routage. Pour ce faire, nous allons cette fois travailler avec Zebra. Zebra possède une interface telnet sur le port 2601. Dans le shell de R2, tapez :
R2 # telnet localhost 2601 Trying 127.0.0.1…
Connected to localhost.
Escape character is ‘^]’. Hello, this is zebra (version 0.91a).
Copyright 1996-2001 Kunihiro Ishiguro. User Access Verification Password:
Tapez le mot de passe que vous avez saisi dans le fichier zebra.conf , vous arrivez dans le mode de visualisation de la configuration du routeur. Ensuite, passez en mode de configuration (mode privilégié appelé mode enable dans le logiciel) :
R2(Zebra)> enable
Pour vous repérer dans Zebra, observez bien le prompt, il vous indique dans quel mode vous vous trouvez (par exemple, le # indique que vous êtes en mode privilégié). Ensuite, dans l’interpréteur de commande, vous pouvez saisir à tout moment un ? pour obtenir la liste contextuelle des commandes. Enfin, lorsque vous appuyez sur la touche tabulation, Zebra complète la commande en cours de saisie.
Observons la table de routage gérée par Zebra :
R2(Zebra)# show ip route
Codes: K – kernel route, C – connected, S – static,
R – RIP, O – OSPF, B – BGP, > – selected route,
* – FIB route
C>* 100.0.0.0/8 is directly connected, eth1
C>* 101.0.0.0/8 is directly connected, eth2
C>* 127.0.0.0/8 is directly connected, lo
C>* 192.168.2.0/24 is directly connected, eth0
Nous ne voyons aucune trace du réseau 192.168.1.0. C’est pour cela que R2 ne peut retourner les paquets ICMP à S1. Bien sûr, Zebra permet d’ajouter une route. Passons en mode « terminal de configuration » :
R2(Zebra)# configure terminal
Puis ajoutons la route :
R2(Zebra)(config)# ip route 192.168.1.0/24 100.0.0.1
Revenons au mode enable et listons à nouveau la table :
R2(Zebra)(config)# end
R2(Zebra)# show ip route
Codes: K – kernel route, C – connected, S – static,
R – RIP, O – OSPF, B – BGP, > – selected route,
* – FIB route
C>* 100.0.0.0/8 is directly connected, eth1
C>* 101.0.0.0/8 is directly connected, eth2
C>* 127.0.0.0/8 is directly connected, lo
S>* 192.168.1.0/24 [1/0] via 100.0.0.1, eth1
C>* 192.168.2.0/24 is directly connected, eth0
Une route statique (notée S) est apparue (vous apprendrez dans le prochain article comment configurer une route dynamique ainsi que la signification des nombres entre crochets [1/0]).
Un ping 100.0.0.2 depuis S1 passe désormais sans problème. Si l’on reprend le schéma du réseau, vous vous doutez que des manipulations similaires sont à réaliser pour le réseau de S3. Il faut donc ajouter une route vers 192.168.3.0/24. Vous connaissez maintenant les commandes :
R2(Zebra)# configure terminal
R2(Zebra)(config)# ip route 192.168.3.0/24 101.0.0.2
R2(Zebra)(config)# end
Visionnons la configuration en mémoire de Zebra :
R2(Zebra)# show running-config
Current configuration:
!
hostname R2(Zebra)
password foo
!
interface lo
!
interface eth0
!
interface eth1
!
interface eth2
!
ip route 192.168.1.0/24 100.0.0.1
ip route 192.168.3.0/24 101.0.0.2
!
line vty
!
end
Afin qu’à chaque démarrage de Zebra les routes statiques soient prises en compte, il faut enregistrer cette configuration « mémoire » vers le fichier zebra.conf :
R2(Zebra)# copy running-config startup-config
Configuration saved to /etc/zebra/zebra.conf
Bien, nous avons presque fini. Quelques routes sont à créer sur R1 et R3 pour que le routage sur notre réseau soit complet.
61.1.2.3.1. Une erreur à éviter
Sur R1, il faut créer une route vers 192.168.3.0. Une erreur fréquente consiste à créer la route suivante :
R1(Zebra)(config)# ip route 192.168.3.0/24 101.0.0.2
Ce qui signifie : le réseau 192.168.3.0/24 est situé derrière le routeur R3. Bien sûr, cette phrase est juste, mais souvenez-vous de ce que nous disions en introduction : le routage fonctionne de proche en proche. Ainsi, comme nous sommes sur R1, il suffit d’indiquer que le routeur nous permettant d’atteindre le réseau de S3 est R2 et non R3.
61.1.2.3.2. Configuration de R1
Ceci étant dit, voici la configuration de R1 :
R1(Zebra)# show running-config
Current configuration:
!
hostname
R1(Zebra) password foo
!
interface lo
!
interface eth0
!
interface eth1
!
ip route 101.0.0.0/8 100.0.0.2
ip route 192.168.2.0/24 100.0.0.2
ip route 192.168.3.0/24 100.0.0.2
!
line vty
!
end
61.1.2.3.3. Configuration de R3
Avant de lire ci-dessous, essayez de déterminer la configuration de R3. Elle est très proche de celle de R1.
R3(Zebra)# show running-config
Current configuration:
!
hostname
R3(Zebra) password foo
!
interface lo
!
interface eth0
!
interface eth1
!
ip route 100.0.0.0/8 101.0.0.1
ip route 192.168.1.0/24 101.0.0.1
ip route 192.168.2.0/24 101.0.0.1
!
line vty
!
end
Ouf ! Voilà, c’est fini. Vous devez pouvoir réaliser des ping de n’importe quelle machine vers n’importe quelle autre.
61.1.3. Conclusion
La configuration des routeurs peut vous sembler fastidieuse, voire impossible si le réseau comporte beaucoup de routeurs et que sa topologie évolue fréquemment. Il faudrait sans cesse reconfigurer les routeurs. Heureusement, le monde est bien fait : il existe des protocoles qui permettent aux routeurs de s’échanger les informations de routage dont ils disposent afin que les tables s’adaptent aux évolutions du réseau comme le protocole RIP par exemple.
Chapter 62. Le routage dynamique avec RIP
Initiation au routage RIP
62.1. Introduction
Le premier article sur le routage statique a présenté les concepts nécessaires à la bonne compréhension du routage IP. Nous avons vu que les routeurs sont de véritables postes d’aiguillage qui acheminent de proche en proche les paquets IP dans l’inter-réseau. On peut configurer manuellement des routes statiques sur chaque routeur. Mais dans un réseau important, cette tâche devient rapidement cauchemardesque ! Heureusement, des protocoles de routage ont été développés afin que les routeurs s’échangent les informations dont ils disposent. On parle dans ce cas de routage dynamique. L’objet de cet article est de vous présenter le fonctionnement et la mise en oeuvre d’un protocole de routage des plus élémentaires : RIP (Routing Information Protocol).
Avant d’aborder la partie pratique avec Zebra, nous évoquerons les avantages du routage dynamique en comparaison du routage statique. Nous détaillerons ensuite le fonctionnement du protocole RIP.
62.1.1. Pourquoi le routage dynamique ?
Comme nous l’avons défini dans le précédent article, le routage statique consiste à indiquer l’adresse IP des réseaux que l’on cherche à atteindre. On associe à chaque adresse, le nom de l’interface du routeur ou l’adresse IP du routeur voisin se situant sur la route vers ces réseaux de destination. Si le réseau global est complexe, la configuration peut être fastidieuse et source d’erreurs. De plus, lorsque un nouveau réseau est ajouté, il faut reconfigurer l’ensemble. Enfin, pour prévenir tout dysfonctionnement (panne d’un routeur, ligne coupée, etc.), il faut effectuer une surveillance permanente et reconfigurer chaque routeur le cas échéant. Si la route est rétablie, il faut recommencer la manipulation.
L’idée générale du routage dynamique est la suivante : plutôt que de centraliser la configuration du routage dans les mains d’un individu dont le temps de réaction est fatalement long et les risques d’erreurs importants, nous allons délocaliser cette tâche au niveau des routeurs. En effet, chaque appareil n’est-il pas le mieux placé pour connaître les adresses des réseaux auxquels il est directement relié puisque chacune de ses interfaces possède une adresse IP ? De plus, étant directement au contact des supports de communication, il peut établir un diagnostic sur l’état des liaisons. Fort de ces informations, il n’a plus qu’à les partager avec ses voisins. De proche en proche, les nouvelles se répandront à chaque routeur du réseau. L’intervention humaine se situera en amont dans la définition de directives et de règles à appliquer par les routeurs pour la diffusion des routes.
62.1.2. Le protocole RIP
Comme toujours, pour qu’une communication puisse s’établir, chaque interlocuteur doit parler la même langue. Il a donc été nécessaire de concevoir un protocole. RIP a été défini, pour sa version 1 dans la RFC 1058 et pour sa version 2 dans la RFC 2453. Par la suite, je ne traiterai que RIPv2. Toutefois, avant de passer à la partie pratique, nous évoquerons rapidement les différences entre ces deux versions.
62.1.2.1. Quelles informations de routage s’échanger ?
Le principe général est très simple. Un routeur RIP transmet à ses voisins les adresses réseau qu’il connaît (soit les adresses de ses interfaces, soit les adresses découvertes via les autres routeurs) ainsi que la distance pour les atteindre. Ces couples adresse/distance sont appelés vecteurs de distance.
62.1.2.2. La notion de distance
Nous touchons ici au concept de métrique, fondamental dans le domaine du routage. En effet, il arrive fréquemment (c’est même une situation recherchée pour des raisons de tolérance aux pannes) que le réseau ait une topologie maillée. Dans ce cas, plusieurs routes mènent à la même destination. Le routeur doit alors choisir la route qu’il considère la meilleure vers une destination donnée.
La seule métrique utilisée par RIP est la distance correspondant au nombre de routeurs à traverser (hop ou nombre de sauts) avant d’atteindre un réseau. Pour chaque route, RIP calcule la distance. Ensuite, si des routes redondantes apparaissent, RIP retient celle qui traverse le moins de routeur (donc avec la distance la plus faible).
Du fait de la méthode utilisée pour diffuser les routes, la longueur d’une route (et par voie de conséquence le diamètre du réseau) est limitée. La norme limite la distance maximale d’une route à quinze. Cela signifie que deux réseaux ne peuvent être éloignés de plus de quinze routeurs. Nous verrons ci-après qu’une distance égale à seize (distance « infinie » pour RIP) joue un rôle particulier en indiquant qu’une route est devenue inaccessible.
62.1.2.3. Un exemple
Prenons l’exemple simple du réseau sur lequel nous avons travaillé dans l’article précédent :
Figure 62-1. Topologie du réseau
Afin de bien comprendre le routage dynamique, supposons la situation initiale suivante : sur chaque routeur, toutes les interfaces réseau sont actives, aucune route statique n’est définie et le routage RIP est inactif.
Sur R1, lorsque l’on active le processus de routage RIP, une première table est constituée à partir des adresses IP des interfaces du routeur. Pour ces réseaux directement connectés au routeur, la distance est égale à un puisqu’il faut au moins traverser ce routeur pour les atteindre. On obtient :
| Adresse/Préfixe | Moyen de l’atteindre | Distance |
| 100.0.0.0/8 | eth1 | 1 |
| 192.168.1.0/24 | eth0 | 1 |
Tableau 1 : table initiale constituée par R1
R1 transmet à ses voisins immédiats (ici, il n’y a que R2) un seul vecteur de distance {192.168.1.0/24, 1} qui signifie : « je suis le routeur d’adresse IP 100.0.0.1 et je connaîs un moyen d’atteindre le réseau 192.168.1.0/24 en un saut ». Aucune information sur le réseau commun aux deux routeurs (100.0.0.0/8) n’est transmise car R1 considère que R2 connaît déjà ce réseau.
Ensuite, lorsque l’on active RIP sur R2, il constitue la table ci-après à partir de ses propres informations et de celles reçues de R1 :
| Adresse/Préfixe | Moyen de l’atteindre | Distance |
| 100.0.0.0/8 | eth1 | 1 |
| 101.0.0.0/8 | eth2 | 1 |
| 192.168.1.0/24 | 100.0.0.1 | 2 |
| 192.168.2.0/24 | eth0 | 1 |
Tableau 2 : table constituée par R2
Sur R2, RIP a calculé que la distance pour atteindre 192.168.1.0/24 est égale à deux puisqu’il faut traverser R2 puis R1. R2 a déduit le « moyen de l’atteindre » à partir de l’adresse IP de l’émetteur contenue dans le paquet RIP.
Lorsque RIP sera démarré sur R3, la route vers 192.168.3.0/24 avec une distance de deux sera ajoutée dans la table ci-dessus.
Dans ce petit exemple, aucune restriction n’a été définie sur la diffusion des routes. Donc, à l’issue d’un certain délai appelé temps de convergence, variable selon la taille du réseau, chaque routeur connaît un moyen d’atteindre chaque réseau.
62.1.2.4. Algorithme général de RIP
Examinons un peu plus en détail le fonctionnement de RIP. Lors de l’initialisation du routeur, celui-ci détermine l’adresse réseau de ses interfaces puis envoie sur chacune une demande d’informations (table RIP complète) aux routeurs voisins. Lors de la réception d’une demande, un routeur envoie sa table complète ou partielle suivant la nature de cette demande. Lors de la réception d’une réponse, il met à jour sa table si besoin. Deux cas peuvent se présenter :
- pour une nouvelle route, il incrémente la distance, vérifie que celle-ci est strictement inférieure à 15 et diffuse immédiatement le vecteur de distance correspondant ;
- pour une route existante mais avec une distance plus faible, la table est mise à jour. La nouvelle distance et, éventuellement, l’adresse du routeur si elle diffère sont intégrées à la table.
Bien sûr, si l’appareil reçoit une route dont la distance est supérieure à celle déjà connue, RIP l’ignore. Ensuite, à intervalles réguliers (les cycles durent 30 secondes environ), la table RIP est diffusée qu’il y ait ou non des modifications.
Des routes doivent être retirées de la table gérée par RIP dans deux situations.
En premier lieu, un réseau immédiatement connecté devient inaccessible (panne de l’interface, de la ligne, modification de la topologie par l’administrateur, etc.). Les routeurs RIP reliés à ce réseau affectent dans leur table une distance « infinie » (16 comme indiqué plus haut) à cette route. Elle est conservée pendant la durée d’un temporisateur de « maintien » (ou garbage collect) de 120 secondes puis est supprimée. Immédiatement puis pendant toute la durée de ce délai, le vecteur est diffusé. Un routeur qui reçoit un vecteur avec une distance de 16 comprend : « il faut que tu retires cette route de ta table car elle est devenue invalide ! ». De proche en proche, cette information se propage.
En second lieu, un routeur du réseau tombe en panne. Cela veut peut-être dire que les réseaux situés derrière cet appareil sont devenus inaccessibles. Mais comment savoir si un routeur est en panne ? RIP considère qu’un routeur qui n’a pas donné de nouvelles depuis trois minutes est hors-service. Pour gérer cette situation, il attribue à toutes les routes dynamiques un temporisateur initialisé à 180 secondes (par défaut). A chaque réception d’un vecteur de distance déjà présent dans la table, le compteur est réinitialisé. Mais si jamais ce compteur atteint zéro, la route est considérée comme invalide. On se retrouve alors dans la situation précédente (distance infinie, temporisateur de maintien, diffusion de l’information puis suppression de la route). Maintenant, si un autre routeur connaît une route menant vers un des réseaux que l’on vient de retirer, c’est parfait ! Notre routeur intègrera cette nouvelle route dans sa table : RIP permet la tolérance aux pannes.
Comment justifier l’existence de ces mécanismes qui peuvent paraître un peu complexes ? Cela est dû à une faiblesse des algorithmes à vecteurs de distance que l’on appelle « problème de la convergence lente ». Dans certains cas, après la panne d’un accès réseau, deux routeurs voisins risquent de se transmettre mutuellement puis, ensuite, de propager des informations contradictoires au sujet de ce réseau et créer ainsi une boucle de routage infinie. Zebra met en oeuvre les mécanismes nommés « split horizon » (une information de routage reçue d’une interface n’est jamais retransmise sur celle-ci), « poison reverse » (temporisateur de maintien) et « triggered update » (une panne est immédiatement diffusée sans attendre le prochain cycle de diffusion des tables) afin d’empêcher ce phénomène et de réduire le délai de convergence.
62.1.2.5. Améliorations de RIPv2 par rapport à RIPv1
Même si les principes évoqués ci-dessus sont valables quelle que soit la version de RIP, les différences restent intéressantes à relever. Les améliorations de RIPv2 sont :
- diffusion des masques de sous-réseaux associés aux adresses réseaux (RIPv1 n’utilisait que les masques réseau par défaut) ;
- utilisation d’adresses multicast pour diffuser les vecteurs de distance au lieu d’adresses de broadcast, ce qui réduit l’encombrement sur le réseau ;
- support de l’authentification en transportant un mot de passe crypté avec MD5 ;
- interopérabilité entre protocoles de routage en diffusant des routes apprises à partir d’autres protocoles.
L’ensemble de ces raisons rendent RIPv1 obsolète bien qu’il soit supporté par la plupart des routeurs logiciels ou matériels.
62.1.3. Place à la pratique
Afin de mieux apprécier les facilités offertes par le routage dynamique, je vous propose de travailler sur une topologie légèrement modifiée afin d’introduire un lien redondant. Voici le plan :
Figure 62-2. Topologie de travail
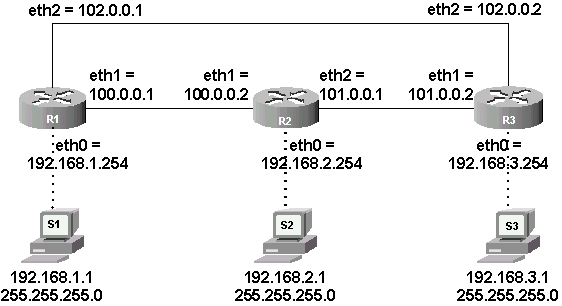
Que vous ayez suivi ou non la première partie de cet article, vous devez partir sur chaque appareil avec un fichier de configuration du routeur Zebra (/usr/local/etc/zebra.conf) vierge à l’exception de ces deux lignes :
hostname Rx(Zebra) ! remplacez le x par le numéro du routeur
password foo
Vous devez également créer un fichier de configuration pour le routeur RIP (/usr/local/etc/ripd.conf) ayant une apparence très proche de celui de Zebra :
hostname Rx(RIP) ! remplacez le x par le numéro du routeur
password foo
Lorsque ces manipulations sont faites, lancez les deux démons de routage sur les trois routeurs en respectant l’ordre des commandes, par exemple sur R1 :
R1 # zebra -d
R1 # ripd -d
Zebra nécessite que les deux démons soient présents car son architecture est la suivante :
Figure 62-3. Architecture de Zebra
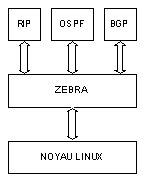
Le démon zebra est un intermédiaire entre le noyau de Linux et les démons de routage dynamique. Il peut récupérer les routes statiques définies directement sous Linux afin de les diffuser via le routage dynamique.
zebra lui-même permet de définir des routes statiques. Enfin, il peut récupérer des routes dynamiques pour les intégrer à la table de routage gérée par le noyau Linux. Routages statique et dynamique peuvent cohabiter sans problème avec Zebra mais les concepteurs du logiciel conseillent fortement de ne définir les routes statiques que dans zebra (évitez de les définir dans le shell Linux ou dans les démons de routage dynamique).
62.1.3.1. Activation de RIP sur le premier routeur
Afin d’observer la diffusion des routes qu’opère RIP, je vous propose de saisir la commande suivante dans le shell d’un routeur immédiatement voisin de R1, R2 par exemple :
R2 # tcpdump -i eth1 -nt -s 0 src host
100.0.0.1tcpdump: listening on eth1
Ensuite, connectons-nous au routeur RIP sur R1 avec un telnet sur le port 2602. Dans le shell de R1 :
R1 # telnet localhost 2602
Trying 127.0.0.1…
Connected to localhost.
Escape character is ‘^]’.
Hello, this is zebra (version 0.91a).
Copyright 1996-2001 Kunihiro Ishiguro.
User Access Verification
Password:
R1(RIP) >
Cette opération étant réalisée, comme pour zebra il faut activer le mode privilégié, passer dans le terminal de configuration et enfin, entrer dans la configuration du routeur RIP :
R1(RIP)> enable
R1(RIP)#conf t
R1(RIP)(config)# routerrip
R1(RIP)(config-router)#
La première tâche consiste à déterminer les types de routes en notre « possession » que nous souhaitons voir diffuser à nos voisins. Cette configuration se fait par la commande redistribute. Voici les différents paramètres de cette commande :
R1(RIP)(config-router)# redistribute ?
bgp Border Gateway Protocol (BGP)
connected Connected
kernel Kernel routes
ospf Open Shortest Path First (OSPF)
static Static routes
On constate que l’on peut diffuser des routes propres à la machine comme les routes statiques et les adresses des réseaux directement connectés. Mais nous pouvons également utiliser RIP pour diffuser des routes dynamiques apprises via RIP ou d’autres protocoles de routage comme OSPF ou BGP. Dans tous les cas, les routes diffusées aux voisins seront vues par eux comme des routes étiquetées « découvertesgrâce à RIP ».
Nous choisissons de diffuser les adresses des réseaux directement connectés :
R1(RIP)(config-router)# redistribute connected
Pour l’instant, rien ne se produit. Il faut indiquer à RIP sur quels réseaux nous souhaitons voir la diffusion des routes s’opérer. Nous retrouvons ici une commande commune avec le routage statique. Avant de la valider, pensez à observer le résultat du tcpdump sur l’écran de R2 :
R1(RIP)(config-router)# network 100.0.0.0/8
À ce stade, R1 diffuse sur le réseau 100.0.0.0/8 la table RIP à intervalles de 30 secondes. Le résultat sur R2 doit ressembler à ceci :
R2 # tcpdump -i eth1 -nt -s 0 src host 100.0.0.1
tcpdump: listening on eth1
100.0.0.1.router > 224.0.0.9.router: RIPv2-req 24 (DF) [ttl 1]
100.0.0.1 > 224.0.0.9: igmp v2 report 224.0.0.9 (DF) [ttl 1]
100.0.0.1.router > 224.0.0.9.router: RIPv2-resp [items 2]:
{102.0.0.0/255.0.0.0}(1)
{192.168.1.0/255.255.255.0}(1) (DF) [ttl 1]
Les messages adressés par R1 se font via une adresse multicast convenue pour les routeurs RIP : 224.0.0.9. Les dernières lignes montrent clairement que RIP diffuse deux vecteurs de distance : un concernant le réseau 102.0.0.0/8 et un autre concernant le réseau 192.168.1.0/24. Observons sur R1 la table avec laquelle RIP travaille :
R1(RIP)(config-router)# end
R1(RIP)# show ip rip
Codes: R – RIP, C – connected, O – OSPF, B – BGP
| Network | NextHop | Metric | From | Time | |
| C | 100.0.0.0/8 | 1 | |||
| C | 102.0.0.0/8 | 1 | |||
| C | 192.168.1.0/24 | 1 |
R1(RIP)#
RIP a été activé sur le réseau 100.0.0.0/8, donc aucune information le concernant n’est diffusée sur ce même réseau pour des raisons évidentes d’optimisation mais aussi, pour la gestion du problème de la convergence lente.
62.1.3.2. Activation de RIP sur le deuxième routeur
Bien, nous avons fait la moitié du travail. Un routeur diffuse grâce à RIP les informations de routage qu’il possède. Mais pour l’instant, c’est inefficace car personne n’est là pour les écouter et les exploiter. Il faut donc faire les mêmes manipulations sur R2 puis à terme sur R3. Passons dans le shell de R2 :
R2 # telnet localhost 2602
…
R2(RIP)> enable
R2(RIP)# conf t
R2(RIP)(config)# router rip
R2(RIP)(config-router)# redistribute connected
R2(RIP)(config-router)# network 100.0.0.0/8
R2(RIP)(config-router)# end
R2(RIP)# show ip rip
Codes: R – RIP, C – connected, O – OSPF, B – BGP
| Network | NextHop | Metric | From | Time | |
| C | 100.0.0.0/8 | 1 | |||
| C | 101.0.0.0/8 | 1 | |||
| R | 102.0.0.0/8 | 100.0.0.1 | 2 | 100.0.0.1 | 02:52 |
| R | 192.168.1.0/24 | 100.0.0.1 | 2 | 100.0.0.1 | 02:52 |
| C | 192.168.2.0/24 | 1 |
R2(RIP)#
La table ci-dessus a été constituée par le processus RIP tournant sur R2. Le routeur d’adresse 100.0.0.1 (R1) l’a informé de la présence de deux routes vers deux réseaux, ce qui est conforme aux informations affichées par tcpdump tout à l’heure. La distance (Metric) est égale à deux puisque ces réseaux sont directement connectés à R1. Un compteur est activé pour chaque route dynamique notée R (pour RIP). C’est un compte à rebours qui périodiquement repart de 03:00 à chaque diffusion reçue de R1.
Vous pouvez faire un show ip rip sur R1 afin de constater qu’il a opéré un travail similaire.
62.1.3.3. Filtrer la diffusion des routes
Lorsque l’on saisit un « redistribute connected » dans RIP, le routeur diffuse toutes les routes de type « directement connectées », sans distinction. Difficile de garder une certaine « intimité » dans ces conditions ! Zebra, qui est bien conçu, propose des mécanismes pour filtrer la diffusion des routes grâce aux « listes de distribution ».
Supposons qu’un nouveau réseau soit connecté à R2. Pour les besoins de l’exemple, vous pouvez créer une interface fictive simulant ce réseau. Dans le shell Linux, créons cette interface :
R2 # ifconfig dummy0 111.0.0.1/8 up
Zebra détecte cette nouvelle interface et transmet l’information à RIP. Comme à ce stade, RIP doit diffuser toutes les routes connectées. Il informe immédiatement ses voisins. Vérifions ceci sur R1 :
R1(RIP)# show ip rip
Codes: R – RIP, C – connected,O – OSPF, B – BGP
| Network | NextHop | Metric | From | Time | |
| C | 100.0.0.0/8 | 1 | |||
| R | 101.0.0.0/8 | 100.0.0.2 | 2 | 100.0.0.2 | 02:43 |
| C | 102.0.0.0/8 | 1 | |||
| R | 111.0.0.0/8 | 100.0.0.2 | 2 | 100.0.0.2 | 02:43 |
| C | 192.168.1.0/24 | 1 | |||
| R | 192.168.2.0/24 | 100.0.0.2 | 2 | 100.0.0.2 | 02:43 |
R1(RIP)#
On constate que R1 a appris l’existence de 111.0.0.0/8. Nous allons interdire à R2 de diffuser l’existence de ce réseau à ses petits camarades. Pour ce faire, il faut créer une règle indiquant que l’adresse 111.0.0.0/8 est bloquée grâce à une liste d’accès. Ensuite, il faut affecter cette règle à une liste de distribution qui indiquera sur quelle interface l’appliquer. Retournons sur R2, dans le terminal de configuration de RIP :
R2(RIP)> enableR2(RIP)# conf t
Définition de la règle :
R2(RIP)(config)# access-list 1 deny 111.0.0.0/8
R2(RIP)(config)# access-list 1 permit any
Le « 1 » après « access-list » identifie la liste d’accès. Ce numéro sera utilisé pour l’associer à la liste de distribution. N’oubliez pas la deuxième ligne. Il faut dire explicitement à RIP que toutes les autres adresses ne sont pas bloquées.
Maintenant, affectons la liste d’accès à une liste de distribution. Il faut indiquer sur quelles interfaces ces règles sont à appliquer :
R2(RIP)(config)# router rip
R2(RIP)(config-router)# distribute-list 1 out eth1
R2(RIP)(config-router)# distribute-list 1 out eth2
À partir de cet instant, plus aucune information n’est diffusée par R2 concernant 111.0.0.0/8. Sur R1, avec un
show ip rip
, vous constaterez que le temporisateur de la route tombe à 0. Elle se voit ensuite attribuer une métrique infinie pendant le délai du temporisateur « garbage collect » puis elle disparaît.
Dans notre exemple, le résultat de cette manipulation est que les réseaux directement connectés au routeur R2, en particulier 192.168.2.0/24 qui contient des ordinateurs, peuvent communiquer avec 111.0.0.0/8. En revanche, l’extérieur n’a pas connaissance du réseau 111.0.0.0/8 qui ne peut pas communiquer avec les réseaux situés derrière les autres routeurs.
Cet article n’a pas la prétention de présenter toutes possibilités offertes par les listes d’accès et les listes de distribution qui sont, en fait, très nombreuses. La documentation du logiciel indique l’ensemble des paramètres de ces différentes commandes.
62.1.3.4. Paramétrage de RIP
Toute la configuration de RIP peut être affichée sous une forme synthétique. Par exemple, sur le routeur R1, en mode privilégié (#) :
R1(RIP)# show ip protocols Routing Protocol is « rip »
Sending updates every 30 seconds with +/-50%, next due in 35 Timeout
after 180 seconds, garbage collect after 120 seconds Outgoing update
filter list for all interface is not set Incoming update filter list for
all interface is not set Default redistribution metric is 1
Redistributing: connected Default version control: send version 2,
receive version 2
| Interface | Send | Recv | Key-chain |
| eth1 | 2 | 2 |
Routing for Networks: 100.0.0.0/8 Routing Information
Sources:
| Gateway | BadPackets | BadRoutes | Distance | LastUpdate |
| 100.0.0.2 | 0 | 0 | 120 | 00:00:34 |
Distance: (default is 120)
Examinons brièvement les principaux champs. Les différents temporisateurs sont fixés aux valeurs par défaut. Aucun filtrage des routes en entrée comme en sortie n’est défini. La métrique par défaut de ce routeur est égale à un (c’est cette valeur qui sera ajoutée aux distances des routes apprises dynamiquement). Zebra supporte les deux versions de RIP que l’on peut faire cohabiter mais par défaut, Zebra n’autorise en réception comme en émission que la version 2. Le routage n’est activé pour l’instant que sur l’interface Ethernet 1. Aucun mot de passe n’est défini (nous aborderons cette notion un peu plus loin). La dernière ligne concerne la distance administrative. Comme cette notion est importante, nous la développons ci-dessous.
62.1.3.5. La distance administrative
La dernière ligne du listing précédent évoque une « distance » dont la valeur par défaut est 120. Il s’agit de la distance administrative. Elle n’a aucun rapport avec la distance (métrique) en nombre de sauts calculée par RIP.
Zebra peut constituer une table de routage à partir de routes apprises de différentes manières (réseau directement connecté, route statique, RIP, OSPF, BGP). Si Zebra se trouve avec plusieurs routes menant vers un même réseau mais rapportée par des moyens différents, il doit en choisir une. Il a été décidé d’attribuer à chaque moyen d’apprendre une route un score. La route découverte par un moyen dont le score est le plus faible sera élue. Les distances administratives standards sont les suivantes :
| Moyen de découvrir une route | Distance administrative |
| Connected | 0 |
| Static | 1 |
| BGP | 20 |
| OSPF | 110 |
| RIP | 120 |
Tableau 3 : distances administratives par défaut
Ainsi, une route configurée de façon statique (donc par un administrateur) est jugée plus crédible qu’une même route rapportée par RIP (notez au passage que RIP est considéré comme le moins crédible…). On retrouve cette notion de distance administrative dans la table de routage de Zebra. Sur R1, connectez-vous avec telnet au terminal de configuration de Zebra (dans le shell, faites un
telnet localhost 2601
, puis saisissez le mot de passe) :
R1(Zebra)> show ip route
Codes: K – kernel route, C – connected,
S – static, R – RIP, O – OSPF, B – BGP,
> – selected route, * – FIB route
C>* 100.0.0.0/8 is directly connected, eth1
R>* 101.0.0.0/8 [120/2] via 100.0.0.2, eth1, 00:08:11
C>* 102.0.0.0/8 is directly connected, eth2
C>* 127.0.0.0/8 is directly connected, lo
C>* 192.168.1.0/24 is directly connected, eth0
R>* 192.168.2.0/24 [120/2] via 100.0.0.2, eth1, 00:08:11
R1(Zebra)>
Les deux routes dynamiques notées R comportent deux nombres entre crochets ([120/2]). Le premier correspond à la distance administrative et le deuxième à la distance en nombre de sauts.
Remarque importante
J’en profite pour bien préciser que la table ci-dessus est la table de routage, donc utilisée par l’appareil pour router les paquets IP reçus sur ses interfaces réseau. La table que vous consultez dans RIP en faisant un
show ip rip
n’est pas la table de routage, c’est la table qui sera diffusée aux routeur voisins. La signification de ces deux tables est donc radicalement différente.
62.1.3.6. Avant de continuer
Je vous invite maintenant à activer RIP sur vos trois routeurs en redistribuant les adresses des réseaux immédiatement connectés sur tous les réseaux. Vous connaissez les manipulations à effectuer. A la fin du processus, chaque routeur doit connaître les adresses des six réseaux ainsi que le moyen de les atteindre. Pour information, je vous donne le contenu du fichier de configuration de R3 (ripd.conf) :
hostname R3(RIP)
password foo
!
interface lo
!
interface eth0
!
interface eth1
!
interface eth2
!
router rip
redistribute connected
network 101.0.0.0/8
network 102.0.0.0/8
!
line vty
!
end
Vous pouvez également, si vous le souhaitez, modifier la valeur par défaut des temporisateurs utilisés par RIP afin de visionner plus rapidement le résultat des manipulations que nous allons réaliser par la suite. Ceci se fait de la façon suivante, par exemple dans R1 :
R1(RIP)# conf t
R1(RIP)(config)# router rip
R1(RIP)(config-router)# timers basic 10 30 20
Notez bien qu’en exploitation, je vous conseille vivement de conserver ces compteurs à leur valeur par défaut. Avec les durées que nous avons indiqué ici, une partie importante de votre bande passante va être consommée par les diffusions de RIP.
62.1.3.7. La tolérance aux pannes
Supposons que la liaison entre R1 et R2 va tomber en panne. Visionnons la table RIP de R1 avant ce triste événement :
R1(RIP)> show ip rip
Codes: R – RIP, C – connected, O – OSPF, B – BGP
| Network | Next Hop | Metric | From | Time | |
| C | 100.0.0.0/8 | 1 | |||
| R | 101.0.0.0/8 | 100.0.0.2 | 2 | 100.0.0.2 | 02:52 |
| C | 102.0.0.0/8 | 1 | |||
| C | 192.168.1.0/24 | 1 | |||
| R | 192.168.2.0/24 | 100.0.0.2 | 2 | 100.0.0.2 | 02:52 |
| R | 192.168.3.0/24 | 102.0.0.2 | 2 | 102.0.0.2 | 02:36 |
Le réseau 100.0.0.0/8 tombe en panne. R1 ne reçoit donc plus d’informations de routage à partir de R2. Si vous observez la table RIP sur R1, vous verrez que toutes les routes issues de R2 finissent par disparaître. Mais pendant ce temps, R3 continue à envoyer des mises à jour via le réseau 102.0.0.0/8. R3 connaît un moyen d’atteindre les réseaux que l’on pouvait joindre auparavant par R2. Aussi, au bout d’un certain délai de convergence, R1 construit la table suivante :
R1(RIP)> show ip rip
Code: R – RIP, C – connected, O – OSPF, B – BGP
| Network | Next Hop | Metric | From | Time | |
| R | 100.0.0.0/8 | 102.0.0.2 | 3 | 102.0.0.2 | 02:34 |
| R | 101.0.0.0/8 | 102.0.0.2 | 2 | 102.0.0.2 | 02:34 |
| C | 102.0.0.0/8 | 1 | |||
| C | 192.168.1.0/24 | 1 | |||
| R | 192.168.2.0/24 | 102.0.0.2 | 3 | 102.0.0.2 | 02:34 |
| R | 192.168.3.0/24 | 102.0.0.2 | 2 | 102.0.0.2 | 02:34 |
Tous les réseaux sont à nouveau accessibles à partir de R1 ! Cela démontre que RIP a su digérer une panne de liaison. Rétablissons le lien entre R1 et R2. Progressivement, on retourne vers la première table car les métriques via R2 sont plus faibles.
62.1.3.8. Un problème de sécurité
Le routage dynamique est pratique car avec très peu de commandes de configuration on arrive à une solution qui fonctionne correctement et qui est même capable de prendre en compte automatiquement des modifications de la topologie. Seulement voilà : imaginez qu’un petit malin insère sur le réseau un routeur RIP et qu’il lui fasse diffuser des routes totalement farfelues. Cela peut créer un certain nombre de désagréments comme des dénis de service par exemple. Pour limiter ce risque, RIPv2 permet d’associer un mot de passe crypté à chaque diffusion de vecteurs de distance. Seuls les routeurs ayant connaissance de ce mot de passe traiteront les informations de routage. Mettons en place ce mécanisme entre R1 et R2 :
R1(RIP)# conf t
R1(RIP)(config)# key chain test
R1(RIP)(config-keychain)# key 1
R1(RIP)(config-keychain-key)# key-string motdepasse
R1(RIP)(config-keychain-key)# exit
R1(RIP)(config-keychain)# exit
R1(RIP)(config)# int eth1
R1(RIP)(config-if)# ip rip authentication mode md5
R1(RIP)(config-if)# ip rip authentication key-chain test
R1(RIP)(config-if)#
Nous créons le porte-clé (keychain) nommé « test » avec le mot de passe « motdepasse ». Ce mot de passe est associé à l’interface eth1, il sera transmis au format MD5 (sinon, il est transmis en clair !). Pour que cela fonctionne, vous devrez faire des manipulations identiques sur R2.
Examinons sur le réseau avec une capture de paquets, le contenu des informations de routage reçues de R2 :
R1 # tcpdump -i eth1 -nt -s0 src host 100.0.0.2
tcpdump: listening on eth1
100.0.0.2.router > 224.0.0.9.router: RIPv2-resp [items 6]:
[auth 3: 0068 0114 3cfb 0c6f 0000 0000 0000 0000]
{101.0.0.0/255.0.0.0}(1)
{102.0.0.0/255.0.0.0}(2)
{192.168.2.0/255.255.255.0}(1)
{192.168.3.0/255.255.255.0}(2)
[auth 1: 4d71 f8e0 077c cc58 8247 6656 17c3 95f2]
(DF) [ttl 1]
Notez au passage que seul le mot de passe est crypté, les informations de routage continuent à circuler en clair.
62.1.4. Conclusion
RIP constitue un excellent moyen pédagogique pour aborder la problématique du routage dynamique. Mais il est peu utilisé en exploitation car il souffre de certaines limitations et défauts qui le cantonnent à des réseaux de taille moyenne. Nous avons vu que le diamètre maximum d’un réseau géré avec RIP est limité à 15 routeurs soit 16 segments de réseau. RIP est un gros consommateur de bande passante du fait de la méthode utilisée pour diffuser les informations de routage (toutes les 30 secondes, l’intégralité de la table RIP est diffusée même si elle n’a subi aucune modification). C’est fâcheux, en particulier sur des liaisons lentes ou facturées au volume de données transférées. La métrique utilisée ne garantit pas que le routage soit optimal. En effet, la distance masque les caractéristiques réelles de la voie de transmission (débit ou coût en particulier). Enfin, le temps de convergence, délai avant que tous les routeurs ne possèdent des tables cohérentes peut être long dans certaines situations. Pour toutes ces raisons, on a cherché à développer un protocole de routage beaucoup plus efficace : OSPF, objet du prochain article.
Chapter 63. Le routage dynamique avec OSPF
Initiation au routage OSPF
63.1. Introduction
Ce texte suit le la séquence sut le routage statique et le routage dynamique avec RIP.
63.1.1. Rappels sur les éléments vus
Le routeur est un élément essentiel dans l’aiguillage des paquets de données dans un inter-réseau. Pour chaque paquet reçu, il extrait le préfixe réseau de l’adresse IP de destination du paquet et le recherche dans une table qu’il possède en mémoire. Cette table de routage contient essentiellement une liste d’adresses réseau et, pour chacune, le moyen de l’atteindre, à savoir l’adresse d’un routeur immédiatement voisin et situé sur la route vers la destination. Si le routeur trouve dans cette table le préfixe réseau, il transmet le paquet sur le réseau du routeur voisin concerné. Ce processus sera renouvelé par le routeur voisin et ainsi de suite, de proche en proche le paquet sera orienté vers sa destination.
Seulement voilà, il faut saisir les tables de routage ! Travail fastidieux pour les petits doigts agiles de l’administrateur lorsque les réseaux sont de grande taille. De plus, compte tenu de l’évolution du nombre de réseaux à interconnecter dans le cas d’internet, il est de toute façon devenu impossible de se cantonner au routage statique (voir séquence sur le routage statique). C’est pourquoi, le routage dynamique a été imaginé afin d’alléger la charge d’administration mais aussi pour réaliser des réseaux tolérants aux pannes d’un routeur ou d’une liaison. RIP est un bon exemple de protocole de routage dynamique*. Les routeurs supportant RIP s’échangent des informations sur les routes qu’ils possèdent (les fameux « vecteurs de distance »). Si une panne se produit, les routeurs immédiatement voisins notent que certaines routes sont devenues inaccessibles et propagent l’information aux autres. Mais hélas, RIP souffre de certaines limitations qui ont poussé l’IETF (Internet Engineering Task Force) à plancher sur un protocole plus robuste, plus efficace, plus paramétrable et supportant des réseaux de grande taille. Cette merveille s’appelle OSPF (Open Shortest Path First), protocole supporté par Zebra.
63.1.2. Les grands principes
OSPFest un protocole de routage dynamique défini par l’IETF à la fin des années 80. Il a fait l’objet d’un historique relativement complexe de RFC. Ce protocole a deux caractéristiques essentielles : – il est ouvert (le Open de OSPF), son fonctionnement peut être connu de tous ; – il utilise l’algorithme SPF (Shortest Path First), plus connu sous le nom d’algorithme de Dijkstra, afin d’élire la meilleure route vers une destination donnée.
Examinons une topologie qui nous servira de support pour les explications :
Figure 63-1. Exemple de topologie
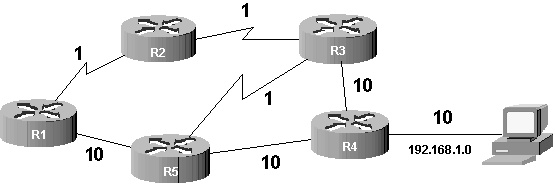
63.1.2.1. La notion de coût
Supposons que du routeur R1 on cherche à atteindre le réseau 192.168.1.0. Dans une telle situation, RIP aurait élu la route passant par R5 puisque c’est la plus courte en termes de saut. Cependant, imaginez que les liens représentés sous forme d’éclairs soient « rapides » (type Ethernet à 100 Mbps par exemple) et que les liens « droits » soient « lents » (type Ethernet à 10 Mbps par exemple). Le choix de RIP n’est plus du tout pertinent !
OSPF fonctionne différemment. Il attribue un coût à chaque liaison (dénommée lien dans le jargon OSPF) afin de privilégier l’élection de certaines routes. Plus le coût est faible, plus le lien est intéressant. Par défaut, les coûts suivants sont utilisés en fonction de la bande passante du lien :
| Type de réseau | Coût par défaut |
| Ethernet > = 100 Mbps | 1 |
| FDDI | 1 |
| Ethernet 10 Mbps | 10 |
| E1 (2,048 Mbps) | 48 |
| T1 (1,544 Mbps) | 65 |
| 64 Kbps | 1562 |
| 56 Kbps | 1785 |
| 19.2 Kbps | 5208 |
La formule de calcul est simplissime : coût = référence / bande passante du lien. Par défaut, la référence est 100 000 000 correspondant à un réseau à 100 Mbps.
OSPF privilégie les routes qui ont un coût faible, donc celles qui sont supposées rapides en terme de débit théorique.
63.1.2.2. La base de données topologique
Avec OSPF, tous les routeurs d’un même réseau (on parle de « zone » dans le vocabulaire OSPF, ceci vous sera expliqué avant la mise en pratique) travaillent sur une base de données topologique identique qui décrit le réseau. Cette base a été constituée pendant une première phase de découverte qui vous sera expliquée un peu plus loin. Examinons la base de données suivante qui décrit la topologie de la figure 1 :
| Arc | Coût |
| R1, R2 | 1 |
| R1, R5 | 10 |
| R2, R3 | 1 |
| R3, R4 | 10 |
| R3, R5 | 1 |
| R4, R5 | 10 |
| R4, 192.168.1.0 | 10 |
63.1.2.3. L’élection des meilleures routes
L’algorithme du SPF de Dijsktra va traiter cette base de données afin de déterminer les routes les moins coûteuses. Une fois le traitement réalisé, chaque routeur se voit comme la racine d’un arbre contenant les meilleures routes. Par exemple :
Figure 63-2. Le réseau vu de R1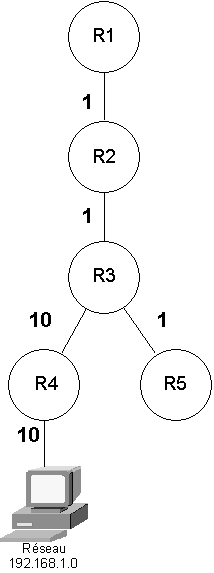 |
Figure 63-3. Le réseau vu de R5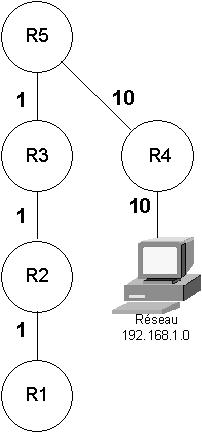 |
Dans l’exemple, entre R1 et 192.168.1.0, la meilleure route passe par R2, R3 et R4 pour un coût total de 1 + 1 + 10 + 10 soit 22.
63.1.2.4. La détermination d’une table de routage
La base de données topologique décrit le réseau mais ne sert pas directement au routage. La table de routage est déterminée par l’application de l’algorithme du SPF sur la base topologique. Sur R1, voici un extrait de la table de routage calculée par SPF au sujet du réseau 192.168.1.0 :
| Réseau de destination | Moyen de l’atteindre | Coût |
| 192.168.1.0 | R2 | 22 |
Sur R5, on aura l’extrait suivant :
| Réseau de destination | Moyen de l’atteindre | Coût |
| 192.168.1.0 | R4 | 20 |
63.1.3. Le fonctionnement d’OSPF un peu plus en détail
Pour administrer un réseau OSPF correctement, il est indispensable de comprendre le fonctionnement interne du protocole.
à l’intérieur d’une même zone, les routeurs fonctionnant sous OSPF doivent préalablement remplir les tâches suivantes avant de pouvoir effectuer leur travail de routage :
- établir la liste des routeurs voisins ;
- élire le routeur désigné (et le routeur désigné de secours) ;
- découvrir les routes ;
- élire les routes à utiliser ;
- maintenir la base de donnée topologique.
63.1.3.1. 0. état initial
Le processus de routage OSPF est inactif sur tous les routeurs de la figure 1.
63.1.3.2. Établir la liste des routeurs voisins : Hello, my name is R1 and I’m an OSPF router.
Les routeurs OSPF sont bien élevés. Dès qu’ils sont activés, ils n’ont qu’une hâte : se présenter et faire connaissance avec leurs voisins. En effet, lorsque le processus de routage est lancé sur R1 (commande router ospf), des paquets de données (appelés paquets HELLO) sont envoyés sur chaque interface où le routage dynamique a été activé (commande network). L’adresse multicast 224.0.0.5 est utilisée, tout routeur OSPF se considère comme destinataire. Ces paquets ont pour but de s’annoncer auprès de ses voisins. Deux routeurs sont dits voisins s’ils ont au moins un lien en commun. Par exemple, sur la figure 1, R1 et R2 sont voisins mais pas R1 et R3.Lorsque le processus de routage OSPF est lancé sur R2, celui-ci récupère les paquets HELLO émis par R1 toutes les 10 secondes (valeur par défaut du temporisateur appelé hello interval). R2 intègre l’adresse IP de R1 dans une base de données appelée « base d’adjacences » (adjacencies database). Cette base contient les adresses des routeurs voisins. Vous pourrez visionner son contenu grâce à la commande show ip ospf neighbor. R2 répond à R1 par un paquet IP unicast. R1 intègre l’adresse IP de R2 dans sa propre base d’adjacences. Ensuite, généralisez ce processus à l’ensemble des routeurs de la zone.
Cette phase de découverte des voisins est fondamentale puisque OSPF est un protocole à état de liens. Il lui faut connaître ses voisins pour déterminer s’ils sont toujours joignables et donc déterminer l’état du lien qui les relie.
63.1.3.3. Élire le routeur désigné : c’est moi le chef !
Dans une zone OSPF, l’un des routeurs doit être élu « routeur désigné » (DR pour Designated Router) et un autre « routeur désigné de secours » (BDR pour Backup Designated Router). Le DR est un routeur particulier qui sert de référent au sujet de la base de données topologique représentant le réseau.
Pourquoi élire un routeur désigné ? Cela répond à trois objectifs :
- réduire le trafic lié à l’échange d’informations sur l’état des liens (car il n’y a pas d’échange entre tous les routeurs mais entre chaque routeur et le DR) ;
- améliorer l’intégrité de la base de données topologique (car il y a une base de données unique) ;
- accélérer la convergence (souvenez-vous, c’était le talon d’Achille de RIP).
Comment élire le DR ? Autrement dit, qui va se taper la corvée d’expliquer à ses petits camarades la topologie du réseau ? On ne demande pas qui sait parler anglais ou couper les cheveux comme au temps de la conscription Mais comme il faut bien un critère, le routeur élu est celui qui a la plus grande priorité. La priorité est un nombre sur 8 bits fixé par défaut à 1 sur tous les routeurs. Pour départager les routeurs ayant la même priorité, c’est celui avec la plus grande adresse IP qui est élu. Le BDR sera le routeur avec la deuxième plus grande priorité. Afin de s’assurer que votre routeur préféré sera élu DR, il suffit de lui affecter une priorité supérieure à 1 avec la commande ospf priority. Vous devrez faire ceci avant d’activer le processus de routage sur les routeurs car, une fois élu, le DR n’est jamais remis en cause même si un routeur avec une priorité plus grande apparaît dans la zone.
63.1.3.4. Découvrir les routes
Il faut maintenant constituer la base de données topologique. Les routeurs communiquent automatiquement les routes pour les réseaux qui participent au routage dynamique (ceux déclarés avec la commande network). Zebra étant multiprotocole, il peut également diffuser des routes provenant d’autres sources que OSPF, grâce à la commande redistribute.
Chaque routeur (non DR ou BDR) établit une relation maître/esclave avec le DR. Le DR initie l’échange en transmettant au routeur un résumé de sa base de données topologique via des paquets de données appelés LSA (Link State Advertisement). Ces paquets comprennent essentiellement l’adresse du routeur, le coût du lien et un numéro de séquence. Ce numéro est un moyen pour déterminer l’ancienneté des informations reçues. Si les LSA reçus sont plus récents que ceux dans sa base topologique, le routeur demande une information plus complète par un paquet LSR (Link State Request). Le DR répond par des paquets LSU (Link State Update) contenant l’intégralité de l’information demandée. Ensuite, le routeur (non DR ou BDR) transmet les routes meilleures ou inconnues du DR.
L’administrateur peut consulter la base de données topologique grâce à la commande show ip ospf database.
63.1.3.5. Élire les routes à utiliser
Lorsque le routeur est en possession de la base de données topologique, il est en mesure de créer la table de routage. L’algorithme du SPF est appliqué sur la base topologique. Il en ressort une table de routage contenant les routes les moins coûteuses.
Il faut noter que sur une base de données topologique importante, le calcul consomme pas mal de ressources CPU car l’algorithme est relativement complexe.
63.1.3.6. Maintenir la base topologique
Lorsqu’un routeur détecte un changement de l’état d’un lien (cette détection se fait grâce aux paquets HELLO adressés périodiquement par le routeur à ses voisins), celui-ci émet un paquet LSU sur l’adresse multicast 224.0.0.6 : le DR et le BDR de la zone se considèrent comme destinataires. Le DR (et le BDR) intègre cette information à sa base topologique et diffuse l’information sur l’adresse 224.0.0.5 (tous les routeurs OSPF sans distinction). C’est le protocole d’inondation.Toute modification de la topologie déclenche une nouvelle exécution de l’algorithme du SPF et une nouvelle table de routage est constituée.
Voilà pour les principes fondamentaux d’OSPF mais des notions importantes restent à évoquer si vous souhaitez déployer OSPF sur de grands réseaux (en particulier sur le fonctionnement d’OSPF sur un réseau point à point et sur l’agrégation de routes). Si vous voulez approfondir, reportez-vous au livre de C. Huitema cité en bibliographie qui, bien qu’un peu ancien est très complet sur la question. Bien sûr, vous pouvez toujours vous plonger dans les différentes RFC qui constituent OSPF (la RFC 2328 en particulier) et dont la lecture est toujours aussi agréable et passionnante ! (je plaisante, bien sûr).
Avant d’attaquer la pratique, un dernier concept : les zones OSPF.
63.1.3.7. Le concept de zone (area)
Contrairement à RIP, OSPF a été pensé pour supporter de très grands réseaux. Mais, qui dit grand réseau, dit nombreuses routes. Donc, afin d’éviter que la bande passante ne soit engloutie dans la diffusion des routes, OSPF introduit le concept de zone (area). Le réseau est divisé en plusieurs zones de routage qui contiennent des routeurs et des hôtes. Chaque zone, identifiée par un numéro, possède sa propre topologie et ne connaît pas la topologie des autres zones. Chaque routeur d’une zone donnée ne connaît que les routeurs de sa propre zone ainsi que la façon d’atteindre une zone particulière, la zone numéro 0. Toutes les zones doivent être connectées physiquement à la zone 0 (appelée backbone ou réseau fédérateur). Elle est constituée de plusieurs routeurs interconnectés. Le backbone est chargé de diffuser les informations de routage qu’il reçoit d’une zone aux autres zones. Tout routage basé sur OSPF doit posséder une zone 0.
Figure 63-4. Un réseau découpé en trois zones
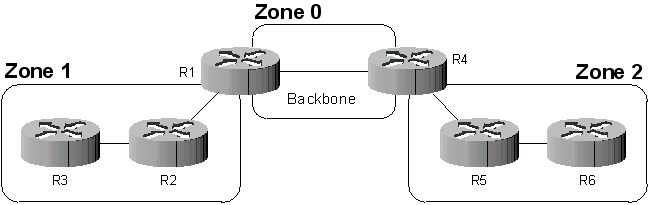
Le réseau est découpé en trois zones dont le backbone. Les routeurs de la zone 1, par exemple, ne connaissent pas les routeurs de la zone 2 et encore moins la topologie de la zone 2. L’intérêt de définir des zones est de limiter le trafic de routage, de réduire la fréquence des calculs du plus court chemin par l’algorithme SPF ainsi que d’avoir une table de routage plus petite (ce qui accélère la convergence). Les routeurs R1 et R4 sont particuliers puisqu’ils sont « à cheval » entre plusieurs zones (on les appelle ABR pour Area Border Router ou routeur de bordure de zone). Ces routeurs maintiennent une base de données topologique pour chaque zone à laquelle il sont connectés. Les ABR sont des points de sortie pour les zones ce qui signifie que les informations de routage destinées aux autres zones doivent passer par l’ABR local à la zone. L’ABR se charge alors de retransmettre les informations de routage au backbone. Les ABRs du backbone ensuite redistribueront ces informations aux autres zones auxquelles ils sont connectés.
63.1.4. Place à la pratique
Nous allons travailler avec le réseau suivant :
Figure 63-5. Topologie de travail
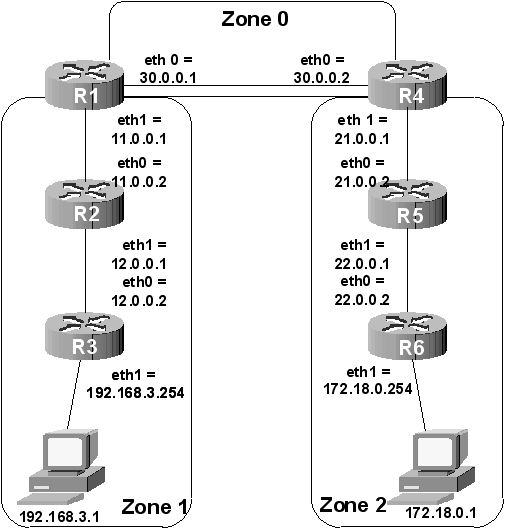
Le réseau a été découpé en trois zones. Vous remarquez que la zone 0 permet de fédérer l’ensemble du réseau. Il s’agit du backbone dont nous avons déjà discuté. Le découpage de ce réseau en trois zones est un cas d’école dont le but est d’examiner la configuration d’OSPF dans un contexte multi-zone. Généralement, on considère qu’une zone peut accueillir plusieurs dizaines de routeurs.
Pour ne pas surcharger ces lignes inutilement, nous nous en tiendrons ici à la configuration de R1, R2 et R3. Vous verrez que la configuration n’est pas très complexe. Par symétrie, il est facile de l’adapter aux autres routeurs. Pour votre service, chers lecteurs, j’ai mis en ligne une carte cliquable (http://perso.club-internet.fr/pmassol/lm/ospf.html) qui vous permettra de consulter l’état, la configuration complète et la table de routage des six routeurs.
Enfin, avant de commencer, vous trouverez sur http://perso.club-internet.fr/pmassol/zebra.html une traduction (partielle) de la documentation de Zebra.
63.1.4.1. Situation de départ
Vous devez créer des fichiers de configuration pour zebra (/etc/zebra/zebra.conf) et ospfd (/etc/zebra/ospfd.conf) rudimentaires sur chaque routeur. Par exemple, pour R1 :
– fichier zebra.conf :
hostname R1(ZEBRA) password foo
– fichier ospfd.conf :
hostname R1(OSPF) password foo
Vous devez ensuite démarrer (ou redémarrer), dans l’ordre s’il vous plaît, les deux démons zebra et ospfd sur chaque routeur. Enfin, sur R1 entrez dans le terminal de configuration de ospfd via le port telnet 2604 :
L
inux# telnet localhost 2604
Hello, this is zebra (version 0.91a).
Copyright 1996-2001 Kunihiro Ishiguro.
User Access Verification
Password:
R1(OSPF)> enable
R1(OSPF)#
Si vous avez envie de suivre précisément les échanges de messages entre routeurs, Zebra propose un puissant mécanisme de débogage grâce à la commande debug (je vous laisse découvrir tous ses paramètres). Supposons que je veuille garder une trace de tous les messages HELLO émis par R1 :
R1(OSPF)# conf t
R1(OSPF)(config)# log file /var/log/zebra/ospfd.log
R1(OSPF)(config)# debug ospf packet hello send detail
Il faut que le répertoire /var/log/zebra existe.
63.1.4.2. Activation du processus de routage
Dans le mode « config », nous allons activer le processus OSPF :
R1(OSPF)(config)# routerospf
R1(OSPF)(config-router)#
63.1.4.3. 2. Activation des annonces de routes
Le processus de routage OSPF est activé mais rien ne se passe. Comme pour RIP, il faut indiquer sur quel(s) réseau(x) on souhaite que le routage dynamique soit opérationnel. Ceci se fait par la commande network. Mais, nouveauté par rapport à RIP qui n’intègre pas le concept de zone, il faut indiquer à quelle zone sera rattaché le réseau. Sur la figure 5, on voit que R1 est relié à deux réseaux. Le réseau 30.0.0.0/8 est attaché à la zone 0 et le réseau 11.0.0.0/8 à la zone 1. La configuration se fait donc de cette manière :
R1(OSPF)(config-router)# network 30.0.0.0/8 area 0
R1(OSPF)(config-router)# network 11.0.0.0/8 area 1
Que se passe-t-il sur le réseau ? R1 envoie des paquets HELLO sur les interfaces pour lesquelles la commande network a été saisie. Mais personne n’est là pour les écouter. Activez le routage sur R2 en adaptant les commandes aux spécificités du routeur. Je vous aide un peu. Sur R2, vous réaliserez les configurations suivantes :
R2(OSPF)(config-router)# network 11.0.0.0/8 area 1
R2(OSPF)(config-router)# network 12.0.0.0/8 area 1
Enfin, sur R3, vous réaliserez les configurations suivantes :
R3(OSPF)(config-router)# network 12.0.0.0/8 area 1
R3(OSPF)(config-router)# network 192.168.3.0/24 area 1
Mais sur R3, il y a une particularité. Le réseau 192.168.3.0/24 contient des ordinateurs mais aucun routeur. La commande network va diffuser sur ce réseau des annonces de routes ce qui consomme inutilement de la bande passante. Par conséquent, nous allons désactiver cette diffusion :
R3(OSPF)(config-router)# passive-interface eth1
Ainsi, aucune route n’est diffusée sur cette interface. De même, aucune annonce de route ne sera prise en compte. Le réseau sera considéré comme étant d’extrémité (stub).
63.1.4.4. Affichage de la configuration
Affichons la configuration complète de R1 :
R1(OSPF)(config-router)# end
R1(OSPF)# show running-config
Current configuration:
!
hostname R1(OSPF)
password foo
!
!
!
interface lo
!
interface eth0
!
interface eth1
!
router ospf
network 11.0.0.0/8 area 1
network 30.0.0.0/8 area 0
!
line vty
!
end
Affichons la configuration complète de R3 :
R3(OSPF)# show running-config
Current configuration:
!
hostname R3(OSPF)
password foo
!
!
!
interface lo
!
interface eth0
!
interface eth1
!
router ospf
passive-interface eth1
network 12.0.0.0/8 area 1
network 192.168.3.0/24 area 1
!
line vty
!
end
J’espère que vous avez la même configuration. Si ce n’est pas le cas, vous pouvez annuler une ligne contenant une erreur en vous remettant au même endroit où vous avez saisi la commande et en saisissant à nouveau la commande, mais en la faisant précéder de no.
Pour enregistrer la configuration, je vous rappelle que l’on saisit :
R1(OSPF)# copy running-config startup-config
Reproduisez maintenant ces manipulations sur l’ensemble des routeurs du réseau.
63.1.4.5. État des routeurs
Nos petits routeurs ont, en principe, bien travaillé. Dans chaque zone, ils ont élu leur chef (le DR), ils ont échangé leurs connaissances et calculé une magnifique table de routage, ultra-optimale. En résumé, les deux stations d’extrémité de la figure doivent pouvoir s’atteindre avec une commande ping. Si jamais ce n’est pas le cas, c’est que probablement vous vous êtes trompé dans une configuration. Dans ce cas, reprenez la configuration de chaque appareil. Utilisez les outils ping, tcpdump et traceroutE pour contrôler votre configuration et suivre les paquets. Et n’oubliez pas que dans un ping, il y a un aller mais aussi un retour !
Afin d’illustrer ce dont nous avons discuté dans la toute première partie de cet article, examinons l’état du routeur R1. Nous pouvons faire un diagnostic très complet de l’appareil en utilisant les nombreuses sous-commandes de show ip ospf. Vous constaterez que les informations fournies par ospfd sur son état sont beaucoup plus conséquentes que celles que l’on pouvait extirper de ripd.
Dans un premier temps, je vous propose d’examiner l’état de santé général du routeur R3 :
R3(OSPF)# show ip ospf
OSPF Routing Process, Router ID: 192.168.3.254
Supports only single TOS (TOS0) routes
This implementation conforms to RFC2328
RFC1583Compatibility flag is disabled
SPF schedule delay 5 secs, Hold time between two SPFs 10 secs
Refresh timer 10 secs
Number of external LSA 0
Number of areas attached to this router: 1
Area ID: 0.0.0.1
Shortcutting mode: Default, S-bit consensus: no
Number of interfaces in this area: Total: 2, Active: 2
Number of fully adjacent neighbors in this area: 1
Area has no authentication
Number of full virtual adjacencies going through this area:
0
SPF algorithm executed 13 times
Number of LSA 9
Le premier bloc décrit le fonctionnement général du routeur : l’ID du routeur (égale à sa plus grande adresse IP), conformité aux RFC, valeurs des temporisateurs. Une seule zone est attachée à ce routeur. C’est la zone 1 (exprimée en notation décimale pointée). Notre routeur a deux interfaces dans la zone, il n’a qu’un seul voisin. L’algorithme du SPF a été exécuté 13 fois. La base de données topologique contient neuf états de liens (LSA). Si notre routeur était attaché à plusieurs zones, le deuxième bloc serait répété autant de fois que de zones. Vous pourrez le constater sur R1.
Maintenant, listons nos informations sur les routeurs voisins :
R3(OSPF)# show ip ospf neighbor
| Neighbor ID | Pri | State | Dead Time | Address | Interface | RXmtL | RqstL | DBsmL |
| 12.0.0.1 | 1 | Full/Backup | 00:00:34 | 12.0.0.1 | eth0 | 0 | 0 | 0 |
Déchiffrons ces informations. La différence entre la colonne ID et la colonne Address, c’est que l’ID identifie l’appareil dans le réseau alors que l’adresse correspond à l’interface à laquelle nous sommes relié avec ce routeur. La colonne State nous apprend deux choses : il est synchronisé avec le routeur désigné grâce à la mention « Full », c’ est le « routeur désigné de secours » de la zone grâce à l’indicateur Backup. Ce routeur sera déclaré comme inactif si nous ne recevons pas de message HELLO d’ici 34 secondes (Dead Time).
Voyons le contenu de la base de données topologique de R3 :
R3(OSPF)# show ip ospF database
OSPF Router with ID (192.168.3.254)
Router Link States (Area 0.0.0.1)
| Link ID | ADV Router | Age | Seq# | CkSum | Link count |
| 12.0.0.1 | 12.0.0.1 | 981 | 0x80000006 | 0xf9e2 | 2 |
| 30.0.0.1 | 30.0.0.1 | 952 | 0x80000003 | 0xb13e | 1 |
| 192.168.3.254 | 192.168.3.254 | 1063 | 0x80000005 | 0x15b7 | 2 |
Net Link States (Area 0.0.0.1)
| Link ID | ADV Router | Age | Seq# | CkSum |
| 11.0.0.2 | 12.0.0.1 | 981 | 0x80000001 | 0xda39 |
| 12.0.0.2 | 192.168.3.254 | 1063 | 0x80000001 | 0x5d0b |
Summary Link States (Area 0.0.0.1)
| Link ID | ADV Router | Age | Seq# | CkSum | Route |
| 21.0.0.0 | 30.0.0.1 | 837 | 0x80000001 | 0x0d08 | 21.0.0.0/8 |
| 22.0.0.0 | 30.0.0.1 | 702 | 0x80000001 | 0x64a5 | 22.0.0.0/8 |
| 30.0.0.0 | 30.0.0.1 | 976 | 0x80000001 | 0x33e2 | 30.0.0.0/8 |
| 172.18.0.0 | 30.0.0.1 | 599 | 0x80000001 | 0x4a0d | 172.18.0.0/24 |
Ces trois tableaux présentent de façon synthétique l’ensemble des LSA stockés dans la base topologique. Le premier tableau contient des LSA diffusés par chaque routeur. Ils décrivent l’état des interfaces de chaque routeur. Le deuxième tableau contient des LSA diffusés par le routeur désigné. Ils décrivent la liste des routeurs présents dans chaque réseaux. Le dernier tableau contient un résumé des routes diffusées par le routeur de bordure de zone (ABR). Ce sont des routes qu’il a reçu via le backbone par les routeurs des autres zones. L’âge et le numéro de séquence sont utilisés pour mettre à jour la base lorsque des LSA sont reçus. Le check sum est utilisé pour contrôler l’intégrité des LSA.
Pour obtenir des informations détaillées sur chaque LSA, vous pouvez compléter la commande show ip ospf database par router, network ou summary. Par exemple : show ip ospf database router 192.168.3.254 (qui correspond à la troisième ligne du premier tableau) vous apprendra que ce router est relié à deux réseaux : un de transit (12.0.0.0/8) et un d’extrémité (stub) 192.168.3.0/24.
Enfin, si vous voulez consulter la table de routage obtenue après traitement par SPF des différents LSA, vous n’aurez qu’à saisir un show ip ospf route. Rappel important : il y a une différence entre cette table et celle utilisée par le démon zebra pour le routage proprement dit. Souvenez-vous que Zebra est multi-protocole et qu’il a une architecture modulaire (voir LM 43). Chaque démon calcule une table de routage à partir des informations dont il dispose (et qui ne sont pas nécessairement les mêmes pour chaque démon). Ensuite, ils transmettent chacun leur table au démon zebra qui en fait la synthèse. Cette synthèse constitue la véritable table de routage utilisée pour router les paquets.
Nous avons fait un tour d’horizon des principales commandes de Zebra permettant de surveiller l’état de ospfd. Il y en a encore beaucoup d’autres que je vous laisse découvrir (faites un show ip ospf ? par exemple). Il nous reste à observer la table de routage obtenue par zebra. Quittez ospfd et connectez-vous sur le démon zebra (telnet localhost 2601) :
R3(Zebra)> show ip route
Codes: K – kernel route, C – connected, S – static,
R – RIP, O – OSPF,B – BGP,
> – selected route, * – FIB route
O>* 11.0.0.0/8 [110/20] via 12.0.0.1, eth0, 00:12:48
O 12.0.0.0/8 [110/10] is directly connected, eth0,
00:14:09
C>* 12.0.0.0/8 is directly connected, eth0
O>* 21.0.0.0/8 [110/40] via 12.0.0.1, eth0, 00:11:18
O>* 22.0.0.0/8 [110/50] via 12.0.0.1, eth0, 00:10:16
O>* 30.0.0.0/8 [110/30] via 12.0.0.1, eth0, 00:12:13
C>* 127.0.0.0/8 is directly connected, lo
O>* 172.18.0.0/24 [110/60] via 12.0.0.1, eth0, 00:08:48
O 192.168.3.0/24 [110/10] is directly connected, eth1,
00:14:19
C>* 192.168.3.0/24 is directly connected, eth1
Les routes notées O ont été découvertes par OSPF. Entre crochets, on observe la distance administrative du protocole (110 par défaut pour OSPF) et le coût de la route pour accéder au réseau. Dans ma topologie, il n’y a que des réseaux à 10 Mbits/s, donc avec un coût par défaut de 10 pour chaque lien.
63.1.4.6. Quelques éléments sur la sécurité
63.1.4.6.1. Filtrer la diffusion des routes
Le premier inconvénient d’un protocole de routage dynamique comme OSPF est sa volubilité. Il a tendance à dévoiler tout un tas d’informations sur les réseaux qu’un administrateur consciencieux n’a pas forcément envie de révéler. Pour limiter la diffusion des routes au strict minimum, ospfd intègre, à l’instar de ripd, un mécanisme d’access-lists. Reportez-vous à l’article publié sur Zebra dans Linux Magazine 43. La configuration est strictement identique. J’en profite pour faire un peu de publicité : si vous êtes intéressés par les problèmes de sécurité, je vous conseille l’excellent magazine M.I.S.C. La série d’articles sur la « protection de l’infrastructure réseau IP » constitue sur certains points un approfondissement intéressant.
63.1.4.6.2. Protéger les annonces de routes
Le deuxième inconvénient d’un protocole de routage dynamique comme OSF est sa naïveté. Il croit tout ce qu’on lui dit ! Un petit malin pourrait s’amuser à diffuser des routes farfelues à vos routeurs, ce qui pourrait provoquer des dénis de service. Pour pallier à cela, on peut activer l’authentification des annonces sur une zone. Voici les manipulations à réaliser sur chaque routeur :
Routeur(OSPF)(config-router)# area 1 authentication message-digest
Ensuite, pour chaque interface participant à la diffusion des routes :
Routeur(OSPF)(config)# int ethx
Routeur(OSPF)(config-if)# ospf message-digest-key 1 md5 motdepasse
Vous adapterez motdepasse à vos besoins. Ce mot de passe doit bien sûr être connu de tous les routeurs.
63.1.5. Conclusion
OSPF est un protocole de routage dynamique moderne, robuste et conçu pour les grands réseaux. On constate qu’il est nettement plus complexe que RIP. Pas forcément dans sa configuration mais dans son fonctionnement interne. Un inconvénient de ce protocole est qu’il peut être gourmand en puissance de calcul et en mémoire lorsque le réseau comporte beaucoup de routes ou qu’il y a de fréquentes modifications de topologie.
OSPF est un protocole IGP (Interior Gateway Protocol), c’est-à-dire qu’il agit au sein d’un système autonome. Un AS (Autonomous System) est un ensemble de réseaux gérés par un administrateur commun. Chaque système autonome possède un numéro identifiant sur 16 bits délivré par l’IANA (Internet Assigned Numbers Authority) ou ses délégations. Classiquement, les multinationales, les opérateurs de télécom ou les fournisseurs d’accès à Internet détiennent un système autonome. Pour assurer le routage entre les systèmes autonomes, un protocole de type EGP (Exterior Gateway Protocol) doit être mis en oeuvre. Dans le cas d’Internet, c’est généralement BGP (Border Gateway Protocol) qui assume cette mission. BGP, protocole supporté par Zebra, constitue un vaste terrain d’investigation.
Chapter 64. Le routage dynamique avec BGP
Initiation au routage BGP
64.1. Introduction
Internet relie des réseaux appartenant à des acteurs (entreprises, administrations, opérateurs de télécommunication, fournisseurs d´accès…) très différents. Il est peu probable qu´un consensus se dégage naturellement autour d´un même algorithme de routage dynamique et d´une même métrique. Ajoutons que des accords sont passés entre ces acteurs afin d´acheminer le trafic dans l´Internet et que celui-ci franchit des frontières, ce qui impose de respecter les réglementations locales. Le protocole BGP (Border Gateway Protocol) a été conçu pour répondre à ces problèmes. Comme toujours, nous allons aborder brièvement son fonctionnement avant de passer à une mise en pratique avec Zebra.
64.1.1. Les grands principes
BGP achemine les informations de routage entre les réseaux reliés à Internet.
64.1.1.1. Le concept de système autonome
Au sein d´une même organisation, les décisions concernant la topologie ou la politique de routage sont, en général, prises par une autorité unique. Par conséquent, le routage à l´intérieur de l´organisation est basé sur la confiance et un protocole de type IGP comme OSPF est mis en oeuvre. Un réseau fonctionnant sous une autorité unique est appelé un système autonome (AS). En pratique, un AS regroupe un ou plusieurs réseaux et un ou plusieurs routeurs ainsi que le montre l´exemple de la figure 1 :
Figure 64-1. Un système autonome constitué de réseaux
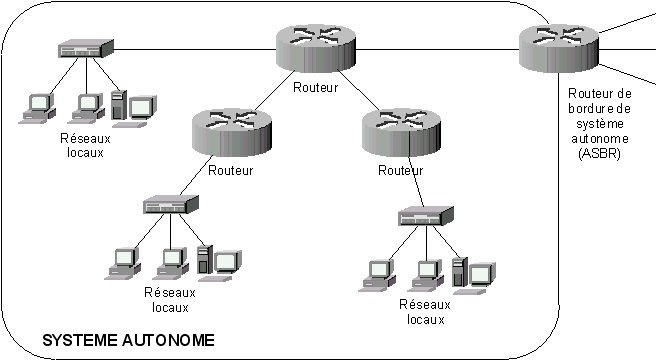
Les AS sont identifiés par un numéro sur 16 bits unique attribué par les mêmes organismes qui affectent les adresses IP. Il existe une plage de numéros d´AS privés de 64 512 à 65 535 pour ceux qui ne possèdent pas de numéro d´AS public.
À l´intérieur de votre AS, vous pouvez bien faire ce que vous voulez. Vous préférez tel protocole de routage ? Vous estimez que telle métrique est plus pertinente ? Tant mieux, cela ne regarde que vous. La seule contrainte, c´est que vous devrez désigner un ou plusieurs routeurs, à la frontière de votre AS, pour propager les informations d´accessibilité de vos réseaux et collecter les informations d´accessibilité des autres ASBR.
Par exemple, si l´on reprend la topologie présentée dans la séquence sur OSPF, que l´on en fait un AS, on obtiendrait :
Figure 64-2. Un AS découpé en zones OSPF
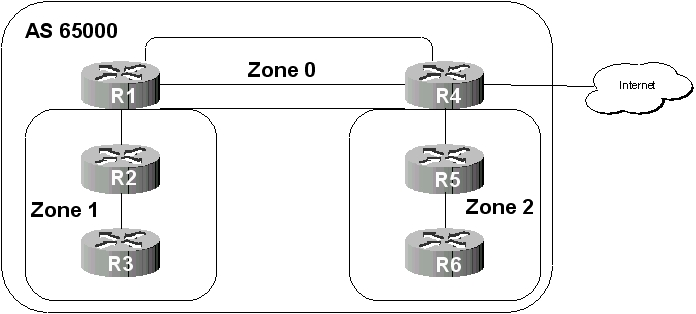
Ce système autonome utilise OSPF en tant qu´IGP. Il est découpé en trois zones. R4 est le routeur de bordure de zone. Celui-ci doit fonctionner sous BGP.
64.1.1.2. Les politiques de routage
Internet est un maillage de réseaux. Cela signifie que plusieurs chemins existent entre deux réseaux d´extrémité (figure 3). Mais ceux-ci ne sont pas tous équivalents.
Figure 64-3. Réseaux d’AS
En effet, imaginez vos datagrammes circulant dans cette jungle cruelle et barbare qu´est Internet. Vous préfèrerez peut être qu´ils transitent par tel AS, car l´administrateur est un pote ou que vous avez négocié un tarif avantageux. Vous refuserez peut-être qu´ils transitent par tel AS car vos flux sont incompatibles avec la législation en vigueur dans le pays ou pour toute autre considération politique, économique ou de sécurité que l´on peut imaginer. Dans ce cas, vous aurez besoin de définir une politique de routage sur Internet. BGP vous rendra ce service.
Dans le réseau, l´administrateur de l´AS 600 définit une politique de routage. Il veut joindre l´AS 200 en passant par les AS 300 et 100.
64.1.1.3. Les informations de routage échangées par BGP
Une des particularités de BGP-IV (RFC 1771) est qu´il s’appuie sur la couche TCP (port 179), ce qui permet de s’affranchir de la nécessité de supporter les fonctions de fragmentation, de retransmission, d’acquittement et de séquencement.
Deux routeurs BGP s´échangent des messages pour ouvrir et maintenir la connexion. Le premier flot de données est la table entière de routage. Ensuite, des mises à jours incrémentielles sont envoyées lorsque la table de routage change : BGP ne nécessite pas de mises à jour périodiques des tables de routage. Par contre, un routeur BGP doit retenir la totalité des tables de routage courantes de tous ses pairs durant le temps de la connexion. Des messages « keepalive » sont envoyés périodiquement pour maintenir la connexion.
BGP est un protocole de type » Path Vector « . Les routeurs s´échangent des informations du type :
| Adresse IP du réseau de destination | Adresse IP du prochain routeur (next hop) | Liste des AS traversés pour atteindre le réseau |
On constate qu´avec BGP, la granularité du routage est l´AS. Par défaut, lorsque plusieurs route existent entre deux AS, BGP choisit la route qui traverse le moins d’AS.
64.1.1.4. Quand utiliser BGP ?
Ce protocole est généralement utilisé par les fournisseurs d´accès à Internet, les administrateurs des points d´échange (IXP) et les administrateurs de systèmes autonomes qui souhaitent mettre en oeuvre leur propre politique de routage.
64.1.2. Place à la pratique
Voyons sur quelle topologie nous allons travailler :
Figure 64-4. Topologie
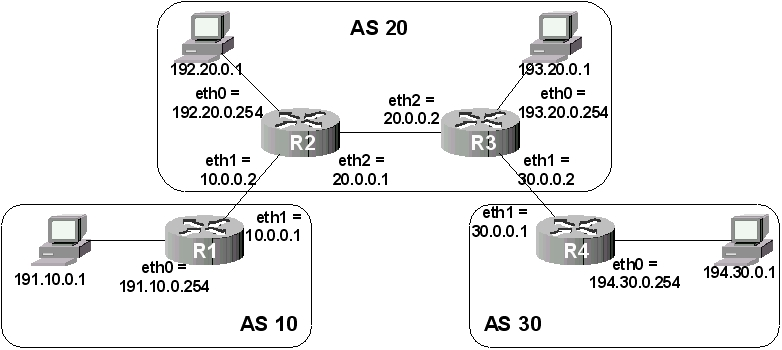
Nous avons trois systèmes autonomes numérotés 10, 20 et 30. Dans un souci de simplification, chaque système autonome a une topologie relativement simple. De ce fait, aucun IGP n’est utilisé. On constate que chaque routeur est un ASBR. L’AS 20 a une particularité car pour les AS 10 et 30, c’est un AS de transit. Nous reviendrons sur ce point dans la mise en oeuvre.
64.1.2.1. Tâches de configuration
Sur chaque routeur, il faudra réaliser les tâches suivantes :
0. préparer des fichiers /etc/zebra/zebra.conf et /etc/zebra/bgpd.conf rudimentaires, ne comportant que le nom de l’hôte et le mot de passe pour accéder à la console d’administration. Ensuite, dans le shell Linux, il faut lancer les démons zebra et bgpd dans l’ordre ;
- activer le processus de routage BGP en indiquant dans quel AS de situe le routeur (commande router bgp <numero_AS>) ;
- spécifier les routes à annoncer via BGP (commande network <préfixe_IP_du_réseau>/<masque>) ;
- établir une relation avec les routeurs voisins (commande neighbor <IP_du_voisin> remote-as <AS_du_voisin>).
64.1.2.2. Situation de départ
Vous devez créer des fichiers de configuration pour zebra (/etc/zebra/zebra.conf) et bgpd (/etc/zebra/bgpd.conf) rudimentaires sur chaque routeur. Par exemple, pour R1 :
– fichier zebra.conf :
hostname R1(ZEBRA)
password foo
– fichier bgpd.conf :
hostname R1(BGP) password foo
Vous devez ensuite démarrer (ou redémarrer), les deux démons zebra et bgpd sur chaque routeur. Enfin, sur vous entrez dans le terminal d’administration de bgpd via le port telnet 2605. Par exemple, sur R1 :
Linux# telnet localhost 2605 Hello, this is zebra (version 0.91a). Copyright 1996-2001 Kunihiro Ishiguro. User Access Verification Password: R1(BGP)> enable R1(BGP)#
Si vous avez envie de suivre précisément les échanges de messages entre routeurs, Zebra propose un mécanisme de débogage grâce à la commande debug. Supposons que nous voulions garder une trace de toutes les mises à jour d’informations de routage BGP émises et reçues par R1 :
R1(BGP)# conf t
R1(BGP)(config)# log file /var/log/zebra/bgpd.log
R1(BGP)(config)# debug bgp updates
Il faut s’assurer que le répertoire /var/log/zebra existe.
64.1.2.3. Activation du processus de routage
Dans le mode « config », nous allons activer le processus BGP en n’oubliant pas d’indiquer le numéro d’AS. Par exemple, sur R1 :
R1(BGP)(config)# router bgp 10
R1(BGP)(config-router)#
64.1.2.4. Spécification des routes à annoncer
Pour R1, le seul réseau que l’on souhaite annoncer via BGP aux autres routeurs est 191.10.0.0/24 car il contient des ordinateurs :
R1(BGP)(config-router)# network 191.10.0.0/24
Cette commande est à renouveler autant de fois qu’il y a de réseaux à annoncer. Dans notre exemple, nous avons choisi volontairement de ne pas annoncer le réseau 10.0.0.0/8 car celui-ci ne contient que des routeurs. Vous noterez au passage que cette commande n’a pas la même vocation que dans RIP ou OSPF.
64.1.2.5. Établissement d’une connexion avec les voisins
Il faut distinguer deux cas : mon voisin est-il dans un autre AS ou dans le même AS que moi ?
1. Cas où le voisin est dans un autre AS :
Je rappelle que « un voisin » est un routeur avec lequel on est immédiatement connecté. Il faut indiquer son adresse IP ainsi que son numéro d’AS. Dans le jargon BGP, une connexion entre deux routeurs BGP s’appelle peering. Sur R1, on saisit la commande :
R1(BGP)(config-router)# neighbor 10.0.0.2 remote-as 20
Cette commande est à renouveler autant de fois qu’il y a de routeurs BGP immédiatement connectés (et avec qui on souhaite échanger des informations de routage bien sûr).
2. Cas où le voisin est dans le même AS :
L’AS 20 est particulier car il véhicule des données qui ne lui sont pas destinées, en particulier les informations de routage en provenance et à destination des AS 10 et 30. En effet, pour que l’AS 30 connaisse l’existence du réseau 191.10.0.0/24, R2 doit récupérer cette information auprès de R1 puis la transmettre à R3 qui lui-même la transmettra à R4. R2 et R3 étant dans le même AS, un « sous-protocole » de BGP appelé iBGP est mis en oeuvre automatiquement par le routeur. Mais, celui-ci a la particularité de ne pas modifier les next hop lorsqu’il relaie des informations de routage. Ainsi, sans intervention, R4 apprendrait que le next hop pour joindre 192.10.0.0/24 est 10.0.0.1. Or, celui-ci n’est pas joignable depuis l’AS 30 (puisque nous ne faisons pas de network 10.0.0.0/8). Pour pallier à cette lacune, il existe la directive next-hop-self. Ainsi sur R2 et sur R3 nous réaliserons les configurations suivantes :
R2(BGP)(config-router)# neighbor 20.0.0.2 remote-as 20
R2(BGP)(config-router)# neighbor 20.0.0.2 next-hop-self
R3(BGP)(config-router)# neighbor 20.0.0.1 remote-as 20
R3(BGP)(config-router)# neighbor 20.0.0.1 next-hop-self
64.1.2.6. Affichage de la configuration
Affichons la configuration complète de R1 :
R1(BGP)(config-router)# end
R1(BGP)# show running-config
Current configuration:
!
hostname R1(BGP)
password foo
log file /var/log/zebra/bgpd.log
!
debug bgp updates
!
router bgp 10
network 191.10.0.0/24
neighbor 10.0.0.2 remote-as 20
!
line vty
!
end
Affichons la configuration complète de R2 :
R2(BGP)# show running-config
Current configuration:
!
hostname R2(BGP)
password foo
!
router bgp 20
network 192.20.0.0/24
neighbor 10.0.0.1 remote-as 10
neighbor 20.0.0.2 remote-as 20
neighbor 20.0.0.2 next-hop-self
!
line vty
!
end
J´espère que vous avez la même configuration. Si une commande est incorrecte, vous devez faire comme si vous vouliez la saisir à nouveau mais en la faisant précéder de no.
Pour enregistrer la configuration, je vous rappelle que l´on saisit :
R1(OSPF)# copy running-config startup-config
Par symétrie, vous devez être en mesure de configurer les autres routeurs du réseau.
64.1.2.7. Affichage de l’état des routeurs
64.1.2.7.1. Le débogage
Si vous avez activé le débogage, le fichier de log doit vous révéler des informations de ce style :
R1 # cat /var/log/bgpd.log
2003/05/24 03:29:03
BGP: BGPd 0.91a starting: vty@2605, bgp@179
2003/05/24 03:29:09
BGP: 10.0.0.2 send UPDATE 191.10.0.0/24 nexthop 10.0.0.1,
origin i, mp_nexthop ::, path
2003/05/24 03:29:09
BGP: 10.0.0.2 rcvd UPDATE w/ attr: nexthop 10.0.0.2,
origin i, path
202003/05/24 03:29:09
BGP: 10.0.0.2 rcvd 192.20.0.0/24…
On voit les annonces de routes émises (send UPDATE) et reçues (recv UPDATE) par R1. Si votre routage ne fonctionne pas, vous trouverez dans les journaux toutes les informations nécessaires à la résolution de problèmes.
64.1.2.7.2. La table de routage
Observons, par exemple, la table BGP calculée par R2 :
R2(BGP)# show ip bgp
BGP table version is 0, local router ID is 192.20.0.254
Status codes:
s suppressed, d damped, h history, * valid, > best, i – internal
Origin codes: i – IGP, e – EGP, ? – incomplete
| Network | Next Hop | Metric | LocPrf | Weight | Path | |
| *> | 191.10.0.0/24 | 10.0.0.1 | 0 | 10 i | ||
| *> | 192.20.0.0 | 0.0.0.0 | 32768 | i | ||
| *>i | 193.20.0.0 | 20.0.0.2 | 100 | 0 | i | |
| *>i | 194.30.0.0 | 20.0.0.2 | 100 | 0 | 30 i |
Total number of prefixes 4
La première colonne indique si la route est valide (*), si BGP considère que c’est la meilleure (>) et si elle provient d’un routeur interne (i pour internal) à l’AS. Les paramètres Metric, LocPrf (Local Preference) et Weight sont utilisés par BGP pour lire la meilleure route vers une destination. BGP applique l’algorithme (simplifié) suivant :
- BGP choisit la route avec le plus grand poids (weight). Par défaut, une route directement connectée se voit attribuer le poids 32768 ;
- Si une route n’est toujours pas choisie, BGP choisit celle avec la plus grande « préférence locale ». Par défaut, une route issue d’un routeur interne à l’AS se voit attribuer une préférence locale de 100 ;
- Si une route n’est toujours pas choisie, BGP choisit une route de type « internal » ;
- Si une route n’est toujours pas choisie, BGP retiens la route avec le chemin (As-Path) le plus court ;
- Si une route n’est toujours pas choisie, BGP choisit la route avec la métrique la plus faible.
La colonne Path indique la liste des systèmes autonomes à traverser avant d’atteindre le réseau. Le i indique ici que les routes sont de type IGP. En fait, BGP regroupe sous ce terme les routes statiques et découvertes par un protocole dynamique tel RIP ou OSPF.
Vous pouvez obtenir des informations détaillées sur une route particulière en tapant :
R2(BGP)# show ip bgp 194.30.0.0
BGP routing table entry for 194.30.0.0/24
Paths: (1 available, best #1, table Default-IP-Routing-Table) 30
20.0.0.2 from 20.0.0.2 (193.20.0.254)
Origin IGP, localpref 100, valid, internal, best
Last update: Sat May 24 03:39:16 2003
64.1.2.7.3. Informations sur les voisins
Zebra propose de nombreuses commandes permettant de connaître l’état des voisins. Parmi les plus intéressantes, on trouve :
| show ip bgp neighbors | Donne de nombreuses sur la connexion avec les voisins |
| show ip bgp summary | Synthétise les informations ci-dessus dans un tableau |
| show ip bgp <IP_voisin> routes | Routes découvertes à partir de ce voisin |
| show ip bgp <IP_voisin> advertised-routes | Routes annoncées à ce voisin |
64.1.3. Cohabitation entre BGP et les IGP
Zebra peut tout à fait annoncer des routes dynamiques via BGP (commande redistribute). Toutefois, cette fonctionnalité est à envisager avec beaucoup de prudence car toute changement de topologie sera visible à l’extérieur du système autonome.
64.1.4. Conclusion
CIDR
Route server
Route reflector
Cluster
Chapter 65. TP sur le routage statique avec Zebra
Le document décrit les principes du routage IP et l’architecture du routeur logiciel Zebra. Il propose une prise en main de Zebra et une mise en pratique du routage statique.
65.1. Introduction
Description et objectifs de la séquence. Une fois la séquence finie :
- vous saurez utiliser l’interface de configuration de Zebra ;
- saisir des routes statiques ;
- déboguer un routage incorrect.
65.1.1. Présentation des concepts importants
65.1.1.1. Routage, routeur, route
Imaginez que vous souhaitiez rendre visite à quelqu’un. Vous connaissez son adresse et, dans votre tête, vous avez la plupart des éléments importants pour vous diriger (sortir de la maison, prendre à droite, au feu tourner à gauche, marcher jusqu’au rond-point, tourner à droite, etc.).
Dans l’univers informatique, c’est sensiblement différent. Lorsqu’un ordinateur émet un paquet de données à destination d’un ordinateur situé dans un autre réseau, il ne sait pas quelle route il va prendre. La seule chose connue est l’adresse de destination du paquet ainsi que l’adresse d’une machine à proximité, située dans son réseau, et qui joue le rôle de la porte. On l’appelle la passerelle. Elle oriente le paquet vers le prochain carrefour. À ce carrefour, il y a un appareil qui oriente le paquet vers le prochain carrefour. À ce nouveau carrefour, il y a un nouvel appareil qui oriente le paquet vers le prochain carrefour. Et ainsi de suite jusqu’à arriver à la passerelle du réseau de destination qui remet le paquet dans le réseau.
L’appareil dont nous parlons s’appelle un routeur (la passerelle est également un routeur). Le routage consiste à faire circuler de routeur en routeur les paquets de données. L’administration d’un routeur consiste à configurer les routes d’un routeur. Une route est définie par un réseau de destination et l’adresse d’un routeur voisin, prochaine étape vers le réseau de destination. Une table de routage est une liste de routes utilisée par le routeur pour prendre des décisions quant à la direction à donner pour un paquet reçu sur l’une de ses interfaces. Le routage statique par opposition au routage dynamique, consiste à saisir manuellement les routes dans le routeur.
65.1.1.2. Prise de décision
Lorsqu’ un routeur reçoit un paquet sur l’une de ses interfaces. Il extrait l’adresse IP de destination. En appliquant le masque réseau, il détermine le préfixe réseau de cette adresse. Il recherche ce préfixe dans sa table de routage. Si le préfixe est trouvé, il émet le paquet sur l’interface réseau adapté. Si le préfixe n’est pas trouvé, deux cas peuvent se présenter. S’il connaît un routeur par défaut, il lui transmet le paquet, sinon il le détruit (sans en informer l’émetteur).
65.1.2. Architecture de Zebra
Zebra fonctionne sous Linux et BSD. C’est un routeur multi-protocole composé d’une suite de démons, un par protocole de routage dynamique plus un démon central (zebra) utilisé pour le routage statique. De plus, lorsque le routage dynamique est mis en oeuvre, il est chargé de synthétiser dans une table de routage unique, les informations rapportées par les autres démons.
Figure 65-1. Architecture de Zebra
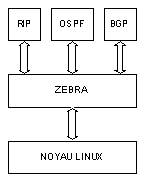
65.1.3. Topologie de travail
Figure 65-2. Topologie 1
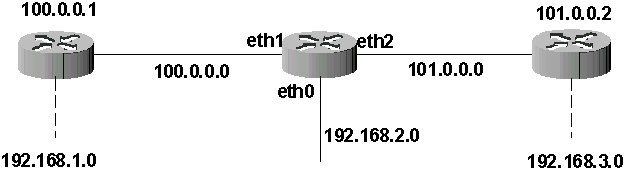
65.1.4. Mise en place
Nous avons besoin de trois routeurs disposant chacun de trois interfaces réseau. Sur une interface, un réseau local sera connecté. Les liens représentés par des éclairs correspondent à un réseau étendu. Ils sont simulés avec un câble croisé Ethernet. Les routeurs sont directement reliés de carte réseau à carte réseau par le câble croisé.
Vous devez installer trois ordinateurs avec trois cartes réseau dans chacun. Ensuite, installez le système d’exploitation puis Zebra. Pour les distributions RedHat et Mandrake, il est possible de télécharger les binaires sur http:\\rpmfind.net. Sinon, les sources sont accessibles sur www.zebra.org.
Les cartes réseau doivent être actives, mais ne configurez pas les adresses des cartes réseau, vous pourrez le faire directement à partir de Zebra. Si vous faites un ifconfig vous devez obtenir :
[root@linux root]# ifconfig
eth0 Lien encap:Ethernet HWaddr 00:50:56:40:C0:63
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 lg file transmission:100
RX bytes:0 (0.0 b) TX bytes:38159 (0.0 b)
Interruption:9 Adresse de base:0x1060
eth1 Lien encap:Ethernet HWaddr 00:50:56:40:C0:64
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 lg file transmission:100
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Interruption:11 Adresse de base:0x1080
eth2 Lien encap:Ethernet HWaddr 00:50:56:40:C0:65
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 lg file transmission:100
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Interruption:10 Adresse de base:0x10a0
lo Lien encap:Boucle locale
inet adr:127.0.0.1 Masque:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 lg file transmission:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Les trois cartes Ethernet activées mais sans adresse réseau.
65.1.5. Démarrage du démon zebra
Zebra ne peut pas démarrer sans un fichier de configuration minimal qu’il faudra saisir sur chaque routeur. Éditez un fichier /etc/zebra/zebra.conf :
Linux# vi /etc/zebra/zebra.conf
hostname Zebra
password foo
Ensuite, chargez le démon zebra :
Linux# zebra -d
Vous obtiendrez peut-être l’avertissement suivant :
2003/02/19 01:08:17 ZEBRA:
can’t create router advertisement socket:
Address family not supported by protocol
Zebra supporte IPv6, mais ce protocole n’est pas activé sur votre noyau. Ce n’est pas gênant pour la suite de l’activité.
65.1.6. Connexion au démon zebra
Zebra dispose d’une interface telnet pour chaque démon. Pour configurer le démon zebra, il faut se connecter sur le port 2601. Par exemple, sur Routeur3 :
[root@linux root]# telnet localhost 2601
Trying 127.0.0.1…
Connected to localhost.
Escape character is ‘^]’.
Hello, this is zebra (version 0.91a).
Copyright 1996-2001 Kunihiro Ishiguro.
User Access Verification
Password:
Zebra>
À l’invite Password:, saisissez le mot de passe que vous avez indiqué dans le fichier /etc/zebra/zebra.conf (aucun caractère n’apparaît lors de la saisie, c’est » normal « ). L’invite devient Zebra> (Zebra est le nom par défaut que vous changerez plus tard).
65.1.7. Prise en main de Zebra (principe)
Voyons les principaux éléments de l’environnement de Zebra.
65.1.7.1. L’invite
L’invite (prompt) a une importance capitale. À la suite du nom de l’appareil, on peut savoir dans quel » méandre » de l’arborescence des menus de configuration on se trouve.
Une invite terminée par un > indique que vous êtes dans le mode VIEW : c’est le mode activé lorsque l’on se connecte. Comme son nom l’indique, il s’agit d’un mode de visualisation de l’état du routeur. Par exemple :
Zebra>
Une invite terminée par un # indique que vous êtes dans le mode ENABLE : c’est le mode privilégié qui permet de modifier la configuration du routeur. On y accède à partir du mode VIEW en tapant la commande enable. Par exemple :
Zebra> enable
Zebra#
Ensuite, vous travaillerez essentiellement avec deux sous-modes :
– le mode « terminal de configuration ». On y accède à partir du mode ENABLE en tapant la commande configure terminal. Dans ce mode, on peut (entre autre) saisir des routes statiques. Par exemple :
Zebra# configure terminal
Zebra(config)#
– le mode « interface ». On y accède à partir du mode « terminal de configuration » en tapant la commande interface suivi du nom de l’interface réseau. Dans ce mode, on peut (entre autre) saisir l’adresse IP et le masque de l’interface. Par exemple :
Zebra(config)# interface eth0
Zebra(config-if)#
65.1.7.2. L’aide en ligne
Retenez les éléments suivants, ils vous seront d’un grand secours :
- – comme dans l’interpréteur de commandes Linux, le logiciel complète toutes les commandes lorsque vous appuyez sur la touche TAB (par exemple : shTAB devient show);
- – un simple appui sur ? indique toutes les commandes disponibles dans le mode dans lequel vous êtes;
- – enfin, la commande list donne la liste de toutes les commandes disponibles disponibles dans le mode dans lequel vous êtes et de leurs paramètres.
65.1.8. Prise en main de Zebra (mise en pratique)
Si vous n’êtes pas dans le mode view, tapez end puis disable :
Zebra(config-if)# end
Zebra# disable
Zebra>
65.1.8.1. Utilisation de l’aide en ligne
– listez l’ensemble des commandes disponibles à ce stade (tapez simplement un point d’interrogation) :
Zebra> ?
enable Turn on privileged mode command
exit Exit current mode and down to previous mode
help Description of the interactive help system
list Print command list
quit Exit current mode and down to previous mode
show Show running system information
terminal Set terminal line parameters
who Display who is on vty
– listez toutes les commandes disponibles à ce stade avec tous leurs paramètres :
Zebra> list
enable
exit
help
list
quit
show debugging zebra
show history
show interface [IFNAME]
show ip forwarding
show ip route
show ip route (bgp|connected|kernel|ospf|rip|static)
show ip route A.B.C.D
show ip route A.B.C.D/M
…
– listez tous les paramètres de la commande qui permet d’afficher la configuration (show ?) :
Zebra> show ?
debugging Zebra configuration
history Display the session command history
interface Interface status and configuration
ip IP information
ipv6 IPv6 information
memory Memory statistics
table default routing table to use for all clients
version Displays zebra version
65.1.8.2. Affichage de l’état du routeur
– Listez les interfaces disponibles sur votre routeur avec la commande show interface (n’oubliez pas qu’un simple shTAB intTAB suffit !) :
Zebra> sh int
Interface lo
index 1 metric 1 mtu 16436 >UP,LOOPBACK,RUNNING>
inet 127.0.0.1/8
input packets 152, bytes 9574, dropped 0, multicast packets 0
input errors 0, length 0, overrun 0, CRC 0, frame 0, fifo 0, missed 0
output packets 152, bytes 9574, dropped 0
output errors 0, aborted 0, carrier 0, fifo 0, heartbeat 0, window 0
collisions 0
Interface eth0
index 2 metric 1 mtu 1500 >UP,BROADCAST,RUNNING,MULTICAST>
HWaddr: 00:50:56:40:c0:63
input packets 0, bytes 0, dropped 0, multicast packets 0
input errors 0, length 0, overrun 0, CRC 0, frame 0, fifo 0, missed 0
output packets 0, bytes 0, dropped 0
output errors 0, aborted 0, carrier 0, fifo 0, heartbeat 0, window 0
collisions 0
Interface eth1
index 3 metric 1 mtu 1500 >UP,BROADCAST,RUNNING,MULTICAST>
HWaddr: 00:50:56:40:c0:64
input packets 0, bytes 0, dropped 0, multicast packets 0
input errors 0, length 0, overrun 0, CRC 0, frame 0, fifo 0, missed 0
output packets 0, bytes 0, dropped 0
output errors 0, aborted 0, carrier 0, fifo 0, heartbeat 0, window 0
collisions 0
Interface eth2
index 4 metric 1 mtu 1500 >UP,BROADCAST,RUNNING,MULTICAST>
HWaddr: 00:50:56:40:c0:65
input packets 0, bytes 0, dropped 0, multicast packets 0
input errors 0, length 0, overrun 0, CRC 0, frame 0, fifo 0, missed 0
output packets 0, bytes 0, dropped 0
output errors 0, aborted 0, carrier 0, fifo 0, heartbeat 0, window 0
collisions 0
Vous avez quatre interfaces (lo et trois Ethernet), aucune ne possède pour l’instant d’adresse IP.
– Visionnez le contenu de votre table de routage : shTAB ip roTAB :
Zebra> sh ip ro
Codes: K – kernel route, C – connected, S – static, R – RIP, O – OSPF,
B – BGP, > – selected route, * – FIB route
C>* 127.0.0.0/8 is directly connected, lo
Elle est vide ! sauf 127.0.0.0/8 qui correspond à l’adresse de bouclage logiciel. Cette table étant vide, le routeur n’a aucune idée de la façon d’acheminer les paquets de données vers tel ou tel réseau.
Le but de ce TP est de configurer correctement les interfaces et les tables de routage pour que l’ensemble des appareils des stations puissent s’atteindre au travers des trois routeurs.
65.1.8.3. Configuration générale du routeur
– Toute configuration nécessite de passer en mode privilégié :
Zebra> enable
Zebra#
Le # indique que vous êtes en mode privilégié.
– Listez les commandes disponibles :
Zebra# ?
configure Configuration from vty interface
copy Copy configuration
debug Debugging functions (see also ‘undebug’)
disable Turn off privileged mode command
end End current mode and change to enable mode.
exit Exit current mode and down to previous mode
help Description of the interactive help system
list Print command list
no Negate a command or set its defaults
quit Exit current mode and down to previous mode
show Show running system information
terminal Set terminal line parameters
who Display who is on vty
write Write running configuration to memory, network, or terminal
Les commandes importantes à ce stade sont : copy pour enregistrer la configuration et configure pour accéder au terminal de configuration des interfaces réseau et des routes.
65.1.8.4. Affichage de la configuration actuelle
La commande write term permet de consulter à tout moment la configuration actuelle du routeur :
Zebra# write term
Current configuration:
!
hostname Zebra
password foo
!
interface lo
!
interface eth0
!
interface eth1
!
interface eth2
!
line vty
!
end
65.1.8.5. Passage au mode « terminal de configuration »
Zebra# conf term
Zebra(config)#
Définition du nom du routeur. Cela se fait par la commande hostname. Attribuez à chaque routeur un nom significatif. Par exemple, pour le routeur 3 :
Zebra(config)# hostname Routeur3(Zebra)
Routeur3(Zebra)(config)#
Sécurisation du routeur. L’accès au routeur et à son mode de configuration doit être protégé.
- – Activez le chiffrement des mots de passe : Lorsque nous avons utilisé la commande write term, nous avons pu constater que le mot de passe n’était pas chiffré. Résolvons ce problème :
- Routeur3(Zebra)(config)# service password-encryption
- – Attribuez un mot de passe pour l’accès au mode VIEW du routeur (en remplacement de « foo »). Il doit commencer par une lettre ou un chiffre :
Routeur3(Zebra)(config)# password ******
- – Attribuez un mot de passe pour l’accès au mode ENABLE du routeur. Il doit commencer par une lettre ou un chiffre :
Routeur3(Zebra)(config)# enable password ******
65.1.8.6. Consultez la configuration
Routeur3(Zebra)(config)# w t
Current configuration:
!
hostname Routeur3(Zebra)
password 8 kZujW/HWOwF4o
enable password 8 1b5pHVyKjR.5w
service password-encryption
!
interface lo
!
interface eth0
!
interface eth1
!
interface eth2
!
line vty
!
end
Les mots de passe sont chiffrés maintenant.
65.1.8.7. Enregistrement de la configuration
Il faut revenir au mode enable. N’oubliez pas de sauvegarder régulièrement !
Routeur3(Zebra)(config)# end
Routeur3(Zebra)# copy running-config startup-config
Configuration saved to /etc/zebra/zebra.conf
Configuration des interfaces réseau
Il faut attribuer une adresse IP et un masque à chaque carte réseau. Pour cela, il faut se placer dans le mode « configuration d’interface » puis utiliser une commande ip address. Enfin, il faut activer l’interface avec une commande no shutdown. Par exemple, pour l’interface eth0 du routeur 3 :
Routeur3(Zebra)# conf t
Routeur3(Zebra)(config)# int eth0
Routeur3(Zebra)(config-if)# ip addr 192.168.3.254/8
Routeur3(Zebra)(config-if)# no shut
– Faites la même manipulation, en adaptant, pour les autres interfaces de ce routeur.
Consultez la configuration :
Routeur3(Zebra)(config)# wr t
Current configuration:
!
hostname Routeur3(Zebra)
password 8 kZujW/HWOwF4o
enable password 8 1b5pHVyKjR.5w
service password-encryption
!
interface lo
!
interface eth0
ip address 192.168.3.254/24
!
interface eth1
ip address 12.0.0.2/8
!
interface eth2
!
line vty
!
end
L’interface eth2 n’a pas d’adresse pour l’instant.
Faites ces configurations sur les trois routeurs.
65.1.8.8. Configuration des routes
Allez dans le shell Linux du routeur3 et listez sa table de routage :
[root@linux root]# route
Table de routage IP du noyau
Destination GW Genmask Indic Metric Ref Use Iface
192.168.3.0 * 255.255.255.0 U 0 0 0 eth0
12.0.0.0 * 255.0.0.0 U 0 0 0 eth1
127.0.0.0 * 255.0.0.0 U 0 0 0 lo
Cet appareil connaît les adresses des réseaux directement connecté. Ainsi, Routeur3 peut communiquer avec l’interface de Routeur2 situé dans le même réseau :
[root@linux root]# ping 12.0.0.1 -c 2
PING 12.0.0.1 (12.0.0.1) from 12.0.0.2 : 56(84) bytes of data.
Warning: time of day goes back, taking countermeasures.
64 bytes from 12.0.0.1: icmp_seq=0 ttl=255 time=4.352 msec
64 bytes from 12.0.0.1: icmp_seq=1 ttl=255 time=1.819 msec
— 12.0.0.1 ping statistics —
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/mdev = 1.819/3.085/4.352/1.267 ms
Tous les appareils peuvent pinger leurs voisins immédiats, mais pas au-delà. Par exemple, Routeur3 ne peut pas atteindre Routeur1 :
[root@linux root]# ping 11.0.0.1
connect: Network is unreachable
Normal, puisque le réseau 11.0.0.0 ne figure pas dans sa table de routage. Le routage statique va consister à intégrer manuellement les routes dans la table de routage du routeur. Ouvrez un session telnet avec zebra puis allez dans le mode « configuration de terminal ».
La saisie des routes se fait avec la commande ip route. Son format général est :
ip route <adresse_reseau_destination> <adresse_ip_prochain_routeur>
Par exemple, sur Routeur3 pour atteindre Routeur1, il faudra indiquer 11.0.0.0/8 en réseau de destination et l’adresse IP de l’interface de Routeur2 qui est située du côté de Routeur3 :
Routeur3(Zebra)(config)# ip route 11.0.0.0/8 12.0.0.1
Tentons à nouveau un ping dans le shell Linux :
Routeur3(Zebra)(config)# end
Routeur3(Zebra)# quit
Connection closed by foreign host.
[root@linux root]# ping 11.0.0.1
PING 11.0.0.1 (11.0.0.1) from 12.0.0.2 : 56(84) bytes of data.
CTRL-C
— 11.0.0.1 ping statistics —
13 packets transmitted, 0 packets received, 100% packet loss
Il faut interrompre la commande car elle restait bloquée. Cela ne marche donc pas. Pourquoi ?
Pour comprendre, nous allons utiliser la commande Linux tcpdump qui affiche tous les paquets passant par une interface. Sur Routeur3 :
[root@linux root]# tcpdump -i eth1
tcpdump: listening on eth1
03:44:45.507835 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:44:46.507835 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:44:47.507835 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
Le routeur émet des paquets mais on constate qu’il n’y a pas de retour. Le problème peut venir de Routeur2 ou de Routeur1. Suivons la chaîne et connectons-nous dans le shell de Routeur2. Utilisons tcpdump sur l’interface du côté de Routeur3 :
[root@linux root]# tcpdump -i eth2
tcpdump: listening on eth2
03:52:20.017855 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:52:21.017855 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:52:22.027855 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
Les paquets sont bien reçus. Faisons la même manipulation, toujours sur Routeur2 mais sur l’interface du côté de Routeur1 :
[root@linux root]# tcpdump -i eth1
tcpdump: listening on eth1
03:52:46.027855 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:52:47.017855 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:52:48.017855 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
Les paquets sont bien transmis d’une interface à l’autre. Routeur2 fait son travail. Passons sur Routeur1, faisons un tcpdump sur l’interface côté Routeur 2 :
[root@linux root]# tcpdump -i eth2
tcpdump: listening on eth2
03:53:53.224868 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:53:54.224868 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:53:55.234868 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
Les paquets sont bien reçus sur Routeur1. Mais il n’est pas capable d’y répondre. D’où vient le problème alors ? Il n’y a qu’une solution. Il vient de la table de routage. Routeur1 ne sait pas comment répondre à Routeur3 car il n’a aucune idée de l’endroit où il se trouve puisqu’il n’est pas directement relié à lui. Connectons-nous au démon zebra sur Routeur1 puis visionnons sa table de routage :
Routeur1(Zebra)> sh ip ro
Codes: K – kernel route, C – connected, S – static, R – RIP, O – OSPF,
B – BGP, > – selected route, * – FIB route
C>* 11.0.0.0/8 is directly connected, eth2
C>* 127.0.0.0/8 is directly connected, lo
C>* 192.168.1.0/24 is directly connected, eth0
Elle ne contient aucune entrée pour 12.0.0.0/8, le réseau auquel est connecté Routeur3. Réparons cette erreur en informant Routeur1 sur la façon d’atteindre 12.0.0.0/8. Il faut passer par son voisin Routeur2 dont l’adresse est 11.0.0.2. Sur le routeur (en mode « terminal de configuration »), il faut saisir :
Routeur1(Zebra)(config)# ip route 12.0.0.0/8 11.0.0.2
Affichons à nouveau la table de routage :
Routeur1(Zebra)(config)# end
Routeur1(Zebra)# sh ip ro
Codes: K – kernel route, C – connected, S – static, R – RIP, O – OSPF,
B – BGP, > – selected route, * – FIB route
C>* 11.0.0.0/8 is directly connected, eth2
S>* 12.0.0.0/8 [1/0] via 11.0.0.2, eth2
C>* 127.0.0.0/8 is directly connected, lo
C>* 192.168.1.0/24 is directly connected, eth0
La route apparaît. Elle est notée S pour Statique.
Revenons dans le shell Linux de Routeur1. La commande tcpdump nous montre que maintenant, Routeur sait répondre à Routeur3 :
[root@linux root]# tcpdump -i eth2
tcpdump: listening on eth2
03:59:51.904868 12.0.0.2 >> 11.0.0.1: icmp: echo request (DF)
03:59:51.904868 11.0.0.1 > 12.0.0.2: icmp: echo reply
03:59:52.864868 12.0.0.2 > 11.0.0.1: icmp: echo request (DF)
03:59:52.864868 11.0.0.1 > 12.0.0.2: icmp: echo reply
Si l’on revient sur Routeur3, le ping fonctionne désormais sans problème :
[root@linux root]# ping 11.0.0.1 -c 2
PING 11.0.0.1 (11.0.0.1) from 12.0.0.2 : 56(84) bytes of data.
Warning: time of day goes back, taking countermeasures.
64 bytes from 11.0.0.1: icmp_seq=0 ttl=254 time=8.090 msec
64 bytes from 11.0.0.1: icmp_seq=1 ttl=254 time=3.986 msec
— 11.0.0.1 ping statistics —
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/mdev = 3.986/6.038/8.090/2.052 ms
65.1.8.9. Résumé
1. Le routage est une chaîne : les paquets sont transmis au routeur voisin, qui transmet au routeur voisin, etc.
2. Il faut penser à configurer tous les routeurs pour l’aller ET le retour des paquets.
65.1.8.10. Configuration des routeurs
Maintenant que vous savez tout, saisissez sur chaque routeur l’ensemble minimal des routes qu’il a besoin de connaître. Le cahier des charges est le suivant : les stations de chaque réseau ont besoin de communiquer avec les stations de tous les autres réseaux. Les stations n’ont pas besoin de communiquer avec les routeurs.
D’abord, commencez par détruire les routes statiques que nous venons de saisir pour les besoins de la démonstration. Par exemple, sur Routeur3 pour détruire la route 11.0.0.0/8 :
Routeur3(Zebra)> en
Password:
Routeur3(Zebra)# conf t
Routeur3(Zebra)(config)# no ip route 11.0.0.0/8 12.0.0.1
Routeur3(Zebra)(config)#
Dernier point : n’oubliez pas de configurer la passerelle par défaut sur les stations, sans quoi elles ne sauraient pas comment faire sortir leurs paquets de LAN. La passerelle par défaut de chaque LAN est le routeur le plus proche. Par exemple sur une station du premier réseau local (192.168.1.0/24), en supposant que celle-ci est sous Windows :
Figure 65-3. Topologie 1
65.1.8.11. Solution
Ci-dessous, vous trouverez la configuration complète des trois routeurs. Vos routes statiques doivent être strictement identiques à celles indiquées. Ci ce n’est pas le cas, vous n’avez pas complètement compris le principe du routage, relisez la partie introductive de ce document.
Pour Routeur1 :
Routeur1(Zebra)# sh run
Current configuration:
!
hostname Routeur1(Zebra)
password 8 .A2UkN/mYwExA
enable password 8 J7XQRuHNCKhOA
service password-encryption
!
interface lo
!
interface eth0
ip address 192.168.1.254/24
!
interface eth1
!
interface eth2
ip address 11.0.0.1/8
!
ip route 192.168.2.0/24 11.0.0.2
ip route 192.168.3.0/24 11.0.0.2
!
line vty
!
end
Pour Routeur2 :
Routeur2(Zebra)# sh run
Current configuration:
!
hostname Routeur2(Zebra)
password 8 wcw4qNEU1QPy.
enable password 8 fqdY3GaicS4XQ
service password-encryption
!
interface lo
!
interface eth0
ip address 192.168.2.254/24
!
interface eth1
ip address 11.0.0.2/8
!
interface eth2
ip address 12.0.0.1/8
!
ip route 192.168.1.0/24 11.0.0.1
ip route 192.168.3.0/24 12.0.0.2
!
line vty
!
end
Pour Routeur3 :
Routeur3(Zebra)# sh ru
Current configuration:
!
hostname Routeur3(Zebra)
password 8 kZujW/HWOwF4o
enable password 8 1b5pHVyKjR.5w
service password-encryption
!
interface lo
!
interface eth0
ip address 192.168.3.254/24
!
interface eth1
ip address 12.0.0.2/8
!
interface eth2
!
ip route 192.168.1.0/24 12.0.0.1
ip route 192.168.2.0/24 12.0.0.1
!
line vty
!
end
65.1.9. Problèmes rencontrés
Q – Je ne sais pas retirer les adresses IP déjà configurées sous Linux
R – Éditez le contenu des fichiers /etc/sysconfig/network-scripts/ifcfg-ethx (avec x = numéro de la carte) et supprimez les lignes contenant l’adresse et le masque. Ensuite, redémarrez.
Q – Je n’arrive pas ouvrir de session Telnet.
R – Soit vous n’indiquez pas le numéro de port (2601) après l’adresse IP, soit le démon zebra n’est pas lancé. Faites un ps -ax pour vérifier. S’il n’apparaît pas, faites un zebra -d
Q – J’ai oublié un mot de passe.
R – Bravo. Éditez le fichier /etc/zebra/zebra.conf et retirez les lignes password et service password-encryption
Q – J’ai saisi une mauvaise commande et je ne sais pas la supprimer :
R – Vous devez faire exactement comme si vous vouliez saisir à nouveau cette commande mais vous faites précéder le tout de no. Exemple : J’ai saisi une mauvaise adresse (99.0.0.9/8) sur l’interface eth0 de mon routeur :
Routeur1(Zebra)> enable
Password:
Routeur1(Zebra)# conf t
Routeur1(Zebra)(config)# int eth0
Routeur1(Zebra)(config-if)# no ip address 99.0.0.9/8
Routeur3(Zebra)(config-if)#
Chapter 66. Multi-router looking glass
Utilisation de l’interface d’accès php aux services de zebra avec MRLG.
66.1. Présentation
MRLG était écrit en Perl. Il est désormais siponible en php. (http://pilot.org.ua/mrlg/). C’est une interface d’accès qui permet d’afficher les routes et interfaces des roueturs reconnus par zebra.
Figure 66-1. MRLG – Multi-Router Looking Glass
Chapter 67. Annexe sur le langage de commande de Zebra
Utilisation du mode commande de Zebra.
67.1. Annexe sur le langage de commande de Zebra
Zebra est configuré (/etc/zebra/zebra.conf)
[mlx@mr]$ telnet localhost 2601
Trying 127.0.0.1…
Connected to localhost.
Escape character is ‘^]’.
Hello, this is zebra (version 0.94).
Copyright 1996-2002 Kunihiro Ishiguro.
User Access Verification
Password: // Entrer le mot de passe
mr> enable // On passe en mode privilégié
mr# disable // On revient en mode normal
mr> exit // Quitter
Connection closed by foreign host.
# Obtenir les commandes de bases
mr>?
enable Turn on privileged mode command
exit Exit current mode and down to previous mode
help Description of the interactive help system
list Print command list
quit Exit current mode and down to previous mode
show Show running system information
terminal Set terminal line parameters
who Display who is on vty
# Obtenir les commandes en mode privilégié
mr> enable
mr# ?
configure Configuration from vty interface
copy Copy configuration
debug Debugging functions (see also ‘undebug’)
disable Turn off privileged mode command
end End current mode and change to enable mode.
exit Exit current mode and down to previous mode
help Description of the interactive help system
list Print command list
no Negate a command or set its defaults
quit Exit current mode and down to previous mode
show Show running system information
terminal Set terminal line parameters
who Display who is on vty
write Write running configuration to memory, network, or terminal
# list donne la liste de toutes les commandes
mr# list
configure terminal
copy running-config startup-config
debug zebra events
debug zebra kernel
debug zebra packet
debug zebra packet (recv|send)
debug zebra packet (recv|send) detail
disable
end
exit
help
list
no debug zebra events
no debug zebra kernel
no debug zebra packet
quit
–More–
# Une commande suivi de « ? » indique la liste
# des paramètres attendus
mr# configure ?
terminal Configuration terminal
mr# configure
Les commandes « show running-config » et « show startup-config » permettent respectivement d’avoir la configuration active du routeur et les commandes de configuration de démarrage lors du démarrage du routeur.
« show interface » donne les indications sur les interfaces.
« show ip route » donne les information sur la table de routage.
« show history » donne la listes des commandes saisies.
« configure terminal » permt de passer en mode configuration.
Chapter 68. Concepts généraux sur le routage
Éléments retrospectifs de la séquence sur le routage statique et dynamique.
68.1. Présentation
La notion d’adressage ip (réseaux, sous-réseaux, sur-réseaux, hôtes, du rôle et des fonctions de la couche réseau, des protocoles ip, arp, icmp, ont déjà été largement abordées dans d’autres séquences. Elles ne seront pas revues dans ce document.
La notion de routage statique a également également vu dans d’autres séquences. Les principes ne seront pas repris. On retiendra juste qu’avec cette technique, les protocoles de routage n’ont pas le choix de leurs routes. Cette technique convient bien aux petits réseaux ne subissant pas de d’évolutions ou de changements fréquents. Il ne s’agit pas vraiment d’un protocole de routage au sens ou cela peut être pris pour le routage dynamique.
Les protocoles de routage dynamiques répondent à d’autres besoins. Dès que les topologies deviennent complexes. Ce document va présenter un peu du jargon de ce domaine.
68.2. Jargon réseau sur le routage
Cette partie décrit les termes et éléments utilisés sur les réseaux mettant en oeuvre des protocoles de routages dynamiques.
68.2.1. Notion de système autonome (SA)
Un Système Autonome (AS) est un ensemble cohérent de réseaux et de routeurs sous la responsabilité d’une autorité administrative. Les AS ont des architectures de routages indépendantes les unes des autres.
Un AS ont des numéros codés sur 16 bits. Ces numéros attribués par le Network Information Center sont uniques.
Figure 68-1. Système Autonomes
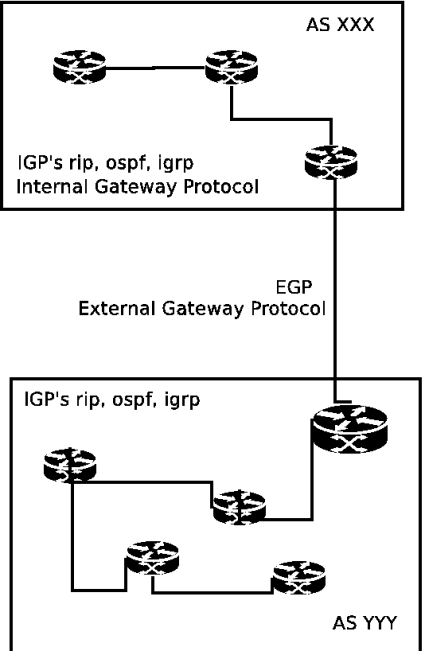
Le schémas représente 2 AS. Les AS sont reliés par des routeurs que l’on nomme « exteriors gateway ».
Les IG n’échangent que des informations entre elles. Certaines IG doivent cependant échanger avec des « exteriors gateway » pour prendre connaissance des réseaux étrangers.
Dans les protocoles de routages ds IGP’s, on trouve principalement :
- RIP – Protocole de routage à vecteur de distance.
- IGRP – Protocole de routage à vecteur de distance de Cisco.
- OSPF – Protocole de routage à état de liens. (Open Shortest Path First)
- EIGRP – Protocole de routage hybride symétrique.
EGP (Exterior Gateway Protocol), BGP (Border Gateway Protocol) sont des protocoles de routage inter AS.
68.2.2. Choix d’une route et métrique
Pour déterminer une route à utiloiser, un routeur va se baser sur « métrique ». Cette valeur est déterminér par un ou plusieurs critères.
Le protocole RIP ne prend en compte que le nombre de sauts (hop) pour déterminer la chemin le plus court. (sa métrique).
D’autres protocoles peuvent prendre en compte d’autres paramètres comme la charge, le nombre de sauts, la bande passante, le délai, la charge…
68.3. Les protocoles de routages IGP’s
On considère deux grandes familles de protocoles utilisant des algorithmes.
68.3.1. Les algorithmes Vector-Distance
Les protocoles comme RIP qui utilisent cete algorithme, utilisent le nombre de sauts (hop) comme métrique pour sélectionner un chemin.
Le routage à vecteur de distance détermine la direction (le vecteur) et la distance par rapport à une liaison du réseau.
Un routeur diffuse régulièrement (toutes les 30 secondes ) à ses voisins les routes qu’il connaît. Une route est composée d’une adresse destination, d’une adresse de passerelle et d’une métrique indiquant le nombre de sauts nécessaires pour atteindre la destination. Une passerelle qui reçoit ces informations compare les routes reçues avec ses propres routes connues et met à jour sa propre table de routage.
Le problème vient souvent du fait la taille des tables de routage est proportionnelle au nombre de routeurs du domaine et que cela génère très vite une charge importante sur le réseau.
68.3.2. Algorithme Link State (État de Liens)
L’algorithme Link State, est basé sur la technique « Shortest Path First » (SPF). Les routeurs maintiennent une carte complète du réseau et calculent les meilleurs chemins localement en utilisant cette topologie. Ils ne communiquent pas, comme dans l’algorithme « Vector Distance » la liste de toutes les destinations connues. Les routeurs valident l’état des liens qui les relient et communiquent cet état aux routeurs voisins.
Cette technique recrée un état du réseau. Elle utilise en premier le plus court chemin d’abord mais peut utiliser d’autres paramètres. Les routeurs mettent à jour leur carte et recalculent localement pour chaque lien modifié, la nouvelle route selon l’algorithme de Dijkstra shortest path algorithm qui détermine le plus court chemin pour toutes les destinations à partir d’une même source.Elle est utilisée par le protocole OSPF par exemple.
68.3.3. Les techniques hybrides
Ce sont des protocoles qui utilisent les deux techniques de routages, comme le protocole EIGRP de Cisco.
68.4. Les protocoles de routages extérieurs EGP
Ces protocoles sont utilisés échanger les informations entre les systèmes autonomes. Ils permettent l’échange d’information entre paserelles d’AS différents et le test de la disponibilité des liaisons.
Chapter 69. Remerciements et licence
69.1. Copyright
Cette documentation est soumise aux termes de la Licence de Documentation Libre GNU (GNU Free Documentation License).
Les programmes sont soumis aux termes de la Licence Générale Publique GNU (GNU General Public Licence).