Le JDK fourni un certains nombres d’API intégrés au JDK pour des fonctionnalités avancées.
Plusieurs chapitres dans cette partie détaillent les API pour utiliser les fonctionnalités suivantes :
- les collections : propose une revue des classes fournies par le JDK pour gérer des ensembles d’objets
- les flux : explore les classes utiles à la mise en oeuvre d’un des mécanismes de base pour échanger des données
- la sérialisation : présente un mécanisme qui permet de rendre persistant un objet
- l’intéraction avec le réseau :
- l’accès aux bases de données : indique comment utiliser JDBC pour accéder
- l’appel de méthodes distantes : étudie la mise en oeuvre de la technologie RMI pour permettre l’appel de méthodes distantes.
- l’internationalisation : traite d’une façon pratique de la possibilité d’internationnaliser une application
- les composants java beans : examine comment développer et utiliser des composants réutilisables
- logging : indique comment mettre en oeuvre deux API pour la gestion des logs : Log4J du projet open source jakarta et l’API logging du JDK 1.4
1. Les collections
Les collections sont des objets qui permettent de gérer des ensembles d’objets. Ces ensembles de données peuvent être définis avec plusieurs caractéristiques : la possibilité de gérer des doublons, de gérer un ordre de tri, etc. …
Chaque objet contenu dans une collection est appelé un élément.
1.1. Présentation du framework collection
Dans la version 1 du J.D.K., il n’existe qu’un nombre restreint de classes pour gérer des ensembles de données :
- Vector
- Stack
- Hashtable
- Bitset
L’interface Enumeration permet de parcourir le contenu de ces objets.
Pour combler le manque d’objets adaptés, la version 2 du J.D.K. apporte un framework complet pour gérer les collections. Cette bibliothèque contient un ensemble de classes et interfaces. Elle fourni également un certain nombre de classes abstraites qui implémentent partiellement certaines interfaces.
Les interfaces à utiliser par des objets qui gèrent des collections sont :
- Collection : interface qui est implementée par la plupart des objets qui gèrent des collections
- Map : interface qui définie des méthodes pour des objets qui gèrent des collections sous la forme clé/valeur
- Set : interface pour des objets qui n’autorisent pas la gestion des doublons dans l’ensemble
- List : interface pour des objets qui autorisent la gestion des doublons et un accès direct à un élément
- SortedSet : interface qui étend l’interface Set et permet d’ordonner l’ensemble
- SortedMap : interface qui étend l’interface Map et permet d’ordonner l’ensemble
Certaines méthodes définies dans ces interfaces sont dites optionnelles : leur définition est donc obligatoire mais si l’opération n’est pas supportées alors la méthode doit lever une exception particulière. Ceci permet de réduire le nombre d’interfaces et de répondre au maximum de cas.
Le framework propose plusieurs objets qui implémentent ces interfaces et qui peuvent être directement utilisés :
- HashSet : HashTable qui implémente l’interface Set
- TreeSet : arbre qui implémente l’interface SortedSet
- ArrayList : tableau dynamique qui implémente l’interface List
- LinkedList : liste doublement chaînée (parcours de la liste dans les deux sens) qui implémente l’interface List
- HashMap : HashTable qui implémente l’interface Map
- TreeMap : arbre qui implémente l’interface SortedMap
Le framework définit aussi des interfaces pour faciliter le parcours des collections et leur tri :
- Iterator : interface pour le parcours des collections
- ListIterator : interface pour le parcours des listes dans les deux sens et modifier les éléments lors de ce parcours
- Comparable : interface pour définir un ordre de tri naturel pour un objet
- Comparator : interface pour définir un ordre de tri quelconque
Deux classes existantes dans les précédentes versions du JDK ont été modifiées pour implémenter certaines interfaces du framework :
- Vector : tableau à taille variable qui implémente maintenant l’interface List
- HashTable : table de hashage qui implémente maintenant l’interface Map
Le framework propose la classe Collections qui contient de nombreuses méthodes statiques pour réaliser certaines opérations sur une collection. Plusieurs méthodes unmodifiableXXX() (ou XXX représente une interface d’une collection) permettent de rendre une collection non modifiable. Plusieurs méthodes synchronizedXXX() permettent d’obtenir une version synchronisée d’une collection pouvant ainsi être manipulée de façon sûre par plusieurs threads. Enfin plusieurs méthodes permettent de réaliser des traitements sur la collection : tri et duplication d’une liste, recherche du plus petit et du plus grand élément, etc. …
Le framework fourni plusieurs classes abstraites qui proposent une implémentation partielle d’une interface pour faciliter la création d’un collection personnalisée : AbstractCollection, AbstractList, AbstractMap, AbstractSequentialList et AbstractSet.
Les objets du framework stockent toujours des références sur les objets contenus dans la collection et non les objets eux mêmes. Ce sont obligatoirement des objets qui doivent être ajoutés dans une collection. Il n’est pas possible de stocker directement des types primitifs : il faut obligatoirement encapsuler ces données dans des wrappers.
Toutes les classes de gestion de collection du framework ne sont pas synchronisées : elles ne prennent pas en charge les traitements multi−threads. Le framework propose des méthodes pour obtenir des objets de gestion de collections qui prennent en charge cette fonctionnalité. Les classes Vector et Hashtable était synchronisée mais l’utilisation d’une collection ne se fait généralement pas de ce contexte. Pour réduire les temps de traitement dans la plupart des cas, elles ne sont pas synchronisées par défaut.
Lors de l’utilisation de ces classes, il est préférable de stocker la référence de ces objets sous la forme d’une interface qu’ils implémentent plutôt que sous leur forme objet. Ceci rend le code plus facile à modifier si le type de l’objet qui gèrent la collection doit être changé.
1.2. Les interfaces des collections
Le framework de java 2 définit 6 interfaces en relation directe avec les collections qui sont regroupées dans deux arborescences :
Le JDK ne fourni pas de classes qui implémentent directement l’interface Collection.
Le tableau ci dessous présente les différentes classes qui implémentent les interfaces de bases Set, List et Map :
Set List Map
|
Hashtable |
HashSet |
HashMap |
|
ArrayList, Vector |
|||
|
Arbre |
TreeSet |
TreeMap |
|
|
Liste chaînée |
LinkedList |
||
|
Classes du JDK 1.1 |
Stack |
Hashtable |
|
Pour gérer toutes les situations de façon simple, certaines méthodes peuvent être définies dans une interface comme «optionnelles ». Pour celles ci, les classes qui implémentent une telle interface, ne sont pas obligées d’implémenter du code qui réalise un traitement mais simplement lève une exception si cette fonctionnalité n’est pas supportée.
Le nombre d’interfaces est ainsi grandement réduit.
Cette exception est du type UnsupportedOperationException. Pour éviter de protéger tous les appels de méthodes d’un objet gérant les collections dans un bloc try−catch, cette exception hérite de la classe RuntimeException.
Toutes les classes fournies par le J.D.K. qui implémentent une des interfaces héritant de Collection implémentent toutes les opérations optionnelles.
1.2.1. L’interface Collection
Cette interface définit des méthodes pour des objets qui gèrent des éléments d’une façon assez générale. Elle est la super interface de plusieurs interfaces du framework.
Plusieurs classes qui gèrent une collection implémentent une interface qui hérite de l’interface Collection. Cette interface est une des deux racines de l’arborescence des collections.
Cette interface définit plusieurs méthodes :
|
Méthode |
Rôle |
|
|
boolean add(Object) |
ajoute l’élément fourni en paramètre à la collection. La valeur de retour indique si |
|
|
la collection a été mise à jour |
||
|
boolean addAll(Collection) |
ajoute à la collection tous les éléments de la collection fournie en paramètre |
|
|
void clear() |
supprime tous les éléments de la collection |
|
|
boolean contains(Object) |
indique si la collection contient au moins un élément identique à celui fourni en |
|
|
paramètre |
||
|
boolean containsAll(Collection) |
indique si tous les éléments de la collection fournie en paramètre sont contenus |
|
|
dans la collection |
||
|
boolean isEmpty() |
indique si la collection est vide |
|
|
Iterator iterator() |
renvoie un objet qui permet de parcourir l’ensemble des éléments de la collection |
|
|
boolean remove(Object) |
supprime l’élément fourni en paramètre de la collection. La valeur de retour |
|
|
indique si la collection a été mise à jour |
||
|
boolean removeAll(Collection) |
supprime tous les éléments de la collection qui sont contenus dans la collection |
|
|
fournie en paramètre |
||
|
int size() |
renvoie le nombre d’éléments contenu dans la collection |
|
|
Object[] toArray() |
renvoie d’un tableau d’objets qui contient tous les éléments de la collection |
|
Cette interface représente un minimum commun pour les objets qui gèrent des collections : ajout d’éléments, suppression d’éléments, vérifier la présence d’un objet dans la collection, parcours de la collection et quelques opérations diverses sur la totalité de la collection.
Ce tronc commun permet entre autre de définir pour chaque objet gérant une collection, un constructeur pour cette objet demandant un objet de type Collection en paramètre. La collection est ainsi initialisée avec les éléments contenus dans la collection fournie en paramètre.
Attention : il ne faut pas ajouter dans une collection une référence à la collection elle−même.
1.2.2. L’interface Iterator
Cette interface définie des méthodes pour des objets capables de parcourir les données d’une collection.
La définition de cette nouvelle interface par rapport à l’interface Enumeration a été justifiée par l’ajout de la fonctionnalité de suppression et la réduction des noms de méthodes.
|
Méthode |
Rôle |
|
boolean hasNext() |
indique si il reste au moins à parcourir dans la collection |
|
Object next() |
renvoie la prochain élément dans la collection |
|
void remove() |
supprime le dernier élément parcouru |
La méthode hasNext() est équivalente à la méthode hasMoreElements() de l’interface Enumeration.
La méthode next() est équivalente à la méthode nextElement() de l’interface Enumeration.
La méthode next() lève une exception de type NoSuchElementException si elle est appelée alors que la fin du parcours des éléments est atteinte. Pour éviter la lever de cette exception, il suffit d’appeler la méthode hasNext() et de conditionner avec le résultat l’appel à la méthode next().
|
Exemple ( code java 1.2 ) : |
|
Iterator iterator = collection.Iterator(); while (iterator.hasNext()) { System.out.println(“objet = ”+iterator.next()); } |
La méthode remove() permet de supprimer l’élément renvoyé par le dernier appel à la méthode next(). Il est ainsi impossible d’appeler la méthode remove() sans un appel correspondant à next() : on ne peut pas appeler deux fois de suite la méthode remove().
|
Exemple ( code java 1.2 ) : suppression du premier élément |
|
Iterator iterator = collection.Iterator(); if (iterator.hasNext()) { iterator.next(); itérator.remove(); } |
Si aucun appel à la méthode next() ne correspond à celui de la méthode remove(), une exception de type IllegalStateException est levée
1.3. Les listes
Une liste est une collection ordonnée d’éléments qui autorise d’avoir des doublons. Etant ordonnée, un élément d’une liste peut être accédé à partir de son index.
1.3.1. L’interface List
Cette interface étend l’interface Collection.
Les collections qui implémentent cette interface autorisent les doublons dans les éléments de la liste. Ils autorisent aussi l’insertion d’éléments null.
L’interface List propose plusieurs méthodes pour un accès à partir d’un index aux éléments de la liste. La gestion de cet index commence à zéro.
Pour les listes, une interface particulière est définie pour assurer le parcours dans les deux sens de la liste et assurer des mises à jour : l’interface ListIterator
|
Méthode |
Rôle |
|
|
ListIterator listIterator() |
renvoie un objet capable de parcourir la liste |
|
|
Object set (int, Object) |
remplace l’élément contenu à la position précisée par l’objet fourni en paramètre |
|
|
void add(int, Object) |
ajouter l’élément fourni en paramètre à la position précisée |
|
|
Object get(int) |
renvoie l’élément à la position précisée |
|
|
int indexOf(Object) |
renvoie l’index du premier élément fourni en paramètre dans la liste ou –1 si |
|
|
l’élément n’est pas dans la liste |
||
|
ListIterator listIterator() |
renvoie un objet pour parcourir la liste et la mettre à jour |
|
|
renvoie un extrait de la liste contenant les éléments entre les deux index fournis (le |
||
|
List subList(int,int) |
premier index est inclus et le second est exclus). Les éléments contenus dans la |
|
|
liste de retour sont des références sur la liste originale. Des mises à jour de ces |
||
|
éléments impactent la liste originale. |
||
|
int lastIndexOf(Object) |
renvoie l’index du dernier élément fourni en paramètre dans la liste ou –1 si |
|
|
l’élément n’est pas dans la liste |
||
|
Object set(int, Object) |
remplace l’élément à la position indiquée avec l’objet fourni |
|
Le framework propose de classes qui implémentent l’interface List : LinkedList et ArrayList.
1.3.2. Les listes chaînées : la classe LinkedList
Cette classe hérite de la classe AbstractSequentialList et implémente donc l’interface List.
Elle représente une liste doublement chaînée.
Cette classe possède un constructeur sans paramètre et un qui demande une collection. Dans ce dernier cas, la liste sera initialisée avec les éléments de la collection fournie en paramètre.
|
Exemple ( code java 1.2 ) : |
|
LinkedList listeChainee = new LinkedList(); Iterator iterator = listeChainee.Iterator(); listeChainee.add(“element 1”); listeChainee.add(“element 2”); listeChainee.add(“element 3”); while (iterator.hasNext()) { System.out.println(“objet = ”+iterator.next()); } |
Une liste chaînée gère une collection de façon ordonnée : l’ajout d’un élément peut se faire à la fin de la collection ou après n’importe quel élément. Dans ce cas, l’ajout est lié à la position courante lors d’un parcours.
Pour répondre à ce besoin, l’interface qui permet le parcours de la collection est une sous classe de l’interface Iterator :
l’interface ListIterator.
Comme les iterator sont utilisés pour faire des mises à jour dans la liste, une exception de type CurrentModificationException levé si un iterator parcours la liste alors qu’un autre fait des mises à jour (ajout ou suppression d’un élément dans la liste).
Pour gérer facilement cette situation, il est préférable si l’on sait qu’il y ait des mises à jour à faire de n’avoir qu’un seul iterator qui soit utilisé.
Plusieurs méthodes pour ajouter, supprimer ou obtenir le premier ou le dernier élément de la liste permettent d’utiliser cette classe pour gérer une pile :
|
Méthode |
Rôle |
|
void addFirst(Object) |
insère l’objet en début de la liste |
|
void addLast(Object) |
insère l’objet en fin de la liste |
|
Object getFirst() |
renvoie le premier élément de la liste |
|
Object getLast() |
renvoie le dernier élément de la liste |
|
Object removeFirst() |
supprime le premier élément de la liste et renvoie le premier élément |
|
Object removeLast() |
supprime le dernier élément de la liste et renvoie le premier élément |
De par les caractéristiques d’une liste chaînée, il n’existe pas de moyen d’obtenir un élément de la liste directement. Pourtant, la méthode contains() permet de savoir si un élément est contenu dans la liste et la méthode get() permet d’obtenir l’élément à la position fournie en paramètre. Il ne faut toutefois pas oublier que ces méthodes parcours la liste jusqu’à obtention du résultat, ce qui peut être particulièrement gourmand en terme de temps de réponse surtout si la méthode get() est appelée dans une boucle.
Pour cette raison, il ne faut surtout pas utiliser la méthode get() pour parcourir la liste.
La méthode toString() renvoie une chaîne qui contient tous les éléments de la liste.
1.3.3. L’interface ListIterator
Cette interface définie des méthodes pour parcourir la liste dans les deux sens et effectuer des mises à jour qui agissent par rapport à l’élément courant dans le parcours.
En plus des méthodes définies dans l’interface Iterator dont elle hérite, elle définie les méthodes suivantes :
|
Roles |
||
|
void add(Object) |
ajoute un élément dans la liste en tenant de la position dans le parcours |
|
|
boolean hasPrevious() |
indique si il reste au moins un élément à parcourir dans la liste dans son sens |
|
|
inverse |
||
|
Object previous() |
renvoi l’élément précédent dans la liste |
|
|
void set(Object) |
remplace l’élément courante par celui fourni en paramètre |
|
La méthode add() de cette interface ne retourne pas un booléen indiquant que l’ajout à réussi.
Pour ajouter un élément en début de liste, il suffit d’appeler la méthode add() sans avoir appeler une seule fois la méthode next(). Pour ajouter un élément en fin de la liste, il suffit d’appeler la méthode next() autant de fois que nécessaire pour atteindre la fin de la liste et appeler la méthode add(). Plusieurs appels à la méthode add() successifs, ajoute les éléments à la position courante dans l’ordre d’appel de la méthode add().
1.3.4. Les tableaux redimensionnables : la classe ArrayList
Cette classe représente un tableau d’objets dont la taille est dynamique.
Elle hérite de la classe AbstractList donc elle implémente l’interface List.
Le fonctionnement de cette classe est identique à celui de la classe Vector.
La différence avec la classe Vector est que cette dernière est multi thread (toutes ces méthodes sont synchronisées). Pour une utilisation dans un thread unique, la synchronisation des méthodes est inutile et coûteuse. Il est alors préférable d’utiliser un objet de la classe ArrayList.
Elle définit plusieurs méthodes dont les principales sont :
|
Méthode |
Rôle |
|
|
boolean add(Object) |
ajoute un élément à la fin du tableau |
|
|
boolean addAll(Collection) |
ajoute tous les éléments de la collection fournie en paramètre à la fin du tableau |
|
|
boolean addAll(int, Collection) |
ajoute tous les éléments de la collection fournie en paramètre dans la collection à |
|
|
partir de la position précisée |
||
|
void clear() |
supprime tous les éléments du tableau |
|
|
void ensureCapacity(int) |
permet d’augmenter la capacité du tableau pour s’assurer qu’il puisse contenir le |
|
|
nombre d’éléments passé en paramètre |
||
|
Object get(index) |
renvoie l’élément du tableau dont la position est précisée |
|
|
int indexOf(Object) |
renvoie la position de la première occurrence de l’élément fourni en paramètre |
|
|
boolean isEmpty() |
indique si le tableau est vide |
|
|
int lastIndexOf(Object) |
renvoie la position de la dernière occurrence de l’élément fourni en paramètre |
|
|
Object remove(int) |
supprime dans le tableau l’élément fourni en paramètre |
|
|
void removeRange(int,int) |
supprime tous les éléments du tableau de la première position fourni incluse |
|
|
jusqu’à la dernière position fournie exclue |
||
|
Object set(int, Object) |
remplace l’élément à la position indiquée par celui fourni en paramètre |
|
int size() |
renvoie le nombre d’élément du tableau |
|
void trimToSize() |
ajuste la capacité du tableau sur sa taille actuelle |
Chaque objet de type ArrayList gère une capacité qui est le nombre total d’élément qu’il est possible d’insérer avant d’agrandir le tableau. Cette capacité a donc une relation avec le nombre d’élément contenu dans la collection. Lors d’ajout dans la collection, cette capacité et le nombre d’élément de la collection détermine si le tableau doit être agrandi. Si un nombre important d’élément doit être ajouté, il est possible de forcer l’agrandissement de cette capacité avec la méthode ensureCapacity(). Son usage évite une perte de temps liée au recalcul de la taille de la collection. Un constructeur permet de préciser la capacité initiale.
1.4. Les ensembles
Un ensemble (Set) est une collection qui n’autorise pas l’insertion de doublons.
1.4.1. L’interface Set
Cette classe définit les méthodes d’une collection qui n’accepte pas de doublons dans ces éléments. Elle hérite de l’interface Collection mais elle ne définie pas de nouvelle méthode.
Pour déterminer si un élément est déjà inséré dans la collection, la méthode equals() est utilisée.
Le framework propose deux classes qui implémentent l’interface Set : TreeSet et HashSet
Le choix entre ces deux objets est liés à la nécessité de trié les éléments :
- les éléments d’un objet HashSet ne sont pas triés : l’insertion d’un nouvel élément est rapide
- les éléments d’un objet TreeSet sont triés : l’insertion d’un nouvel éléments est plus long
1.4.2. L’interface SortedSet
Cette interface définie une collection de type ensemble triée. Elle hérite de l’interface Set.
Le tri de l’ensemble peut être assuré par deux façons :
- les éléments contenus dans l’ensemble implémentent l’interface Comparable pour définir leur ordre naturel
- il faut fournir au constructeur de l’ensemble un objet Comparator qui définit l’ordre de tri à utiliser
Elle définie plusieurs méthodes pour tirer parti de cette ordre :
|
Méthode |
Rôle |
|
|
Comparator comparator() |
renvoie l’objet qui permet de trier l’ensemble |
|
|
Object first() |
renvoie le premier élément de l’ensemble |
|
|
SortedSet headSet(Object) |
renvoie un sous ensemble contenant tous les éléments inférieurs à celui fourni en |
|
|
paramètre |
||
|
Object last() |
renvoie le dernier élément de l’ensemble |
|
renvoie un sous ensemble contenant les éléments compris entre le premier
SortedSet subSet(Object, Object)
paramètre inclus et le second exclus
renvoie un sous ensemble contenant tous les éléments supérieurs ou égaux à celui
SortedSet tailSet(Object)
fourni en paramètre
1.4.3. La classe HashSet
Cette classe est un ensemble sans ordre de tri particulier.
Les éléments sont stockés dans une table de hashage : cette table possède une capacité.
|
Exemple ( code java 1.2 ) : |
|
import java.util.*; public class TestHashSet { public static void main(String args[]) { Set set = new HashSet(); set.add(« CCCCC »); set.add(« BBBBB »); set.add(« DDDDD »); set.add(« BBBBB »); set.add(« AAAAA »); Iterator iterator = set.iterator(); while (iterator.hasNext()) {System.out.println(iterator.next());} } } |
|
Résultat : |
|
AAAAA DDDDD BBBBB CCCCC |
1.4.4. La classe TreeSet
Cette classe est un arbre qui représente un ensemble trié d’éléments.
Cette classe permet d’insérer des éléments dans n’importe quel ordre et de restituer ces éléments dans un ordre précis lors de son parcours.
L’implémentation de cette classe insère un nouvel élément dans l’arbre à la position correspondant à celle déterminée par l’ordre de tri. L’insertion d’un nouvel élément dans un objet de la classe TreeSet est donc plus lent mais le tri est directement effectué.
L’ordre utilisé est celui indiqué par les objets insérés si ils implémentent l’interface Comparable pour un ordre de tri naturel ou fournir un objet de type Comparator au constructeur de l’objet TreeSet pour définir l’ordre de tri.
|
Exemple ( code java 1.2 ) : |
|
import java.util.*; public class TestTreeSet { public static void main(String args[]) { Set set = new TreeSet(); set.add(« CCCCC »); set.add(« BBBBB »); set.add(« DDDDD »); set.add(« BBBBB »); set.add(« AAAAA »); Iterator iterator = set.iterator(); while (iterator.hasNext()) {System.out.println(iterator.next());} } } |
|
Résultat : |
|
AAAAA BBBBB CCCCC DDDDD |
1.5. Les collections gérées sous la forme clé/valeur
Ce type de collection gère les éléments avec deux entités : une clé et une valeur associée. La clé doit être unique donc il ne peut y avoir de doublons. En revanche la même valeur peut être associées à plusieurs clés différentes.
Avant l’apparition du framework collections, la classe dédiée à cette gestion était la classe Hashtable.
1.5.1. L’interface Map
Cette interface est une des deux racines de l’arborescence des collections. Les collections qui implémentent cette interface ne peuvent contenir de doublons. Chaque clé est associée à une valeur et une seule.
Elle définie plusieurs méthodes pour agir sur la collection :
|
Méthode |
Rôle |
|
void clear() |
supprime tous les éléments de la collection |
|
boolean containsKey(Object) |
indique si la clé est contenue dans la collection |
|
boolean containsValue(Object) |
indique si la valeur est contenue dans la collection |
|
Set entrySet() |
renvoie un ensemble contenant les valeurs de la collection |
|
Object get(Object) |
renvoie la valeur associée à la clé fournie en paramètre |
|
boolean isEmpty() |
indique si la collection est vide |
|
Set keySet() |
renvoie un ensemble contenant les clés de la collection |
|
Object put(Object, Object) |
insère la clé et sa valeur associée fournies en paramètres |
|
void putAll(Map) |
insère toutes les clés/valeurs de l’objet fourni en paramètre |
|
Collection values() |
renvoie une collection qui contient toutes les éléments des éléments |
|
Object remove(Object) |
supprime l’élément dont la clé est fournie en paramètre |
|
int size() |
renvoie le nombre d’éléments de la collection |
La méthode entrySet() permet d’obtenir un ensemble contenant toutes les clés.
La méthode values() permet d’obtenir une collection contenant toutes les valeurs. La valeur de retour est une Collection et non un ensemble car il peut y avoir des doublons (plusieurs clés peuvent être associées à la même valeur).
Le J.D.K. 1.2 propose deux nouvelles classes qui implémentent cette interface :
- HashMap qui stocke les éléments dans une table de hashage
- TreeMap qui stocke les éléments dans un arbre
La classe HashTable a été mise à jour pour implémenter aussi cette interface.
1.5.2. L’interface SortedMap
Cette interface définie une collection de type Map triée sur la clé. Elle hérite de l’interface Map.
Le tri peut être assuré par deux façons :
- les clés contenues dans la collection implémentent l’interface Comparable pour définir leur ordre naturel
- il faut fournir au constructeur de la collection un objet Comparator qui définit l’ordre de tri à utiliser
Elle définit plusieurs méthodes pour tirer parti de cette ordre :
|
Méthode |
Rôle |
|
|
Comparator comparator() |
renvoie l’objet qui permet de trier la collection |
|
|
Object first() |
renvoie le premier élément de la collection |
|
|
SortedSet headMap(Object) |
renvoie une sous collection contenant tous les éléments inférieurs à celui fourni en |
|
|
paramètre |
||
|
Object last() |
renvoie le dernier élément de la collection |
|
|
SortedMap subMap(Object, |
renvoie une sous collection contenant les éléments compris entre le premier |
|
|
Object) |
paramètre inclus et le second exclus |
|
|
SortedMap tailMap(Object) |
renvoie une sous collection contenant tous les éléments supérieurs ou égaux à celui |
|
|
fourni en paramètre |
||
1.5.3. La classe Hashtable
1.5.4. La classe TreeMap
1.5.5. La classe HashMap
1.6. Le tri des collections
L’ordre de tri est défini grace à deux interfaces :
- Comparable
- Comparator
1.6.1. L’interface Comparable
Tous les objets qui doivent définir un ordre naturel utilisé par le tri d’une collection avec cet ordre doivent implémenter cette interface.
Cette interface ne définit qu’une seule méthode : int compareTo(Object).
Cette méthode doit renvoyer :
- une valeur entière négative si l’objet courant est inférieur à l’objet fourni
- une valeur entière positive si l’objet courant est supérieur à l’objet fourni
- une valeur nulle si l’objet courant est égal à l’objet fourni
Les classes wrappers, String et Date implémentent cette interface.
1.6.2. L’interface Comparator
Cette interface représente un ordre de tri quelconque. Elle est utile pour permettre le tri d’objet qui n’implémente pas l’interface Comparable ou pour définir un ordre de tri différent de celui défini avec Comparable ( l’interface Comparable représente un ordre naturel : il ne peut y en avoir qu’un)
Cette interface ne définit qu’une seule méthode : int compare(Object, Object).
Cette méthode compare les deux objets fournis en paramètre et renvoie :
- une valeur entière négative si le premier objet est inférieur au second
- une valeur entière positive si le premier objet est supérieur au second
- une valeur nulle si les deux objets sont égaux
1.7. Les algorithmes
La classe Collections propose plusieurs méthodes statiques qui effectuer des opérations sur des collections. Ces traitements sont polymorphiques car ils demandent en paramètre un objet qui implémente une interface et retourne une collection.
Méthode Rôle
|
copie tous les éléments de la seconde liste dans la première |
||
|
Enumaration |
renvoie un objet Enumeration pour parcourir la collection |
|
|
enumeration(Collection) |
||
|
Object max(Collection) |
renvoie le plus grand élément de la collection selon l’ordre naturel des éléments |
|
|
Object max(Collection, |
renvoie le plus grand élément de la collection selon l’ordre naturel précisé par |
|
|
Comparator) |
l’objet Comparator |
|
|
Object min(Collection) |
renvoie le plus petit élément de la collection selon l’ordre naturel des éléments |
|
|
Object min(Collection, |
renvoie le plus petit élément de la collection selon l’ordre précisé par l’objet |
|
|
Comparator) |
Comparator |
|
|
void reverse(List) |
inverse l’ordre de la liste fournie en paramètre |
|
|
void shuffle(List) |
réordonne tous les éléments de la liste de façon aléatoire |
|
|
void sort(List) |
trie la liste dans un ordre ascendant selon l’ordre naturel des éléments |
|
|
void sort(List, Comparator) |
trie la liste dans un ordre ascendant selon l’ordre précisé par l’objet Comparator |
|
Si la méthode sort(List) est utilisée, il faut obligatoirement que les éléments inclus dans la liste implémentent tous l’interface Comparable sinon une exception de type ClassCastException est levée.
Cette classe propose aussi plusieurs méthodes pour obtenir une version multi−thread ou non modifiable des principales interfaces des collections : Collection, List, Map, Set, SortedMap, SortedSet
- XXX synchronizedXXX(XXX) pour obtenir une version multi−thread des objets implémentant l’interface XXX
- XXX unmodifiableXXX(XXX) pour obtenir une version non modifiable des objets implémentant l’interface
XXX
L’utilisation d’une méthode synchronizedXXX() renvoie une instance de l’objet qui supporte la synchronisation pour les opérations d’ajout et de suppression d’éléments. Pour le parcours de la collection avec un objet Iterator, il est nécessaire de synchroniser le bloc de code utilisé pour le parcours. Il est important d’inclure aussi dans ce bloc l’appel à la méthode pour obtenir l’objet de type Iterator utilisé pour le parcours.
1.8. Les exceptions du framework
L’exception de type UnsupportedOperationException est levée lorsque qu’une opération optionnelle n’est pas supportée par l’objet qui gère la collection.
L’exception ConcurrentModificationException est levée lors du parcours d’une collection avec un objet Iterator et que cette collection subi une modification structurelle.
2. Les flux
Un programme a souvent besoin d’échanger des informations pour recevoir des données d’une source ou pour envoyer des données vers un destinataire.
La source et la destination de ces échanges peuvent être de nature multiple : un fichier, une socket réseau, un autre programme, etc …
De la même façon, la nature des données échangées peut être diverse : du texte, des images, du son, etc …
2.1. Présentation des flux
Les flux (stream en anglais) permettent d’encapsuler ces processus d’envoie et de réception de données. Les flux traitent toujours les données de façon séquentielle.
En java, les flux peuvent être divisés en plusieurs catégories :
- les flux d’entrée (input stream) et les flux de sortie (output stream)
- les flux de traitement de caractères et les flux de traitement d’octets
Java définit des flux pour lire ou écrire des données mais aussi des classes qui permettent de faire des traitements sur les données du flux. Ces classes doivent être associées à un flux de lecture ou d’écriture et sont considérées comme des filtres. Par exemple, il existe des filtres qui permettent de mettre les données traitées dans un tampon (buffer) pour les traiter par lots.
Toutes ces classes sont regroupées dans le package java.io.
2.2. Les classes de gestion des flux
Ce qui déroute dans l’utilisation de ces classes, c’est leur nombre et la difficulté de choisir celle qui convient le mieux en fonction des besoins. Pour faciliter ce choix, il faut comprendre la dénomination des classes : cela permet de sélectionner la ou les classes adaptées aux traitements à réaliser.
Le nom des classes se décompose en un préfixe et un suffixe. Il y a quatre suffixes possibles en fonction du type de flux (flux d’octets ou de caractères) et du sens du flux (entrée ou sortie).
|
Flux d’octets |
Flux de caractères |
|
|
Flux d’entrée |
InputStream |
Reader |
|
Flux de sortie |
OutputStream |
Writer |
Il exite donc quatre hiérarchies de classes qui encapsulent des types de flux particuliers. Ces classes peuvent être séparées en deux séries de deux catégories différentes : les classes de lecture et d’écriture et les classes permettant la lecture de
- les sous classes de Reader sont des types de flux en lecture sur des ensembles de caractères
- les sous classes de Writer sont des types de flux en écriture sur des ensembles de caractères
- les sous classes de InputStream sont des types de flux en lecture sur des ensembles d’octets
- les sous classes de OutputStream sont des types de flux en écriture sur des ensembles d’octets
Pour le préfixe, il faut distinguer les flux et les filtres. Pour les flux, le préfixe contient la source ou la destination selon le sens du flux.
|
Préfixe du flux |
source ou destination du flux |
|
ByteArray |
tableau d’octets en mémoire |
|
CharArray |
tableau de caractères en mémoire |
|
File |
fichier |
|
Object |
objet |
|
Pipe |
pipeline entre deux threads |
|
String |
chaîne de caractères |
Pour les filtres, le préfixe contient le type de traitement qu’il effectue. Les filtres n’existent pas obligatoirement pour des flux en entrée et en sortie.
|
Type de traitement |
Préfixe de la classe |
En entrée |
En sortie |
|
|
Mise en tampon |
Buffered |
Oui |
Oui |
|
|
Concaténation de flux |
Sequence |
Oui pour flux |
Non |
|
|
d’octets |
||||
|
Conversion de données |
Data |
Oui pour flux |
Oui pour flux |
|
|
d’octets |
d’octets |
|||
|
Numérotation des lignes |
LineNumber |
Oui pour les flux de |
Non |
|
|
caractères |
||||
|
Lecture avec remise dans le flux des données |
PushBack |
Oui |
Non |
|
|
Impression |
|
Non |
Oui |
|
|
Sérialisation |
Object |
Oui pour flux |
Oui pour flux |
|
|
d’octets |
d’octets |
|||
|
Conversion octets/caractères |
InputStream / |
Oui pour flux |
Oui pour flux |
|
|
OutputStream |
d’octets |
d’octets |
||
- Buffered : ce type de filtre permet de mettre les données du flux dans un tampon. Il peut être utilisé en entrée et en sortie
- Sequence : ce filtre permet de fusionner plusieurs flux.
- Data : ce type de flux permet de traiter les octets sous forme de type de données
- LineNumber : ce filtre permet de numéroter les lignes contenues dans le flux
- PushBack : ce filtre permet de remettre des données lues dans le flux
- Print : ce filtre permet de réaliser des impressions formatées
- Object : ce filtre est utilisé par la sérialisation
- InputStream / OuputStream : ce filtre permet de convertir des octets en caractères
La package java.io définit ainsi plusieurs classes :
|
Flux en lecture |
Flux en sortie |
||
|
BufferedReader |
BufferedWriter |
||
|
CharArrayReader |
CharArrayWriter |
||
|
FileReader |
FileWriter |
||
|
InputStreamReader |
OutputStreamWriter |
||
|
Flux de caractères |
|||
|
LineNumberReader |
|||
|
PipedReader |
PipedWriter |
||
|
PushbackReader |
|||
|
StringReader |
StringWriter |
||
|
BufferedInputStream |
BufferedOutputStream |
||
|
ByteArrayInputStream |
ByteArrayOutputStream |
||
|
DataInputStream |
DataOuputStream |
||
|
FileInputStream |
FileOutputStream |
||
|
Flux d’octets |
ObjectInputStream |
ObjetOutputStream |
|
|
PipedInputStream |
PipedOutputStream |
||
|
PrintStream |
|||
|
PushbackInputStream |
|||
|
SequenceInputStream |
|||
2.3. Les flux de caractères
Ils transportent des données sous forme de caractères : java les gèrent avec le format Unicode qui code les caractères sur 2 octets.
Ce type de flux a été ajouté à partir du JDK 1.1.
Les classes qui gèrent les flux de caractères héritent d’une des deux classes abstraites Reader ou Writer. Il existe de nombreuses sous classes pour traiter les flux de caractères.
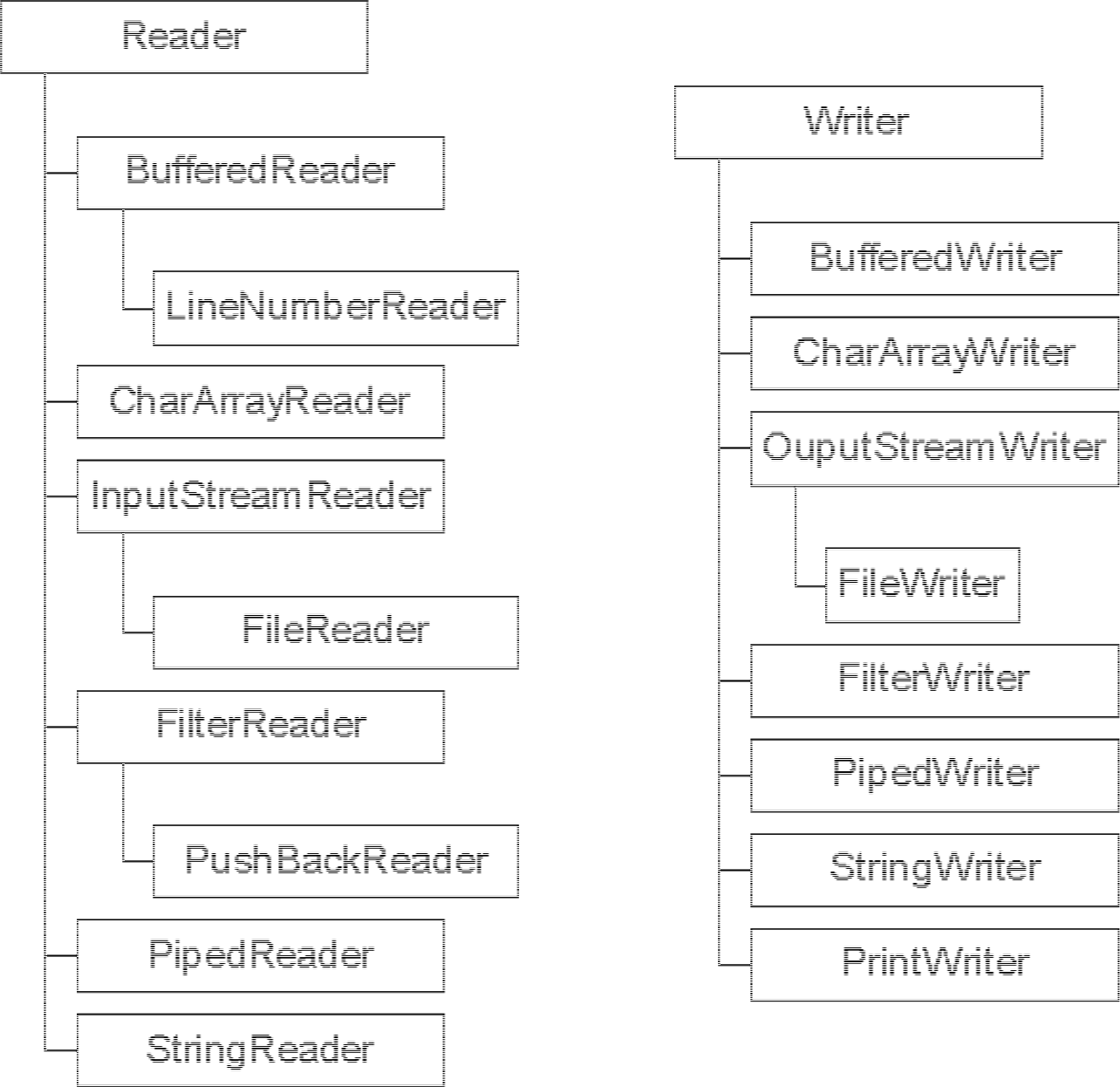
2.3.1. La classe Reader
C’est une classe abstaite qui est la classe mère de toutes les classes qui gèrent des flux de caractères en lecture.
Cette classe définit plusieurs méthodes :
|
Méthodes |
Rôles |
|
boolean markSupported() |
indique si le flux supporte la possibilité de marquer des positions |
|
boolean ready() |
indique si le flux est prêt à être lu |
|
close() |
ferme le flux et libère les ressources qui lui étaient associées |
|
int read() |
renvoie le caractère lu ou −1 si la fin du flux est atteinte. |
|
int read(char[]) |
lire plusieurs caractères et les mettre dans un tableau de caractères |
|
int read(char[], int, int) |
lire plusieurs caractères. Elle attend en paramètre : un tableau de caractères |
|
qui contiendra les caractères lus, l’indice du premier éléments du tableau qui |
|
|
recevra le premier caractère et le nombre de caractères à lire. Elle renvoie le |
||
|
nombre de caractères lus ou −1 si aucun caractère n’a été lu. La tableau de |
||
|
caractères contient les caractères lus. |
||
|
long skip(long) |
saute autant de caractères dans le flux que la valeur fournie en paramètre. |
|
|
Elle renvoie le nombre de caractères sautés. |
||
|
mark() |
permet de marquer une position dans le flux |
|
|
reset() |
retourne dans le flux à la dernière position marquée |
|
2.3.2. La classe Writer
C’est une classe abstaite qui est la classe mère de toutes les classes qui gèrent des flux de caractères en écriture.
Cette classe définit plusieurs méthodes :
|
Méthodes |
Rôles |
|
close() |
ferme le flux et libère les ressources qui lui étaient associées |
|
write(int) |
écrire le caractère en paramètre dans le flux. |
|
write(char[]) |
écrire le tableau de caractères en paramètre dans le flux. |
|
écrire plusieurs caractères. Elle attend en paramètres : un tableau de |
|
|
write(char[], int, int) |
caractères, l’indice du premier caractère dans le tableau à écrire et le |
|
nombre de caractères à écrire. |
|
|
write(String) |
écrire la chaîne de caractères en paramètre dans le flux |
|
écrire une portion d’une chaîne de caractères. Elle attend en paramètre : |
|
|
write(String, int, int) |
une chaîne de caractères, l’indice du premier caractère dans la chaîne à |
|
écrire et le nombre de caractères à écrire. |
|
2.3.3. Les flux de caractères avec un fichier
Les classes FileReader et FileWriter permettent de gérer des flux de caractères avec des fichiers.
2.3.3.1. Les flux de caractères en lecture sur un fichier
Il faut instancier un objet de la classe FileReader. Cette classe hérite de la classe InputStreamReader et possède plusieurs constructeurs qui peuvent tous lever une exception de type FileNotFoundException:
|
Constructeur |
Rôle |
|
FileInputReader(String) |
Créer un flux en lecture vers le fichier dont le nom est précisé en paramètre. |
|
FileInputReader(File) |
Idem mais le fichier est précisé avec un objet de type File |
Il existe plusieurs méthodes de la classe FileReader qui permettent de lire un ou plusieurs caractères dans le flux. Toutes ces méthodes sont héritées de la classe Reader et peuvent toutes lever l’exception IOException.
Une fois les traitements sur le flux terminés, il faut libérer les ressources qui lui sont allouées en utilisant la méthode close().
2.3.3.2. Les flux de caractères en écriture sur un fichier
Il faut instancier un objet de la classe FileWriter qui hérite de la classe OuputStreamWriter. Cette classe possède plusieurs constructeurs :
Constructeur Rôle
Si le nom du fichier précisé n’existe pas alors le fichier sera créé. Si il existe
FileWriter(String)
et qu’il contient des données celles ci seront écrasées.
|
FileWriter(File) |
Idem mais le fichier est précisé avec un objet de la classe File. |
Le booléen permet de préciser si les données seront ajoutées au fichier
FileWriter(String, boolean)
(valeur true) ou écraseront les données existantes (valeur false)
Il existe plusieurs méthodes de la classe FileWriter héritées de la classe Writer qui permettent d’écrire un ou plusieurs caractères dans le flux.
Une fois les traitements sur le flux terminés, il faut libérer les ressources qui lui sont allouées en utilisant la méthode close().
2.3.4. Les flux de caractères tamponnés avec un fichier.
Pour améliorer les performances des flux sur un fichier, la mise en tampon des données lues ou écrites permet de traiter un ensemble de caractères représentant une ligne plutôt que de traiter les données caractères par caractères. Le nombre d’opérations est ainsi réduit.
Les classes BufferedReader et BufferedWriter permettent de gérer des flux de caractères tamponnés avec des fichiers.
2.3.4.1. Les flux de caractères tamponnés en lecture avec un fichier
Il faut instancier un objet de la classe BufferedReader. Cette classe possède plusieurs constructeurs qui peuvent tous lever une exception de type FileNotFoundException:
|
BufferedReader(Reader) |
le paramètre fourni doit correspondre au flux à lire. |
l’entier en paramètre permet de préciser la taille du buffer. Il doit être positif
BufferedReader(Reader, int)
sinon une exception de type IllegalArgumentException est levée.
Il existe plusieurs méthodes de la classe BufferedReader héritées de la classe Reader qui permettent de lire un ou plusieurs caractères dans le flux. Toutes ces méthodes peuvent lever une exception de type IOException. Elle définit une méthode supplémentaire pour la lecture :
|
Méthode |
Rôle |
lire une ligne de caractères dans le flux. Une ligne est une suite de
String readLine() caractères qui se termine par un retour chariot ‘\r’ ou un saut de ligne ‘\n’ ou les deux.
La classe BufferedReader possède plusieurs méthodes pour gérer le flux héritées de la classe Reader.
Une fois les traitements sur le flux terminés, il faut libérer les ressources qui lui sont allouées en utilisant la méthode close().
2.3.4.2. Les flux de caractères tamponnés en écriture avec un fichier
Il faut instancier un objet de la classe BufferedWriter. Cette classe possède plusieurs constructeurs :
Constructeur Rôle
le paramètre fourni doit correspondre au flux dans lequel les données sont
BufferedWriter(Writer)
écrites.
l’entier en paramètre permet de préciser la taille du buffer. Il doit être positif
BufferedWriter(Writer, int)
sinon une exception IllegalArgumentException est levée.
Il existe plusieurs méthodes de la classe BufferedWriter héritées de la classe Writer qui permettent de lire un ou plusieurs caractères dans le flux.
La classe BufferedWriter possède plusieurs méthodes pour gérer le flux :
|
Méthode |
Rôle |
|
flush() |
vide le tampon en écrivant les données dans le flux. |
|
newLine() |
écrire un séparateur de ligne dans le flux |
Une fois les traitements sur le flux terminés, il faut libérer les ressources qui lui sont allouées en utilisant la méthode close().
2.3.4.3. La classe PrintWriter
Cette classe permet d’écrire dans un flux des données formatées.
Cette classe possède plusieurs constructeurs :
|
Constructeur |
Rôle |
|
PrintWriter(Writer) |
Le paramètre fourni précise le flux. Le tampon est automatiquement vidé. |
|
PrintWriter(Writer, boolean) |
Le booléen permet de préciser si le tampon doit être automatiquement vidé |
|
PrintWriter(OutputStream) |
Le paramètre fourni précise le flux. Le tampon est automatiquement vidé. |
|
PrintWriter(OutputStream, boolean) |
Le booléen permet de préciser si le tampon doit être automatiquement vidé |
Il existe de nombreuses méthodes de la classe PrintWriter qui permettent d’écrire un ou plusieurs caractères dans le flux en les formatant. Les méthodes write() sont héritées de la classe Writer. Elle définit plusieurs méthodes pour envoyer des données formatées dans le flux :
- print( … )
Plusieurs méthodes print acceptent des données de différents types pour les convertir en caractères et les écrire dans le flux
- println()
Cette méthode permet de terminer la ligne courante dans le flux en y écrivant un saut de ligne.
- println ( … )
Plusieurs méthodes println acceptent des données de différents types pour les convertir en caractères et les écrire dans le flux avec une fin de ligne.
La classe PrintWriter possède plusieurs méthodes pour gérer le flux :
|
Méthode |
Rôle |
|
flush() |
Vide le tampon en écrivant les données dans le flux. |
2.4. Les flux d’octets
Ils transportent des données sous forme d’octets. Les flux de ce type sont capables de traiter toutes les données.
Les classes qui gèrent les flux d’octets héritent d’une des deux classes abstraites InputStream ou OutputStream. Il existe de nombreuses sous classes pour traiter les flux d’octets.

2.4.1. Les flux d’octets avec un fichier.
Les classes FileInputStream et FileOutputStream permettent de gérer des flux d’octets avec des fichiers.
2.4.1.1. Les flux d’octets en lecture sur un fichier
Il faut instancier un objet de la classe FileInputStream. Cette classe possède plusieurs constructeurs qui peuvent tous lever l’exception FileNotFoundException:
|
Constructeur |
Rôle |
|
FileInputStream(String) |
Ouvre un flux en lecture sur le fichier dont le nom est donné en paramètre |
|
FileInputStream(File) |
Idem mais le fichier est précisé avec un objet de type File |
Il existe plusieurs méthodes de la classe FileInputStream qui permettent de lire un ou plusieurs octets dans le flux. Toutes ces méthodes peuvent lever l’exception IOException.
- int read()
Cette méthode envoie la valeur de l’octet lu ou −1 si la fin du flux est atteinte.
- int read(byte[], int, int)
Cette méthode lit plusieurs octets. Elle attend en paramètre : un tableau d’octets qui contiendra les octets lus, l’indice du premier éléments du tableau qui recevra le premier octet et le nombre d’octets à lire.
Elle renvoie le nombre d’octets lus ou −1 si aucun octet n’a été lus. La tableau d’octets contient les octets lus.
La classe FileInputStream possède plusieurs méthodes pour gérer le flux :
|
Méthode |
Rôle |
|
|
long skip(long) |
saute autant d’octets dans le flux que la valeur fournie en paramètre. Elle |
|
|
renvoie le nombre d’octets sautés. |
||
|
close() |
ferme le flux et libère les ressources qui lui étaient associées |
|
|
int available() |
retourne le nombre d’octets qu’il est encore possible de lire dans le flux |
|
Une fois les traitements sur le flux terminés, il faut libérer les ressources qui lui sont allouées en utilisant la méthode close().
…………………………………………………………………………………………………………………………………………………………………Telecharger le document pour lire le cours complet